
Testy integracyjne są potrzebne wtedy, gdy sam kod działa poprawnie w izolacji, ale całość potrafi zawieść na styku modułów, baz danych, kolejek czy zewnętrznych API. To właśnie ten poziom testów pokazuje, czy system naprawdę składa się w działającą usługę, a nie tylko wygląda dobrze w pojedynczych klasach. Poniżej rozkładam temat na praktyczne części: co sprawdzać, jak dobierać strategię, jak uniknąć kruchych testów i kiedy lepiej oddać ciężar sprawdzania innym metodom.
Najważniejsze rzeczy, które warto wiedzieć o integracji komponentów
- Ten poziom testów sprawdza współpracę modułów, a nie każdą gałąź logiki biznesowej.
- Najwięcej wartości daje tam, gdzie system dotyka bazy danych, kolejki, plików lub usług zewnętrznych.
- Najlepsze zestawy są małe, celowe i oparte na realnych zależnościach tam, gdzie to ma sens.
- Ważniejsze od liczby przypadków są poprawne granice, przewidywalne dane testowe i szybki feedback w CI.
- Jeśli test zaczyna sprawdzać implementację zamiast współpracy komponentów, zwykle trzeba go uprościć.
Co naprawdę sprawdzają testy na granicy komponentów
W terminologii ISTQB chodzi o poziom testów skupiony na interakcjach między komponentami lub systemami. Ja traktuję go jako filtr na problemy, których test jednostkowy zwykle nie zobaczy: złą serializację, rozjechany kontrakt API, błędny mapping pól, problemy z transakcją albo reakcję na timeout z zewnętrznej usługi.
Microsoft Learn podkreśla, że taki test używa rzeczywistych komponentów aplikacji, przez co jest wolniejszy i cięższy od jednostkowego. To dobra wskazówka redakcyjna i inżynierska zarazem: nie warto dublować całej logiki, tylko skupić się na miejscach, gdzie integracja może się naprawdę wysypać.
| Poziom testu | Co sprawdza | Kiedy jest najmocniejszy | Główne ryzyko |
|---|---|---|---|
| Jednostkowy | Izolowaną logikę jednej klasy lub funkcji | Gdy chcesz szybko znaleźć błąd w obliczeniach, warunkach i regułach biznesowych | Nie wyłapie problemów na styku z infrastrukturą |
| Integracyjny | Współpracę kilku elementów, np. serwisu z bazą albo API z kolejką | Gdy zależy ci na poprawnym przepływie danych przez granice systemu | Może być wolniejszy i bardziej kruchy niż unit test |
| Systemowy | Działanie większego fragmentu aplikacji jako całości | Gdy chcesz potwierdzić cały proces biznesowy od początku do końca | Trudniej zdiagnozować przyczynę błędu |
Najlepszy wniosek z tego porównania jest prosty: jeśli coś da się sensownie sprawdzić na niższym poziomie, nie ma sensu przepychać tego wyżej. Kiedy ten podział jest już jasny, można przejść do pytania, gdzie taki test daje największy zwrot z inwestycji czasowej.
Gdzie ten poziom testów daje największą wartość
Ja zwykle zaczynam od miejsc, w których awaria kosztuje najwięcej albo najtrudniej ją odtworzyć ręcznie. To nie jest sztuka pisania dużej liczby przypadków, tylko trafienie w te przepływy, które realnie łączą różne warstwy systemu.
- Operacje na danych - zapis, odczyt, aktualizacja i usuwanie w bazie to klasyczny obszar, w którym błędy schematu, transakcji lub mapowania wychodzą dopiero przy realnym połączeniu.
- Publikacja i konsumpcja zdarzeń - jeśli aplikacja wysyła komunikat do brokera albo reaguje na event, test powinien sprawdzić nie tylko treść wiadomości, ale też to, czy przepływ kończy się w oczekiwanym stanie.
- Integracje z usługami zewnętrznymi - płatności, wysyłka maili, identity provider czy webhooki to obszary, w których kontrakt i obsługa błędów są ważniejsze niż sama lokalna logika.
- Importy i eksporty - pliki CSV, JSON, XML albo arkusze potrafią ujawnić problemy z kodowaniem, formatem, strukturą i mapowaniem pól.
- Granice bezpieczeństwa - autoryzacja, sesje, tokeny i role użytkowników wymagają sprawdzenia, czy system nie tylko odrzuca złe żądania, ale też prawidłowo przepuszcza poprawne.
Jeżeli dany przepływ można zepsuć jednym błędem konfiguracji albo zmianą po stronie partnera, to właśnie tam chętnie inwestuję czas. Następny krok to wybór sposobu, w jaki te granice będę integrować i obserwować.
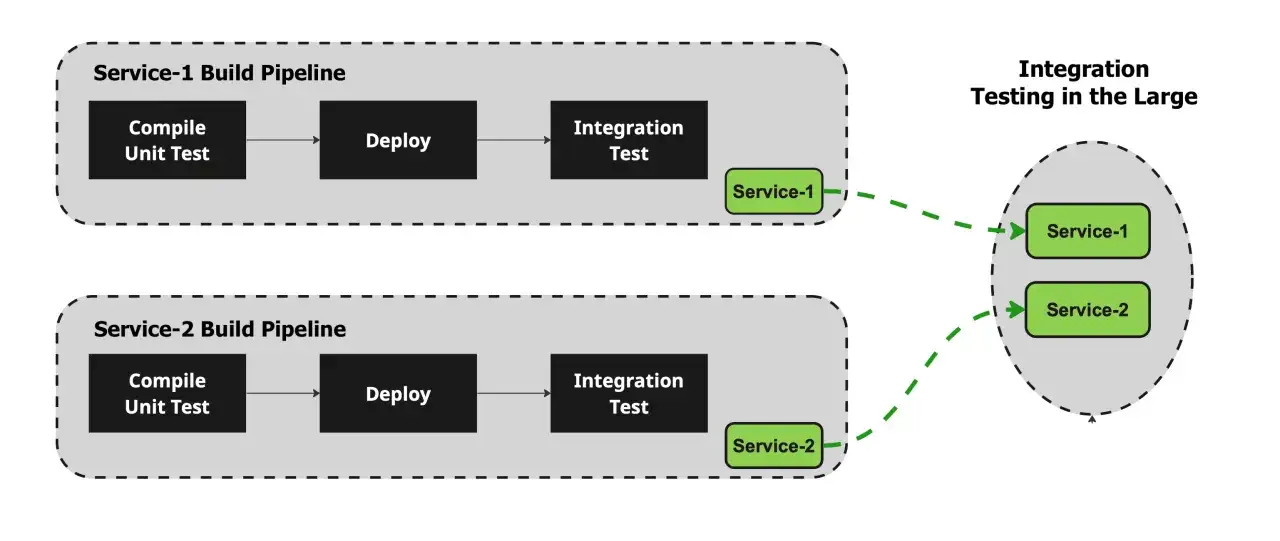
Która strategia integracji pasuje do twojego systemu
W praktyce nie chodzi o wybranie „najlepszej teorii”, tylko o dopasowanie sposobu testowania do architektury i kolejności gotowości komponentów. W prostych projektach wygrywa pragmatyzm, a w rozproszonych usługach dochodzi jeszcze potrzeba dobrej izolacji i kontroli nad zależnościami.
| Strategia | Jak działa | Mocna strona | Słaba strona | Kiedy ma sens |
|---|---|---|---|---|
| Top-down | Zaczynasz od wyższych warstw, a niższe zastępujesz atrapami | Szybko widzisz zachowanie głównych przepływów | Niższe warstwy mogą być testowane później niż byś chciał | Gdy logika biznesowa jest ważniejsza na starcie niż infrastruktura |
| Bottom-up | Najpierw sprawdzasz warstwy techniczne, potem łączysz je wyżej | Dobrze wyłapuje problemy w dostępie do danych i usługach pomocniczych | Na początku mało widać z perspektywy użytkownika | Gdy fundamentem jest silna warstwa techniczna lub dane |
| Sandwich | Łączysz dwa podejścia naraz, testując z góry i z dołu | Daje dobrą równowagę między szerokością a kontrolą | Bywa trudniejsza organizacyjnie | W większych systemach, gdzie wiele zespołów pracuje równolegle |
| Big bang | Składasz wszystko naraz i testujesz dopiero pełną całość | Jest prosta organizacyjnie | Trudno znaleźć źródło błędu, gdy coś się psuje | Rzadko, raczej tylko przy małych zmianach lub bardzo prostych układach |
W architekturach mikroserwisowych często dokładam testy kontraktowe, bo szybciej pokazują zmianę w API niż pełne odpalanie całego stosu. To nie zastępuje testów na styku systemów, ale dobrze je odciąża i skraca czas diagnozy. Skoro wiesz już, jak można podejść do integracji, czas przełożyć to na konkretne kroki.
Jak ja planuję takie testy krok po kroku
Najlepsze wyniki daje mi podejście bardzo przyziemne: najpierw granice, potem dane, a dopiero później kolejne przypadki. Jeśli od razu próbuję „przetestować wszystko”, dostaję długi zestaw, który jest trudny do utrzymania i prawie nic nie mówi o jakości projektu.
- Wyznacz granicę systemu - decyduję, które komponenty muszą działać naprawdę, a które mogą być zastąpione prostym stubem albo lokalnym odpowiednikiem.
- Ustal dane startowe - przygotowuję minimalny zestaw danych, który pozwala odtworzyć scenariusz bez ręcznego klikania przed każdym uruchomieniem.
- Wybierz najcenniejsze przepływy - zaczynam od happy path, a potem dokładam tylko te błędy, które w praktyce mogą zatrzymać proces biznesowy.
- Sprawdzaj efekt, nie implementację - interesuje mnie stan w bazie, wysłane zdarzenie, odpowiedź API albo zapisany plik, a nie to, jak dana metoda została zbudowana.
- Zadbaj o czyszczenie po teście - bez tego kolejny przypadek dziedziczy stan po poprzednim i zaczyna kłamać.
- Uruchamiaj wszystko w CI - lokalny sukces nie ma dużej wartości, jeśli pipeline potrafi pokazać inny wynik przy tym samym kodzie.
W praktyce wolę kilka dobrze opisanych scenariuszy niż rozbudowaną encyklopedię przypadków. Dla warstwy danych często wystarcza sensownie dobrany zestaw operacji: odczyt, zapis, aktualizacja i usunięcie, bo to one najczęściej ujawniają realne problemy. Z takim szkieletem łatwiej potem uniknąć typowych pułapek.
Najczęstsze pułapki, które psują wyniki
Największy problem zaczyna się wtedy, gdy zespół myli „więcej testów” z „lepszą pewnością”. W integracji to bardzo zdradliwe, bo nadmiar przypadków często zwiększa koszt utrzymania szybciej niż wartość informacyjną.
- Za dużo na raz - jeśli test obejmuje pół systemu, po awarii trudno wskazać źródło problemu.
- Nadmierne mockowanie - gdy wszystko jest atrapą, nie sprawdzasz już integracji, tylko własne założenia o niej.
- Współdzielone środowisko - jedna baza używana przez wiele uruchomień prawie gwarantuje losowe błędy i zanieczyszczenie danych.
- Zbyt szczegółowe asercje - test, który kontroluje każde pole i każdy krok pośredni, zwykle pęka przy najmniejszej zmianie refaktoryzacyjnej.
- Brak granicy między poziomami - logika biznesowa testowana wyłącznie integracyjnie marnuje czas, który lepiej zainwestować w testy jednostkowe.
- Pomijanie błędów - sprawdzanie tylko happy path daje złudne poczucie bezpieczeństwa; prawdziwe awarie często siedzą w timeoutach, walidacji i konflikcie danych.
Jeżeli któryś z tych punktów brzmi znajomo, zwykle nie trzeba przepisywać całej strategii. Wystarczy odchudzić przypadki, poprawić izolację i przenieść część odpowiedzialności niżej. Na końcu liczy się też to, czy środowisko testowe pomaga, czy tylko przeszkadza.
Narzędzia i środowisko, które naprawdę pomagają
Ja najczęściej wybieram rozwiązania, które dają jak najwięcej realizmu przy jak najmniejszym koszcie konfiguracji. W praktyce dobrze sprawdzają się kontenerowe bazy, lokalne serwery testowe i proste stuby dla usług, na które nie mam wpływu.
| Problem | Co zwykle pomaga | Dlaczego to działa |
|---|---|---|
| Flaky testy przez współdzieloną bazę | Izolowany kontener albo osobna instancja na uruchomienie | Każdy przypadek zaczyna z przewidywalnym stanem |
| Trudny start zależności | Testowy host, fixture albo fabryka środowiska | Konfiguracja jest powtarzalna i łatwa do odtworzenia lokalnie |
| Zewnętrzna usługa zmienia się zbyt często | Stub, sandbox albo test kontraktowy | Redukujesz hałas bez utraty kontroli nad formatem danych |
| Potrzeba prawdziwej bazy lub brokera | Testcontainers | Uruchamiasz zależność podobną do produkcyjnej, ale tylko na czas testu |
| Wysoka złożoność interfejsu użytkownika | Testy aplikacyjne lub automatyzacja przeglądarki | Możesz sprawdzić pełny przepływ bez ręcznego klikania |
W tym miejscu często widać różnicę między zespołem, który naprawdę testuje integrację, a zespołem, który tylko ją symuluje. Dobre środowisko nie musi być skomplikowane, ale musi być przewidywalne, powtarzalne i możliwe do uruchomienia przez każdego członka zespołu oraz w pipeline. Ostatni krok to odpowiedź na pytanie, kiedy powiedzieć sobie „to już wystarczy”.
Kiedy zakres jest już wystarczający
Nie ma sensu udawać, że można pokryć każdą kombinację. Ja uznaję zakres za zdrowy wtedy, gdy kilka warunków jest spełnionych jednocześnie.
- Najważniejsze styki systemu są pokryte, szczególnie tam, gdzie w grę wchodzą dane, zdarzenia i usługi zewnętrzne.
- Każdy krytyczny przepływ ma sprawdzony happy path oraz przynajmniej jeden ważny scenariusz błędu.
- Zestaw uruchamia się automatycznie i nie wymaga ręcznej konfiguracji przed każdym testem.
- Czas wykonania jest na tyle rozsądny, że zespół nie zaczyna omijać testów z frustracji.
- Logika biznesowa wciąż pozostaje głównie po stronie szybkich testów jednostkowych.
Jeśli miałbym zostawić jedną praktyczną zasadę, to tę: testuj prawdziwe granice, ale tylko tam, gdzie granica ma znaczenie. Resztę oddaj testom jednostkowym albo poziomowi systemowemu, a dostaniesz zestaw, który nie tylko wykrywa błędy, ale też daje zespołowi tempo pracy. Właśnie taki balans najczęściej decyduje o tym, czy integracja jest realnym wsparciem jakości, czy tylko kolejnym ciężkim folderem w repozytorium.