W dobrze prowadzonym procesie QA każdy defekt ma swój porządek: od zgłoszenia, przez triage i naprawę, aż po ponowną weryfikację i zamknięcie. To właśnie ten uporządkowany obieg decyduje, czy zespół testowy działa sprawnie, czy tylko kolekcjonuje zgłoszenia bez jasnego właściciela. W tym artykule pokazuję, jak działa cykl życia błędu, kto odpowiada za poszczególne kroki i jak ułożyć workflow tak, żeby naprawdę pomagał w zarządzaniu testami.
Sedno procesu, który utrzymuje testy w ryzach
- Defekt powinien przejść przez jasne stany: zgłoszenie, triage, przypisanie, naprawę, retest i zamknięcie.
- Najwięcej tarcia powstaje na styku ról, nie w samym kodzie: brak danych w zgłoszeniu, brak właściciela i zbyt szybkie zamknięcie.
- W zarządzaniu testami liczy się nie tylko liczba błędów, ale też czas obsługi, liczba ponownych otwarć i jakość reprodukcji.
- Prosty workflow zwykle działa lepiej niż rozbudowany zestaw wyjątków i nietypowych ścieżek.
- Statusy muszą wynikać z realnej pracy zespołu, a nie z możliwości narzędzia.
Jak rozumieć obieg błędu w praktyce
Na poziomie operacyjnym defekt nie jest po prostu „znalezionym problemem”. To zgłoszenie, które przechodzi przez kolejne decyzje: czy faktycznie mamy do czynienia z usterką, kto bierze za nią odpowiedzialność, jak ją naprawiamy, jak ją sprawdzamy i czy można ją bezpiecznie zamknąć. Właśnie dlatego dobrze zaprojektowany workflow jest częścią jakości, a nie tylko administracją w narzędziu.
Ja patrzę na ten proces jak na kontrolę ruchu. Jeśli każdy wie, co oznacza dany status, kiedy zgłoszenie przechodzi dalej i co musi się wydarzyć przed następnym krokiem, zespół nie traci czasu na domysły. Jeśli tych zasad brakuje, nawet prosty błąd potrafi utknąć na tygodnie, chociaż technicznie już dawno powinien być rozwiązany.
Ważne jest też rozróżnienie między samym defektem a jego obsługą. Jedna rzecz to usterka w produkcie, a druga to sposób, w jaki zespół nią zarządza. To właśnie ten drugi obszar decyduje o tym, czy testy wzmacniają produkt, czy tylko produkują kolejkę zgłoszeń bez końca. Żeby to było użyteczne, trzeba rozbić proces na konkretne etapy.
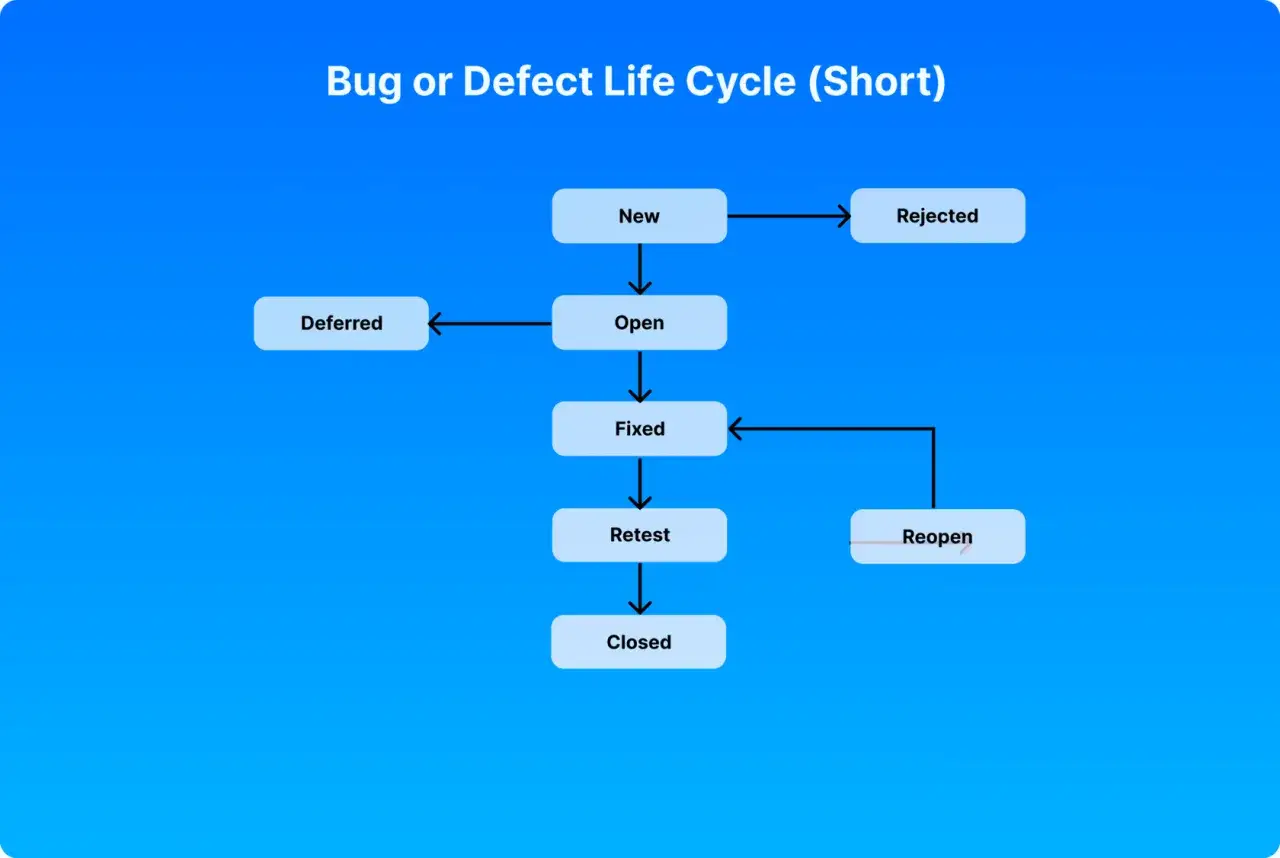
Jakie etapy przechodzi zgłoszenie od znalezienia do zamknięcia
W różnych zespołach nazwy statusów są inne, ale logika zwykle pozostaje podobna. Najczęściej chodzi o to, żeby defekt przeszedł przez zestaw decyzji, a nie po prostu zniknął z tablicy. Poniżej pokazuję praktyczny model, który dobrze sprawdza się w testach funkcjonalnych, regresji i w pracy z Jira lub podobnym narzędziem.
| Etap | Co się dzieje | Na co patrzę jako tester |
|---|---|---|
| Nowy / zgłoszony | Tester opisuje problem i zapisuje go w systemie śledzenia. | Czy są kroki reprodukcji, środowisko, wersja, wynik oczekiwany i rzeczywisty oraz dowody. |
| Triage / analiza | Ktoś sprawdza, czy to realny defekt, duplikat, zmiana wymagania albo błąd danych testowych. | Czy zgłoszenie ma sens biznesowy i techniczny oraz czy da się je odtworzyć. |
| Przypisany | Defekt trafia do konkretnej osoby lub zespołu odpowiedzialnego za naprawę. | Czy właściciel jest jasny i czy zgłoszenie nie krąży między rolami bez decyzji. |
| W trakcie naprawy | Developer analizuje przyczynę i przygotowuje poprawkę. | Czy to naprawa źródła problemu, a nie tylko obejście symptomu. |
| Gotowy do testu | Poprawka jest wdrożona do środowiska testowego lub przygotowana do sprawdzenia. | Czy wersja do weryfikacji jest właściwa i czy nie pomylono buildów. |
| Zweryfikowany | Tester powtarza scenariusz i sprawdza, czy problem zniknął. | Czy naprawa działa w głównym scenariuszu i czy nie zepsuła sąsiednich funkcji. |
| Zamknięty | Zgłoszenie zostaje domknięte, bo poprawka jest potwierdzona. | Czy nie ma ukrytej regresji i czy status zamknięcia naprawdę oznacza koniec pracy. |
| Odrzucony / odroczony / ponownie otwarty | Defekt nie trafia do standardowej ścieżki albo wraca, jeśli problem nadal występuje. | Czy decyzja jest uzasadniona i udokumentowana, a nie podjęta „żeby zamknąć temat”. |
W praktyce największą wartość ma nie sama nazwa statusu, lecz to, jakie decyzje za nią stoją. Dobre narzędzie do zarządzania pracą pokazuje przepływ statusów i przejść, ale nie zastąpi zdrowych reguł zespołu. Jeśli workflow ma sens, tablica odzwierciedla rzeczywisty proces, a nie tylko estetykę raportu. To prowadzi wprost do pytania, kto powinien pilnować każdego z tych kroków.
Kto odpowiada za każdy krok procesu
W dobrym modelu nie ma jednego bohatera odpowiedzialnego za wszystko. Tester inicjuje zgłoszenie i często prowadzi weryfikację, ale to nie on powinien samodzielnie decydować o każdej zmianie stanu. Z kolei developer odpowiada za diagnozę i naprawę, ale nie domyka procesu bez potwierdzenia, że poprawka działa w środowisku testowym.
| Rola | Główna odpowiedzialność | Typowy błąd |
|---|---|---|
| Tester | Opisuje defekt tak, żeby dało się go odtworzyć i sprawdzić po poprawce. | Za ogólny opis, brak środowiska, brak dowodów, brak zakresu wpływu. |
| Test manager / QA lead | Prowadzi triage, pilnuje priorytetów i dba o przepływ zgłoszeń. | Zamykanie zgłoszeń „na szybko” bez pełnej weryfikacji lub bez właściciela. |
| Developer | Analizuje przyczynę, przygotowuje poprawkę i opisuje techniczny kontekst zmiany. | Naprawa objawu zamiast źródła problemu albo brak informacji o wpływie na inne moduły. |
| Product owner / PM | Ocena wpływu na produkt, klienta i termin dostawy. | Mieszanie pilności biznesowej z ciężarem technicznym i wymuszanie chaosu priorytetów. |
| Osoba odpowiedzialna za release | Decyduje, kiedy poprawka może trafić na środowisko docelowe. | Wypuszczanie zmian bez jasnej zależności od testów regresji. |
Tu szczególnie ważne jest rozróżnienie między wpływem błędu a pilnością jego naprawy. Jeden defekt może być technicznie krytyczny, ale biznesowo mało pilny, jeśli występuje w rzadkim scenariuszu. Inny może być kosmetyczny, ale jeśli uderza w kluczowy ekran sprzedażowy, dostaje wysoki priorytet. Właśnie dlatego dobrze prowadzony triage nie polega na szybkim „tak” albo „nie”, tylko na rozsądnej klasyfikacji. Z takiego porządku naturalnie wynika pytanie, co z tego ma samo zarządzanie testami.
Jak zarządzanie testami korzysta z tego workflow
Jeśli prowadzę testy serio, nie patrzę wyłącznie na to, ile błędów odkryto. Interesuje mnie, czy zespół potrafi je szybko i sensownie obsłużyć, czy zgłoszenia wracają do poprawki, czy defekty utykają na etapie analizy i czy konkretne moduły stale generują te same problemy. To właśnie w tych danych widać jakość procesu, a nie w samej liczbie ticketów.
| Wskaźnik | Co mówi o procesie | Co zwykle oznacza problem |
|---|---|---|
| Czas od zgłoszenia do zamknięcia | Pokazuje sprawność całego obiegu defektu. | Brak właściciela, zatory w triage lub długie oczekiwanie na środowisko testowe. |
| Reopen rate | Mówi, jak często poprawka nie przechodzi pierwszej weryfikacji. | Słabe kroki reprodukcji, zła diagnoza albo poprawka dotycząca tylko objawu. |
| Duplicate rate | Wskazuje, czy zespół ma dobrą widoczność zgłoszeń i czy opis defektu jest czytelny. | Brak szablonu, chaos w komunikacji, niejednoznaczne wymagania. |
| Defect leakage | Pokazuje, ile błędów przechodzi dalej niż powinno, na przykład do produkcji. | Za słaba regresja, niewystarczający zakres testów albo zbyt szybkie domykanie tematów. |
| Najczęściej wadliwe moduły | Wskazuje obszary produktu, które wymagają większej uwagi testowej. | Słaba jakość wymagań, złożony kod, brak testów automatycznych lub ryzykowna integracja. |
Ja lubię ten zestaw, bo zmusza do myślenia procesowego. Jeśli reopen rate rośnie, to problemem nie jest „leniwy tester”, tylko najpewniej słabe dane wejściowe, pośpiech przy naprawie albo brak reguły retestu. Jeśli zgłoszenia z jednego modułu wracają częściej, to nie jest przypadek, tylko sygnał, że dany obszar wymaga mocniejszej kontroli jakości. Gdy te wskaźniki są regularnie analizowane, testy zaczynają wspierać decyzje produktowe, a nie tylko raportować chaos. Następny krok to rozpoznanie miejsc, w których proces zwykle się psuje.
Gdzie proces najczęściej się psuje
W mojej praktyce błędy w workflow rzadko wynikają z jednego spektakularnego potknięcia. Zwykle psuje się seria drobnych rzeczy, które razem tworzą bałagan: brak danych w zgłoszeniu, brak odpowiedzialności, zbyt wiele wyjątków i za szybkie zamykanie tematów. To są drobiazgi tylko z pozoru, bo każdy z nich potrafi wydłużyć cały cykl pracy.
- Brak kroków reprodukcji - bez nich developer traci czas na zgadywanie, a tester potem nie potrafi uczciwie potwierdzić poprawki.
- Mylenie severity z priority - zespół zaczyna mówić o tym samym błędzie różnymi językami i traci spójność decyzji.
- Za dużo statusów - workflow staje się administracyjną układanką zamiast narzędziem pracy.
- Zamykanie bez retestu - zgłoszenie znika z tablicy, ale problem wraca w regresji albo w innym scenariuszu.
- Brak właściciela - defekt „krąży” między rolami, a zespół robi wszystko poza faktycznym rozwiązaniem.
- Brak reguły na duplikaty i odrzucenia - każdy przypadek kończy się dyskusją od nowa, zamiast jasnej decyzji i notatki.
Najbardziej kosztowny błąd to zamykanie tematu szybciej, niż zespół zdążył go naprawdę zrozumieć. Oszczędza się pięć minut na triage, a potem traci godziny na ponowne otwieranie, wyjaśnienia i zbieranie dowodów. Właśnie dlatego sensowny proces nie jest „bardziej biurokratyczny” - on po prostu usuwa tarcie z pracy. To naturalnie prowadzi do pytania, jak taki workflow ustawić, żeby pomagał zamiast przeszkadzać.
Jak ułożyć workflow, który nie blokuje zespołu
Jeśli mam doradzić jedną rzecz, to byłaby ona prosta: workflow ma odzwierciedlać realną pracę, a nie ambicję admina. W mniejszych i średnich zespołach lepiej działa krótka ścieżka z czytelnymi decyzjami niż rozbudowana mapa statusów, z których połowę pamięta tylko jedna osoba. Poniżej zestaw zasad, które w praktyce robią największą różnicę.
- Zostaw tylko te statusy, które niosą decyzję. Jeśli status nie zmienia sposobu pracy zespołu, zwykle jest zbędny.
- Spisz warunki wejścia i wyjścia z każdego etapu. Tester ma wiedzieć, kiedy zgłoszenie może pójść dalej, a developer - co musi dostać, żeby zacząć pracę.
- Wymuś sensowny szablon zgłoszenia. Minimum to środowisko, wersja, kroki reprodukcji, wynik oczekiwany, wynik rzeczywisty i dowód w postaci zrzutu lub nagrania.
- Oddziel wpływ defektu od pilności naprawy. To pomaga uniknąć sporów o nazewnictwo i ustawia rozmowę na właściwym poziomie.
- Ustal jedną regułę retestu. Bez ponownej weryfikacji zamknięcie zgłoszenia jest tylko deklaracją, nie potwierdzeniem jakości.
- Przeglądaj proces regularnie. Jeśli dane pokazują, że zgłoszenia stoją w jednym miejscu, workflow trzeba poprawić, a nie przyzwyczajać się do zatoru.
W tym miejscu często wyciągam jeszcze jedną praktyczną obserwację: automatyzacja pomaga, ale tylko tam, gdzie ręczne decyzje naprawdę są powtarzalne. Automatyczne przypisywanie, etykietowanie czy powiadomienia oszczędzają czas, ale nie zastąpią triage ani dobrego opisu defektu. Narzędzie ma skracać drogę, a nie udawać, że rozwiązuje problem za zespół. Zostaje jeszcze jedna rzecz: co wdrożyć od razu, jeśli chcesz uporządkować defekty bez wielomiesięcznego projektu.
Co wdrożyć od razu, żeby defekty nie ginęły po drodze
Jeśli mam wskazać działania, które przynoszą szybki efekt, to zaczynam od prostych reguł operacyjnych. Nie potrzebujesz do tego dużej reorganizacji, tylko konsekwencji i jasnych zasad komunikacji.
- Używaj jednego, obowiązkowego szablonu zgłoszenia dla całego zespołu.
- Ustal jedną osobę lub jedną rotacyjną rolę odpowiedzialną za triage.
- Nie zamykaj zgłoszenia bez retestu i krótkiego potwierdzenia w komentarzu.
- Traktuj duplikaty i odrzucone zgłoszenia jako element procesu, a nie porażkę jakości.
- Co tydzień sprawdzaj trzy rzeczy: czas obsługi, liczbę ponownych otwarć i miejsca, w których defekty się blokują.
- Mapuj powtarzalne błędy do modułów lub obszarów produktu, żeby priorytety testów wynikały z danych, a nie z intuicji.
Dobrze opisany cykl życia błędu nie służy do ozdabiania procesu, tylko do tego, by każdy wiedział, co ma zrobić, kiedy i po czym poznać, że problem naprawdę zniknął. Jeśli ten porządek działa, testy są szybsze, zgłoszenia czytelniejsze, a produkcja dostaje mniej niespodzianek.