Awaria po wdrożeniu, regresja w testach automatycznych albo seria tych samych defektów w kilku sprintach zwykle nie oznacza jednego „błędu technicznego”. Najczęściej to sygnał, że w procesie QA pękło coś głębiej: wymagania, dane testowe, środowisko, komunikacja albo sam sposób sprawdzania jakości. W tym tekście pokazuję, jak prowadzić analizę przyczynowo-skutkową, rozdzielić objaw od przyczyny źródłowej i zamienić wnioski w działania, które realnie zmniejszają liczbę powtórek.
Najważniejsze informacje na start
- W QA najpierw oddzielam objaw od przyczyny źródłowej, bo czerwony test lub incydent produkcyjny nie mówią jeszcze, co naprawdę zawiodło.
- Najlepsze efekty dają zwykle 5 Why, diagram Ishikawy, oś czasu incydentu i analiza zmian w kodzie lub środowisku.
- Tę metodę warto stosować przy powracających defektach, flaky testach, błędach po wdrożeniu i problemach, które uderzają w klienta.
- Bez danych z logów, pipeline’u, monitoringu i historii zmian łatwo pomylić korelację z przyczyną.
- Każdy wniosek powinien kończyć się konkretem: co zmieniamy, kto to robi, do kiedy i po czym poznamy, że działa.
Na czym polega dojście do przyczyny źródłowej w QA
W procesach QA chodzi nie tylko o znalezienie błędu, ale o zrozumienie, dlaczego problem w ogóle przeszedł dalej. Jeśli test E2E pada, to widzę tylko objaw. Przyczyną może być niestabilne środowisko, źle przygotowane dane, brak izolacji testu, niepełna walidacja w API albo zmiana w kodzie, która nie została objęta odpowiednim scenariuszem.
Ja patrzę na to jak na łańcuch zdarzeń: od zmiany w wymaganiach, przez implementację, test, wdrożenie, monitorowanie, aż po zgłoszenie użytkownika. Im dokładniej opiszesz ten łańcuch, tym mniejsze ryzyko, że naprawisz wyłącznie symptom. To właśnie odróżnia sensowną analizę od szybkiego „fixa”, który uspokaja sytuację tylko na chwilę.
Najważniejsze rozróżnienie jest proste: objaw mówi, że coś jest nie tak, przyczyna źródłowa mówi, co trzeba zmienić, żeby problem nie wracał. Właśnie dlatego tak często w QA trafia się na sytuacje, w których naprawiono test, ale nie naprawiono procesu. Taki układ prawie zawsze kończy się kolejną awarią w innym miejscu.
Żeby nie zatrzymać się na ogólnikach, warto od razu przejść do sytuacji, w których taka analiza daje największy zwrot z pracy zespołu.
Kiedy warto robić taką analizę w procesach QA
Nie każda usterka wymaga formalnego warsztatu. Jeśli problem jest jednorazowy i od razu widać jego źródło, pełna analiza bywa przerostem formy. Inaczej jest wtedy, gdy defekt wraca, wpływa na klienta albo pokazuje, że zespół nie zatrzymuje problemów tam, gdzie powinien.
- Defekt wraca po poprawce - to sygnał, że naprawiasz objaw, a nie przyczynę. Zwykle oznacza to też, że testy regresji nie obejmują właściwego scenariusza.
- Błąd wychodzi dopiero na produkcji - wtedy trzeba sprawdzić, czy zawiodło pokrycie testami, dane wejściowe, monitoring, czy może proces akceptacji zmian.
- Testy automatyczne są niestabilne - flaky testy często nie są problemem samego narzędzia, tylko środowiska, synchronizacji lub zależności między przypadkami.
- Release regularnie się opóźnia - jeśli ten sam etap blokuje wydanie kilka razy z rzędu, to znak, że w procesie jest wąskie gardło, nie pojedyncza pomyłka.
- Support widzi problem, którego QA nie zauważyło - to zwykle znaczy, że testujesz inne warunki niż użytkownik albo nie masz realistycznych danych.
W praktyce najbardziej opłaca się analizować problemy powtarzalne, kosztowne albo takie, które mają wpływ na zaufanie do produktu. Gdy już wiesz, kiedy wchodzić głębiej, pozostaje pytanie, jak dobrać metodę do skali problemu.
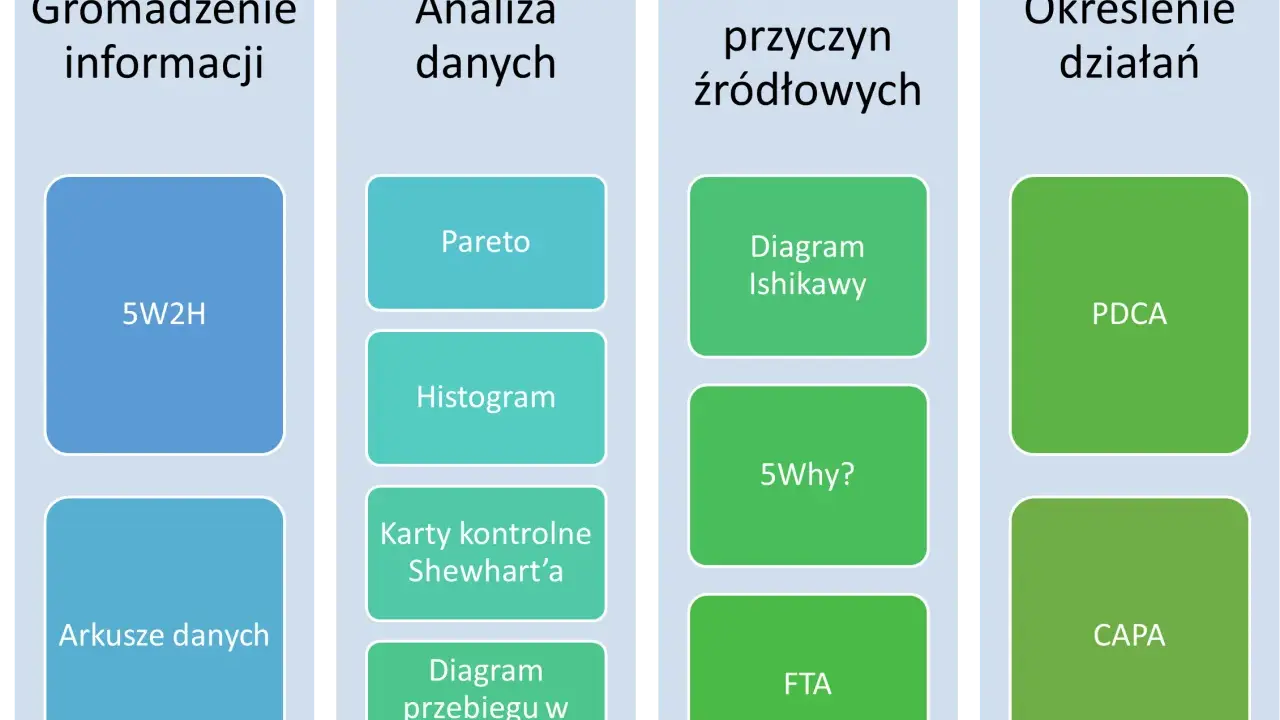
Jakie metody i narzędzia dają najlepszy efekt
Nie ma jednej techniki na każdy przypadek. Przy prostych problemach wystarczy 5 Why, przy bardziej złożonych lepiej połączyć kilka podejść: diagram Ishikawy, oś czasu incydentu i krótką analizę zmian w kodzie, danych lub konfiguracji. W małym zespole najlepiej działa grupa 3-8 osób, bo to jeszcze daje różne perspektywy, ale nie rozmywa odpowiedzialności.
| Metoda | Kiedy użyć | Co daje | Ograniczenie |
|---|---|---|---|
| 5 Why | Gdy problem ma dość prosty, liniowy przebieg i chcesz szybko dojść do źródła | Pomaga zejść od objawu do przyczyny bez nadmiaru formalizmu | Łatwo zatrzymać się na pierwszej logicznie brzmiącej odpowiedzi |
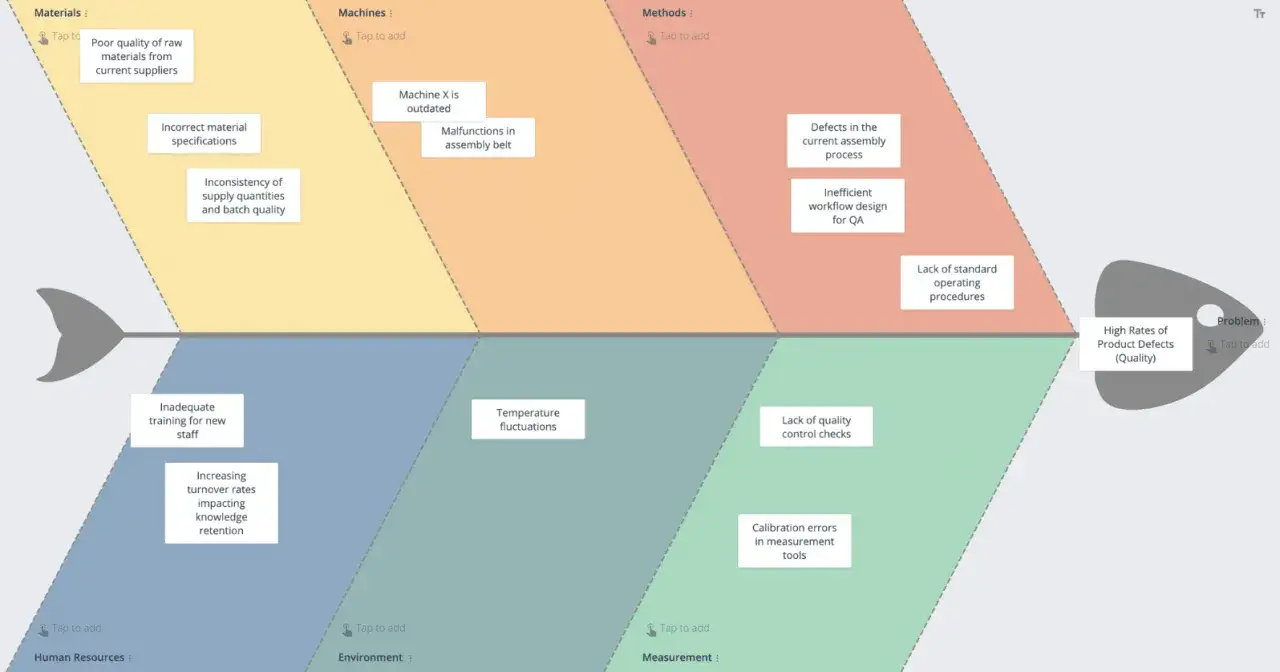
| Diagram Ishikawy | Gdy przyczyn jest wiele i trzeba je uporządkować w kategorie | Porządkuje burzę mózgów i pokazuje obszary ryzyka | Sam nie wskazuje winnej przyczyny, tylko pomaga ją zawęzić |
| Oś czasu incydentu | Gdy problem pojawił się po wdrożeniu, deployu lub zmianie konfiguracji | Łączy zdarzenia w kolejności, w jakiej naprawdę wystąpiły | Wymaga dobrych logów, metryk i historii zmian |
| Analiza Pareto | Gdy masz dużo defektów i chcesz ustalić, które obszary dają największy koszt | Pomaga priorytetyzować pracę | Pokazuje, gdzie boli najbardziej, ale nie tłumaczy, dlaczego |
W software QA szczególnie dobrze działa połączenie kategorii z Ishikawy z praktycznym podziałem na kod, dane, środowisko, proces, ludzi i pomiary. To prostsze niż klasyczne „6M”, a dużo bliższe codziennej pracy zespołu. Sama metoda jednak nie wystarczy, jeśli rozmowa o problemie jest prowadzona źle.
Jak przeprowadzić analizę krok po kroku
- Zdefiniuj problem jednym zdaniem - opisz, co się stało, gdzie, kiedy i jaki był wpływ. Zamiast „testy są złe” napisz: „w module płatności 3 z 18 testów E2E zaczęły failować po wdrożeniu wersji X”.
- Zbierz twarde dane - logi, wynik pipeline’u, zrzuty ekranu, metryki, historię commitów, zmiany konfiguracji i zgłoszenia użytkowników. Bez tego analiza szybko zamienia się w opiniowanie.
- Ułóż oś czasu - sprawdź, co zmieniło się przed wystąpieniem błędu. Najczęściej ważniejsza od samego symptomu jest pierwsza zmiana, która mogła go uruchomić.
- Oddziel hipotezy od faktów - zapisuj przypuszczenia, ale od razu je weryfikuj. Jedna hipoteza powinna prowadzić do jednego testu lub sprawdzenia.
- Docieraj niżej niż pierwsze „bo” - w 5 Why nie chodzi o piękną liczbę, tylko o sens. Czasem wystarczą 3 pytania, czasem trzeba dojść do 7-8, żeby znaleźć prawdziwy problem.
- Zamknij analizę decyzją - ustal działanie korygujące, właściciela, termin i sposób weryfikacji. Bez tego cała praca kończy się na notatce, a nie na poprawie jakości.
Najlepsze analizy mają jedną wspólną cechę: nie kończą się na wskazaniu przyczyny, tylko na potwierdzalnym działaniu. Zanim jednak ktoś uzna, że problem został „rozgryziony”, warto sprawdzić, czy zespół nie wpadł w typowe pułapki interpretacyjne.
Najczęstsze błędy, które psują wnioski
W QA najłatwiej zepsuć analizę nie przez brak wiedzy, tylko przez pośpiech. Kiedy presja rośnie, ludzie zaczynają szukać winnego, a nie przyczyny. To zmienia cały ton rozmowy i prawie zawsze obniża jakość wniosków.
- Szukanie osoby zamiast mechanizmu - „kto to zrobił?” brzmi prosto, ale niczego nie wyjaśnia. Znacznie ważniejsze jest pytanie, dlaczego proces nie zatrzymał błędu.
- Zatrzymanie się na pierwszym oczywistym powodzie - to, że problem pojawił się po deployu, nie znaczy jeszcze, że deploy był jedyną przyczyną.
- Myląca korelacja z przyczyną - zbieżność czasowa nie dowodzi związku. Jeśli build padł po zmianie środowiska, trzeba to udowodnić, a nie zakładać z automatu.
- Zbyt ogólne wyjaśnienia - „komunikacja”, „proces”, „ludzie” albo „brak testów” są zbyt szerokie, dopóki nie da się ich przełożyć na konkretny element do poprawy.
- Brak danych pomiarowych - bez logów, metryk i historii zmian analiza staje się rekonstrukcją opinii, nie faktów.
- Brak finalnej decyzji - jeśli po spotkaniu nie ma właściciela i terminu, zespół zwykle wraca do tego samego problemu w następnym sprincie.
Jeśli przyczyna nie da się zamienić na działanie, to najpewniej nie została jeszcze dobrze nazwana. I właśnie dlatego ostatni krok jest najważniejszy: analiza musi wejść w rytm pracy zespołu, a nie pozostać jednorazowym wydarzeniem.
Co wdrożyć, żeby analiza naprawdę poprawiała jakość
Najlepsza analiza przyczynowa w QA ma bardzo proste zakończenie: jedna zmiana, jedna odpowiedzialność, jeden sposób sprawdzenia efektu. Bez tego zespół ma tylko ciekawą dyskusję, ale nie ma lepszego procesu. Ja zwykle rozbijam wnioski na trzy poziomy: działanie korygujące usuwa bieżący problem, działanie zapobiegawcze ogranicza ryzyko powtórki, a działanie detekcyjne pozwala szybciej wykryć podobny błąd następnym razem.
- Przypisz właściciela do każdej akcji, nawet jeśli jest to zadanie międzyzespołowe.
- Dodaj termin i prosty warunek sukcesu, na przykład „błąd nie wraca przez 2 kolejne iteracje testowe”.
- Sprawdzaj nie tylko liczbę defektów, ale też powtarzalność błędów, liczbę defektów, które uciekły na produkcję, oraz stabilność testów automatycznych.
- Wracaj do poprzednich analiz po kilku tygodniach i pytaj, czy problem naprawdę zniknął, czy tylko zmienił formę.
- Jeśli zespół kilka razy z rzędu identyfikuje podobną przyczynę, potraktuj to jako sygnał procesowy, a nie zbieg okoliczności.
W praktyce największą różnicę robi nie sama nazwa metody, ale dyscyplina wykonania: jasny problem, dobre dane, odwaga do zadawania kolejnych pytań i konkret po spotkaniu. Jeśli zaczniesz od faktów, a nie od intuicji, analiza przestaje być formalnością, a staje się jednym z najtańszych sposobów na poprawę jakości produktu.