Automatyzacja dostarczania oprogramowania ma sens tylko wtedy, gdy nie obniża jakości. Dobrze ułożony proces CI/CD łączy integrację kodu, testy QA, kontrolę ryzyka i bezpieczne wdrożenia, dzięki czemu zespół szybciej wypuszcza zmiany, a błędy wychwytuje wcześniej. W tym tekście pokazuję, jak to działa w praktyce, jak wpiąć QA w cały przepływ i które decyzje naprawdę robią różnicę.
Najważniejsze informacje o CI/CD i QA w jednym miejscu
- CI oznacza częste łączenie zmian w jednej gałęzi i automatyczne uruchamianie buildów oraz testów.
- CD to automatyczne przygotowanie i dostarczanie zmian do kolejnych środowisk, a nie tylko samo wdrożenie.
- W QA najważniejsze jest ustawienie sensownych bramek jakości, a nie dokładanie kolejnych testów bez planu.
- Najszybszą wartość dają testy jednostkowe, integracyjne, kontraktowe i smoke, a dopiero potem ciężkie E2E.
- Dobry pipeline powinien dawać szybki feedback, stabilne dane testowe i jasną odpowiedzialność za każdy etap.
- Najlepsze metryki to czas feedbacku, liczba nieudanych wdrożeń, MTTR i odsetek niestabilnych testów.
Co naprawdę oznacza CI/CD w procesach QA
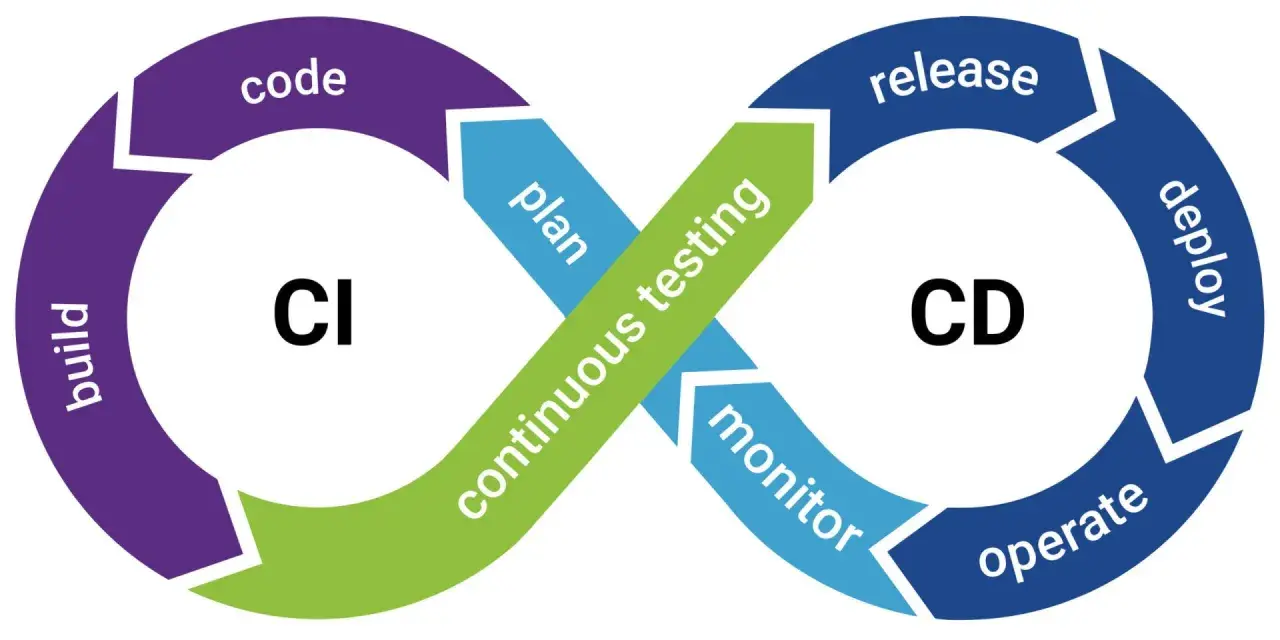
W praktyce patrzę na CI/CD nie jako na modny skrót, ale jako na sposób zarządzania ryzykiem. Continuous integration oznacza częste łączenie zmian do wspólnej gałęzi, zwykle krótkotrwałej i opartej o main jako źródło prawdy, a potem automatyczne budowanie i testowanie kodu. Continuous delivery idzie krok dalej: po przejściu testów zmiana jest gotowa do wdrożenia, ale ostatni krok może nadal wymagać akceptacji człowieka. W continuous deployment ten próg znika, więc produkcja dostaje zmiany automatycznie, jeśli pipeline nie wykryje problemu.
| Model | Co dzieje się po testach | Rola QA | Gdzie ma sens |
|---|---|---|---|
| Continuous delivery | Zmiana jest gotowa do wdrożenia, ale publikacja może czekać na decyzję | Definiuje warunki przejścia i kryteria akceptacji | Gdy ryzyko biznesowe jest wyższe albo potrzebna jest kontrola release’u |
| Continuous deployment | Zmiana trafia na produkcję bez ręcznej bramki | Buduje bardzo mocne testy, monitoring i rollback | Gdy system jest dojrzały, a zespół ma wysoką automatyzację i obserwowalność |
To ważne rozróżnienie, bo QA w takim układzie nie jest już końcową „stacją kontroli”. QA staje się częścią projektu od początku: pomaga ustalić, co testujemy automatycznie, co sprawdzamy ręcznie, gdzie potrzebujemy danych testowych i które ryzyka są na tyle duże, że muszą mieć własną bramkę jakości. Z tego miejsca bardzo naturalnie przechodzimy do samego pipeline’u.
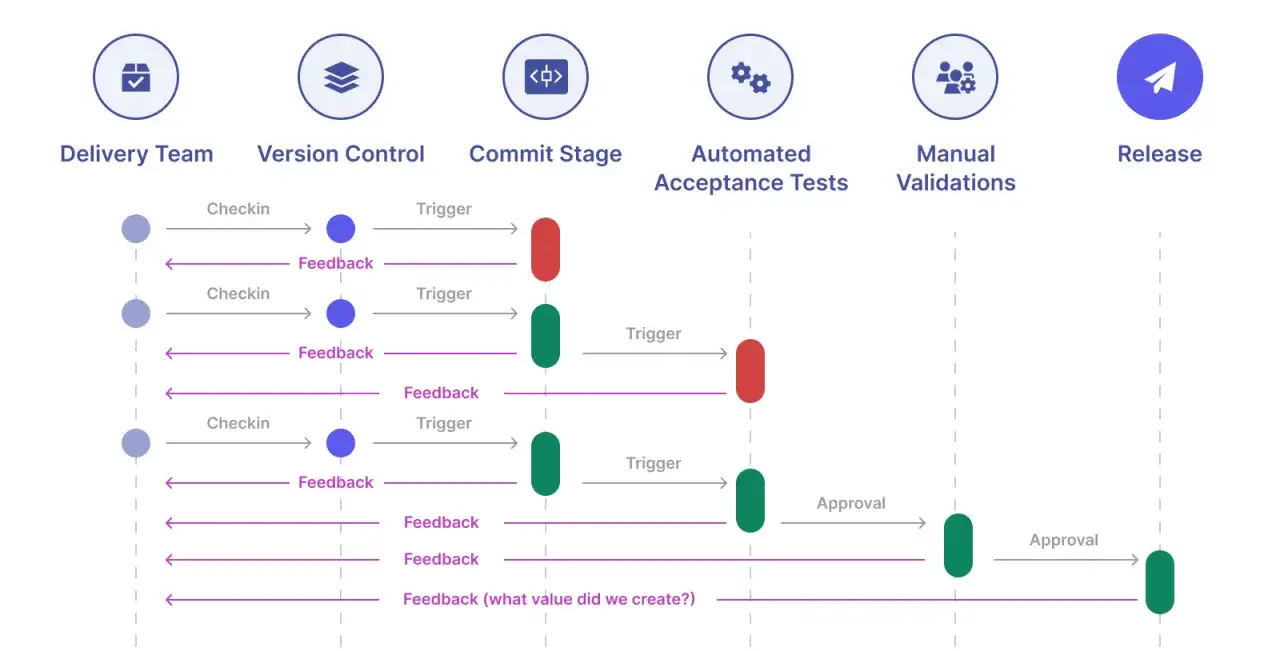
Jak wygląda pipeline, który wspiera jakość, a nie tylko tempo
Dobry pipeline nie jest po prostu długi. Jest warstwowy. Najpierw daje szybki sygnał, że coś jest nie tak, a dopiero później uruchamia cięższe testy i wdrożenia. W zespołach, które naprawdę dbają o QA, nie wszystko dzieje się w jednym monolicie testowym, bo wtedy każda drobna awaria spowalnia cały proces.
| Etap | Co sprawdzam | Rola QA | Typowy błąd |
|---|---|---|---|
| Walidacja kodu | Lint, format, type check, podstawowe reguły statyczne | Szybko wyłapuje błędy oczywiste i techniczne długi | Traktowanie tego jako „zbędnego kosmetyku” |
| Testy jednostkowe | Logika biznesowa, funkcje, klasy, obliczenia | Chroni najważniejsze reguły domenowe | Zastępowanie nimi testów integracyjnych |
| Build i pakowanie | Czy artefakt da się zbudować i odtworzyć w sposób powtarzalny | Zapewnia, że „u mnie działa” nie kończy się na lokalnym środowisku | Budowanie bez wersjonowania i bez powtarzalności |
| Testy integracyjne i kontraktowe | Współpracę z API, bazą danych, kolejkami, usługami zewnętrznymi | Weryfikuje granice systemu, gdzie powstaje najwięcej ukrytych błędów | Odpalanie ich dopiero po wdrożeniu na produkcję |
| Staging i smoke | Krytyczne ścieżki użytkownika po złożeniu całego systemu | Potwierdza gotowość release’u na zbliżonym środowisku | Udawanie, że staging jest idealną kopią produkcji |
| Produkcja | Canary, feature flags, monitoring po wdrożeniu | Potwierdza, że zmiana działa w realnym ruchu | Brak planu rollbacku i brak obserwowalności |
Warto też rozdzielić dwa pojęcia, które często się myli: środowisko testowe i środowisko produkcyjne. Staging powinien być podobny do produkcji pod względem konfiguracji i integracji, ale nie musi być jej wierną kopią 1:1. W praktyce znacznie ważniejsze od perfekcyjnej zgodności jest to, czy zespół ma powtarzalny proces, stabilne dane testowe i sensowny sposób sprawdzania zmian przed publikacją. Od tej warstwy zależy, jak ułożyć cały proces QA krok po kroku.
Jak ułożyć proces QA w pipeline krok po kroku
Najczęściej zaczynam od pytania: co ma zatrzymać zmianę, a co tylko ją oznaczyć do obserwacji? To proste rozróżnienie porządkuje cały proces. Jeśli wszystko jest blokadą, pipeline szybko staje się zbyt ciężki. Jeśli nic nie blokuje, QA zamienia się w dekorację.
- Ustal bramki jakości dla każdego etapu. Na początku wystarczy podział na „must pass” i „informacyjne”, zamiast budować rozbudowaną politykę od razu.
- Zdefiniuj krytyczne ścieżki biznesowe. Nie testuj wszystkiego na równi, tylko najpierw to, co generuje największe ryzyko dla użytkownika i przychodu.
- Podziel testy według szybkości. Szybkie testy powinny dawać odpowiedź w minutach, a cięższe zestawy mogą działać później lub nocą.
- Przygotuj dane testowe. Bez kontrolowanych danych nawet dobre testy będą niestabilne, a QA zacznie gasić fałszywe alarmy zamiast wykrywać regresje.
- Ustal politykę dla flaky tests. Test, który raz przechodzi, a raz nie, nie jest neutralny. To techniczny dług, który blokuje decyzje całego zespołu.
- Zwiąż pipeline z definicją gotowości do wydania. Jeśli coś nie ma akceptacji, monitoringu i planu cofnięcia, to nie powinno udawać „gotowego release’u”.
W praktyce dobrze działa prosty rytm: szybka walidacja na początku, szersze testy po buildzie i pełniejsza regresja dopiero wtedy, gdy zmiana przeszła podstawowe bramki. Dzięki temu zespół nie czeka bez sensu na ciężkie scenariusze, które i tak nie powiedzą nic o literówce w regule biznesowej. To prowadzi do kolejnego pytania: które testy w ogóle opłaca się automatyzować jako pierwsze.
Które testy automatyzować w pierwszej kolejności
Nie automatyzowałbym wszystkiego naraz. Z perspektywy QA najlepszy zwrot z inwestycji dają testy, które są częste, powtarzalne i stabilne. Jeżeli coś zależy od wyglądu ekranu, ruchu przeglądarki i dziesięciu warunków środowiskowych, to zwykle nie jest dobry pierwszy kandydat do pełnej automatyzacji.
| Typ testu | Kiedy go używać | Co wykrywa | Jak go traktować |
|---|---|---|---|
| Unit tests | Na każdym commitcie i pull requeście | Błędy logiki, reguły domenowe, niepoprawne obliczenia | To pierwsza linia obrony, powinna być szybka i stabilna |
| Integration tests | Po unitach, przed wdrożeniem do środowisk wyższych | Problemy z bazą, API, kolejkami, zależnościami zewnętrznymi | Warto utrzymywać je blisko realnej architektury |
| Contract tests | Gdy system składa się z wielu usług lub zespołów | Rozjazdy w interfejsach i błędy integracyjne między zespołami | Świetne tam, gdzie jeden zespół nie kontroluje całego stosu |
| Smoke tests | Po deployu na stagingu i przed produkcją | Czy najważniejsze ścieżki w ogóle działają | Powinny być krótkie i bezlitosne, ale tylko dla kluczowych flow |
| E2E tests | Dla kilku najważniejszych scenariuszy użytkownika | Czy cały proces działa od początku do końca | Nie mnożyłbym ich bez kontroli, bo bywają kruche i kosztowne |
| Eksploracyjne testy ręczne | Przy nowych funkcjach, ryzykownych zmianach i ocenie UX | Nieoczywiste problemy, których automatyzacja jeszcze nie obejmuje | Wciąż mają sens, ale nie powinny być jedyną barierą jakości |
Jeśli miałbym wskazać jedną rzecz, którą zespół zwykle źle ocenia, to byłoby to dokładanie zbyt wielu ciężkich testów UI. Tego typu testy są przydatne, ale nie powinny dominować pipeline’u. Lepiej mieć kilka dobrze dobranych ścieżek end-to-end niż dziesiątki powolnych przypadków, które ciągle się psują i zniechęcają do pracy z gałęzią główną. Stąd już tylko krok do najczęstszych błędów, które potrafią zepsuć nawet dobrze zaprojektowany proces.
Najczęstsze błędy, które psują cały proces
Najgorsze pipeline’y zwykle nie są złe dlatego, że brakuje w nich technologii. Są złe, bo brakuje w nich decyzji. Zespół dodaje kolejne warstwy testów, ale nie ustala, co jest naprawdę ważne, gdzie kończy się automatyzacja i kto odpowiada za utrzymanie jakości. Wtedy system zaczyna działać przeciwko ludziom, a nie dla nich.
| Błąd | Skutek | Jak to naprawić |
|---|---|---|
| Zbyt dużo ciężkich E2E na każdy commit | Pipeline robi się wolny, a deweloperzy zaczynają go omijać | Przenieś pełne scenariusze do krótszych, krytycznych zestawów i uruchamiaj resztę rzadziej |
| Brak stabilnych danych testowych | Fałszywe błędy, które maskują realne regresje | Automatyzuj tworzenie i reset danych, zamiast polegać na ręcznym przygotowaniu środowiska |
| Ignorowanie flaky tests | Każde uruchomienie traci wiarygodność | Traktuj niestabilny test jako defekt procesu, nie jako drobnostkę |
| QA na końcu, po „zakończeniu” developmentu | Błędy wychodzą późno i kosztują więcej | Włącz QA już na etapie kryteriów akceptacji i projektu testów |
| Brak rollbacku lub feature flags | Każdy problem na produkcji staje się kryzysem | Przygotuj cofanie zmian i selektywne włączanie funkcji |
| Staging zbyt różny od produkcji | Testy przechodzą, a produkcja i tak się łamie | Ujednolić konfigurację, zależności i sposób uruchamiania usług |
W praktyce widzę też jeden subtelny problem: zespoły często mylą szybkość wdrożeń z jakością procesu. Szybszy release sam w sobie niczego nie gwarantuje, jeśli nie umiesz zmierzyć, ile zmian faktycznie psuje produkcję i jak szybko umiesz się z nich wycofać. To naturalnie prowadzi do metryk, które naprawdę warto śledzić.
Jak mierzyć, czy automatyzacja faktycznie poprawia jakość
Bez metryk CI/CD bardzo łatwo ocenić emocjami. A emocje są zdradliwe: jedno głośne wdrożenie potrafi przykryć trzy miesiące stabilnej pracy albo odwrotnie. Dlatego w QA patrzę nie tylko na to, czy pipeline „działa”, ale czy skraca czas decyzji i zmniejsza ryzyko.
| Metryka | Co mówi o procesie | Na co uważać |
|---|---|---|
| Lead time | Jak szybko zmiana przechodzi od commita do produkcji | Nie myl go z samą szybkością builda, bo obejmuje cały przepływ |
| Deployment frequency | Jak często zespół wypuszcza zmiany | Częściej nie zawsze znaczy lepiej, jeśli rośnie liczba rollbacków |
| Change failure rate | Jaki odsetek wdrożeń powoduje problem na produkcji | To jedna z najuczciwszych miar jakości procesu |
| MTTR | Jak szybko zespół przywraca usługę po awarii | Bez monitoringu i planu cofania ta metryka szybko się psuje |
| Pipeline duration | Jak długo czeka się na feedback po pushu lub PR | Jeśli zwykły MR czeka ponad 15-20 minut, zespół zaczyna tracić rytm pracy |
| Flaky test rate | Jak często testy zawodzą bez realnej przyczyny | Wysoki wynik oznacza, że automatyzacja traci zaufanie użytkowników |
| Escaped defects | Ile błędów przechodzi na produkcję mimo testów | Pokazuje, czy QA faktycznie broni użytkownika, a nie tylko raportuje pokrycie |
Dla praktyki zespołowej trzymam prostą zasadę: szybka pętla zwrotna powinna zamykać się w kilku minutach, a pełniejsza walidacja może trwać dłużej, o ile nie blokuje pracy wszystkich naraz. Jeśli cały pipeline staje się ciężki, nie pomaga ani lepszy monitoring, ani ładniejsza tablica z wynikami. Najpierw trzeba odzyskać tempo decyzji. Z tego punktu najrozsądniej przejść do tego, od czego zacząć, jeśli zespół dopiero porządkuje wydania.
Od czego zacząć, gdy zespół dopiero porządkuje wydania
Jeżeli dziś masz ręczne testy, chaotyczne wdrożenia i niewielką automatyzację, nie próbuj od razu zbudować wszystkiego. Najlepszy postęp zwykle daje prosty, konsekwentny plan. W praktyce zaczynam od tego, co od razu obniża ryzyko i nie zabiera zespołowi tygodni na utrzymanie.
- Najpierw automatyzuję lint, format, build i testy jednostkowe dla najważniejszej logiki.
- Następnie dokładam jeden zestaw testów integracyjnych lub kontraktowych dla kluczowych zależności.
- Potem buduję krótki smoke test dla najważniejszych ścieżek użytkownika.
- Na końcu dopinam monitoring, feature flags i prosty rollback, żeby release był odwracalny.
Tak ułożony proces nie jest efektowny, ale działa. Daje szybki feedback, zmniejsza liczbę ręcznych interwencji i pozwala QA skupić się na ryzyku, a nie na odtwarzaniu tych samych kliknięć po każdym commicie. Jeśli mam wybrać jedną rzecz, która najbardziej poprawia jakość wdrożeń, to właśnie ta: automatyzacja ma wspierać decyzję o gotowości do wydania, a nie tylko przyspieszać ruch kodu. I to jest różnica, którą zespół odczuwa od pierwszych dobrze ustawionych pipeline’ów.