W praktyce chrome xpath oznacza szybkie sprawdzanie i dopracowywanie wyrażeń XPath w Chrome, zanim trafią do testów automatycznych. To ważne, gdy interfejs jest dynamiczny, klasy bywają generowane losowo, a selektor musi wskazać dokładnie ten jeden element, nie tylko podobny. Poniżej pokazuję, jak testować XPath w DevTools, jak pisać odporne locatory i kiedy lepiej wybrać CSS zamiast XPath.
Najważniejsze rzeczy, które warto zapamiętać
- Chrome DevTools pozwala testować XPath przez wbudowane `$x(path [, startNode])`.
- Najlepsze selektory opierają się na stabilnych atrybutach, tekście i relacjach w DOM, a nie na długiej, sztywnej ścieżce.
-
normalize-space()i.są często praktyczniejsze niżtext(), zwłaszcza przy zagnieżdżonych elementach. - XPath jest mocny tam, gdzie trzeba przejść po drzewie DOM względnie, a CSS zwykle wygrywa prostotą w prostych przypadkach.
- W testach automatycznych najważniejsza jest odporność locatora, nie jego „spryt”.
Dlaczego XPath nadal ma sens w testach automatycznych
XPath nie jest narzędziem do każdego zadania, ale w automatyzacji testów nadal ma bardzo konkretne zastosowania. Daje mi więcej swobody niż prosty selektor CSS, gdy chcę wskazać element po tekście, wejść do rodzica, przejść do rodzeństwa albo zawęzić wyszukiwanie do konkretnego fragmentu formularza. W praktyce to właśnie precyzja relacji w DOM często ratuje test, kiedy klasy są niestabilne, a identyfikatory zmieniają się po każdym deployu.Warto też pamiętać, że w Chrome konsola udostępnia helper $x(), a sam mechanizm opiera się na standardowych możliwościach przeglądarki. Dzięki temu ta sama logika selektora przydaje się zarówno podczas ręcznego debugowania w DevTools, jak i później w kodzie testu. Ja zwykle traktuję Chrome jako miejsce, w którym selektor najpierw „musi przejść próbę życia”, a dopiero potem trafia do repozytorium. Zanim jednak przejdę do pisania bardziej odpornej wersji, sprawdzam ją bezpośrednio w narzędziach przeglądarki.
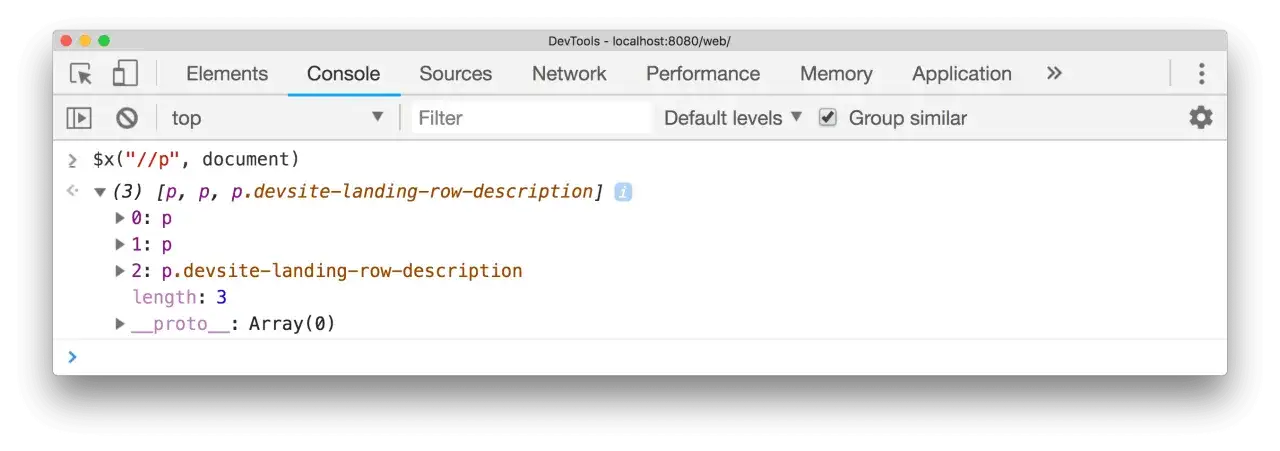 `, w tym jeden z klasą `devsite-landing-row-description`.">
`, w tym jeden z klasą `devsite-landing-row-description`.">
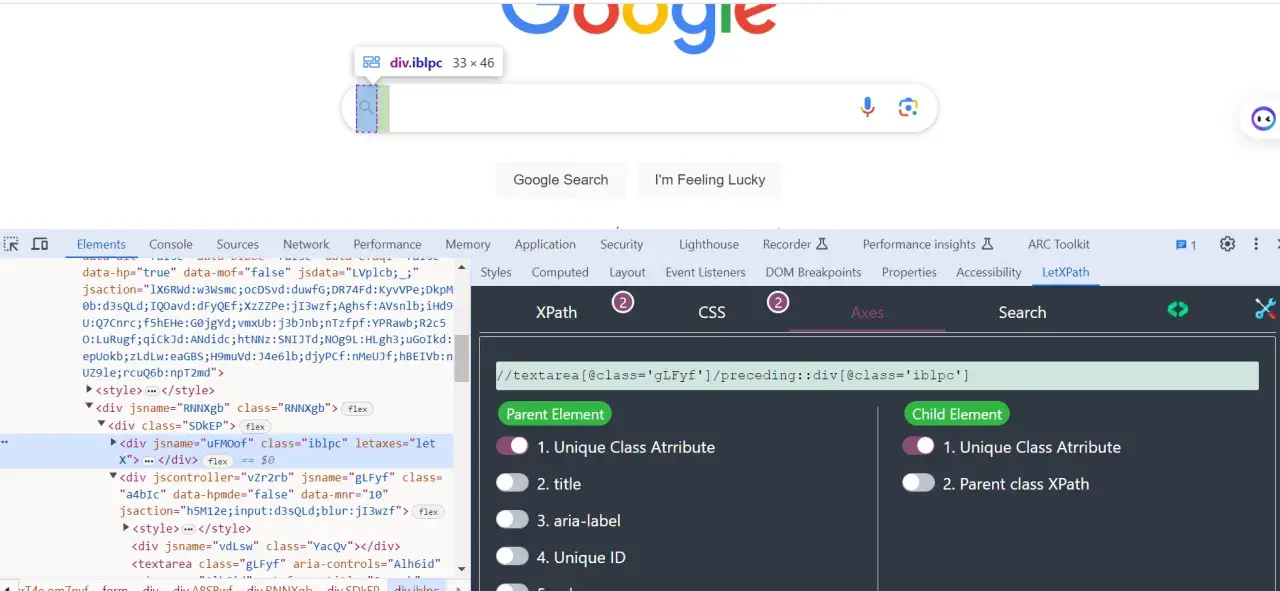
Jak sprawdzić selektor w Chrome bez zgadywania
Najprostszy sposób to użycie konsoli DevTools. Wystarczy otworzyć stronę, wejść do zakładki Console i wpisać wyrażenie XPath przez $x(). Funkcja zwraca tablicę dopasowanych elementów, więc od razu widzę, czy selektor trafia w jeden konkretny węzeł, czy w kilka podobnych.
- Otwórz DevTools i przejdź do Console.
- Wpisz prosty test, na przykład
$x("//button"). - Zawężaj wynik po tekście, atrybucie albo relacji, aż dostaniesz dokładnie jeden element.
- Jeśli chcesz szukać wewnątrz zaznaczonego kontenera, wybierz element w panelu Elements i użyj
$x(".//button", $0). - Gdy wynik jest pusty, sprawdź najpierw spacje, wielkość liter, ukryte elementy i lokalizację tekstu w DOM.
$x("//button[normalize-space()='Zaloguj']")
$x("//input[@name='email']")
$x(".//button", $0)Ja najczęściej zaczynam od szerszego selektora, a potem go zawężam. To szybsze niż zgadywanie na ślepo, bo od razu widzę, czy problem leży w tekście, atrybucie czy w samej strukturze strony. Jeśli selektor zwraca kilka elementów, nie traktuję tego jeszcze jako porażki - to sygnał, że trzeba doprecyzować intencję. Kiedy już wiem, jak sprawdzić XPath w Chrome, najważniejsze staje się to, jak go napisać, żeby nie rozsypał się po kolejnej zmianie UI.
Jak pisać selektory odporne na zmiany interfejsu
W testach automatycznych nie chodzi o to, żeby XPath był możliwie najbardziej złożony. Chodzi o to, żeby był możliwie najbardziej stabilny. Jeśli selektor ma przetrwać redesign, zmiany klas i drobne poprawki layoutu, warto układać go według prostego porządku: stabilny atrybut, dopiero potem tekst, a na końcu relacje w DOM.Zaczynaj od stabilnych atrybutów
Jeżeli aplikacja udostępnia data-testid, name, id albo semantyczne atrybuty typu aria-label, korzystam z nich w pierwszej kolejności. To najczystsza forma selekcji, bo nie zależy od układu graficznego ani od języka interfejsu.
//button[@data-testid='save-settings']
//input[@name='email']
//button[@aria-label='Zamknij']Uważam też na klasy CSS. Samo contains(@class, 'btn') bywa zdradliwe, bo może złapać zarówno btn, jak i btn-primary czy icon-btn. Jeśli już muszę oprzeć się na klasie, wolę token-safe pattern: contains(concat(' ', normalize-space(@class), ' '), ' btn-primary '). To drobny detal, ale w stabilności testów robi dużą różnicę.
Używaj tekstu, ale świadomie
Widoczny tekst jest wygodny, bo często dokładnie odpowiada temu, co widzi użytkownik. Problem zaczyna się wtedy, gdy tekst jest zagnieżdżony w kilku elementach, zawiera dodatkowe spacje albo jest tłumaczony na różne języki. Dlatego zamiast text() częściej wybieram . i normalize-space().
//button[normalize-space(.)='Zapisz']
//a[contains(normalize-space(.), 'Szczegóły')]text() zwraca tylko bezpośredni węzeł tekstowy, więc przy bardziej rozbudowanym HTML potrafi nie zadziałać mimo tego, że na stronie tekst jest widoczny. . obejmuje tekst elementu razem z jego potomkami, więc jest zwykle bezpieczniejszy przy nowoczesnych komponentach. Jeśli interfejs jest wielojęzyczny, tekst traktuję jako wygodny skrót, nie jako jedyne źródło prawdy.
Przeczytaj również: Flaky testy Selenium? Opanuj waits i synchronizację!
Sięgaj po relacje, gdy struktura jest przewidywalna
XPath wygrywa wtedy, gdy chcę dojść do elementu przez jego otoczenie. To szczególnie przydatne w formularzach, tabelach i kartach produktów, gdzie etykieta i pole są ze sobą powiązane logicznie, ale niekoniecznie znajdują się obok siebie w prosty sposób.
//label[normalize-space()='Hasło']/following-sibling::input[1]
//form[.//label[normalize-space()='Adres e-mail']]//input[@type='email']
//div[contains(@class, 'card')]//a[normalize-space()='Szczegóły']Takie selektory są zwykle lepsze niż długa, sztywna ścieżka typu /html/body/div[2]/div[1]/..., bo mniej zależą od kosmetycznych zmian layoutu. W praktyce wolę odnosić się do intencji użytkownika i logiki komponentu niż do dokładnego układu HTML. To prowadzi naturalnie do pytania, kiedy lepiej zostać przy XPath, a kiedy zwykły CSS będzie po prostu rozsądniejszy.
XPath czy CSS w testach automatycznych
Nie traktuję tego jako walki dwóch obozów. W większości projektów najlepszy wybór zależy od konkretnego elementu, a nie od ideologii. CSS jest krótszy i zwykle bardziej czytelny, ale XPath daje mi większą elastyczność tam, gdzie trzeba pracować po tekście, relacjach i kierunku przeciwnym do drzewa DOM.
| Sytuacja | Lepszy wybór | Dlaczego |
|---|---|---|
Prosty element po id, class lub data-testid
|
CSS | Jest krótszy, czytelniejszy i zwykle wystarcza bez dodatkowej logiki. |
| Przycisk, link lub etykieta identyfikowana po tekście | XPath | Łatwo filtruję po widocznym napisie i normalizuję spacje. |
| Trzeba znaleźć pole na podstawie etykiety albo sąsiedniego elementu | XPath | Osi typu ancestor:: i following-sibling:: dają większą kontrolę. |
| Interfejs ma stabilne klasy, ale prosty układ | CSS | Selektor jest prostszy w utrzymaniu i szybciej go zrozumie inny tester. |
| Komponent ma dynamiczne klasy, ale przewidywalne teksty i atrybuty | XPath | Łatwiej odseparować to, co stałe, od tego, co generowane przez framework. |
W praktyce często wygrywa nie samo narzędzie, tylko to, czy selektor jest czytelny po trzech miesiącach. Jeśli po zmianie interfejsu tester musi go rozgryzać od nowa, to nawet „sprytny” XPath nie spełnia swojej roli. I właśnie dlatego warto znać też typowe pułapki, bo to one najczęściej psują stabilność całego zestawu testów.
Najczęstsze błędy, które psują selektory
Najbardziej kruche testy zwykle nie przegrywają z XPath jako takim, tylko z jego złym użyciem. Widzę to regularnie: ktoś buduje selektor tak, jakby HTML był statyczny, a potem dziwi się, że po małej zmianie komponentu wszystko się sypie. Poniżej najczęstsze błędy, które naprawdę warto wyeliminować na starcie.
| Błąd | Co się psuje | Lepsze rozwiązanie |
|---|---|---|
Sztywna ścieżka /html/body/div[2]/...
|
Każda zmiana layoutu albo dodatkowy wrapper rozwala locator. | Użyj selektora względnego z atrybutem, tekstem lub kontekstem komponentu. |
Oparcie o indeksy typu [3] w dynamicznych listach |
Po sortowaniu albo filtrze test trafia w inny element. | Wyszukuj po treści, identyfikatorze lub relacji z elementem nadrzędnym. |
text() przy elementach zagnieżdżonych w spanach i ikonach |
Selektor nie znajduje nic albo znajduje nie to, co trzeba. | Stosuj normalize-space(.) albo zawężaj po atrybucie. |
contains(@class, 'btn') bez doprecyzowania |
Łapie za dużo elementów, bo dopasowanie jest częściowe. | Użyj token-safe sprawdzenia klasy albo stabilnego atrybutu. |
| Tekst zależny od wersji językowej | Test działa tylko na jednym locale. | Jeśli to możliwe, oprzyj się na data-testid lub semantycznym atrybucie. |
Największy błąd, jaki widzę w zespołach, to przekonanie, że „bardziej skomplikowane” znaczy „lepsze”. W testach automatycznych jest odwrotnie: im mniej przypadkowych zależności, tym lepiej. Kiedy selektor jest prosty, ma wyraźny kontekst i da się go przeczytać bez śledzenia całego DOM-u, szansa na stabilny test rośnie bardzo wyraźnie. Z tego powodu w codziennej pracy warto ustalić kilka zasad, które oszczędzą później mnóstwo czasu.
Co wdrożyłbym od razu w zespole testowym
Gdybym miał uporządkować pracę z locatorami w zespole QA, zacząłbym od kilku prostych reguł. Po pierwsze, dla kluczowych akcji wprowadziłbym stabilne atrybuty, najlepiej data-testid albo semantyczne odpowiedniki. Po drugie, każdy nowy selektor testowałbym najpierw w Chrome DevTools, zanim trafi do kodu. Po trzecie, przy review patrzyłbym na locator tak samo krytycznie jak na asercję - bo kruchy selektor potrafi unieważnić dobry test.
- Najpierw wybieram atrybut, dopiero później tekst, a strukturę zostawiam na końcu.
- Unikam długich ścieżek absolutnych, chyba że służą tylko do diagnozy problemu.
- Używam XPath tam, gdzie potrzebuję relacji i tekstu, a CSS tam, gdzie wystarcza prosty, stabilny wybór.
- Dbam o to, żeby selektor dało się zrozumieć bez analizowania całej strony.
Jeśli mam sprowadzić temat do jednego zdania, to XPath w Chrome jest narzędziem do precyzji, ale tylko wtedy, gdy nie próbuję nim zastąpić wszystkiego. W automatyzacji testów wygrywa ten locator, który jest prosty, stabilny i czytelny dla człowieka, a nie ten, który wygląda najbardziej efektownie.