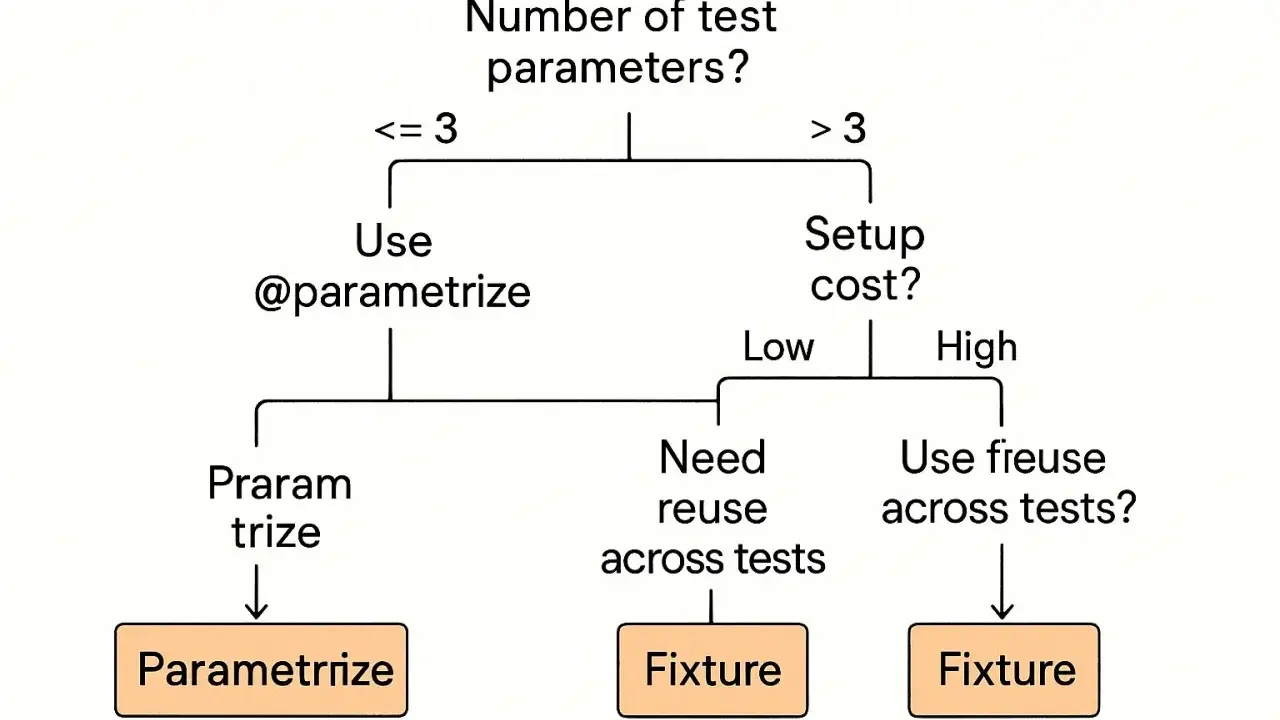
Najważniejsze rzeczy, które warto wiedzieć o łączeniu parametrów z fixture’ami
- `@pytest.mark.parametrize` najlepiej sprawdza się wtedy, gdy zmieniają się tylko dane wejściowe i asercje.
- `@pytest.fixture(params=...)` jest lepsze, gdy parametry zmieniają sposób budowy środowiska, obiektu lub zależności.
- `indirect=True` przekazuje wartości do fixture przez `request.param`, więc setup może być cięższy, ale pozostaje czytelny.
- `scope` decyduje, jak często pytest tworzy fixture i jak duży będzie koszt uruchomienia testów.
- `ids` i `pytest.param()` poprawiają raporty, selekcję przypadków i kontrolę nad oznaczeniami typu skip lub xfail.
- Najczęstszy błąd to nadmierne mnożenie kombinacji, które wygląda efektownie, ale spowalnia całą paczkę testów.
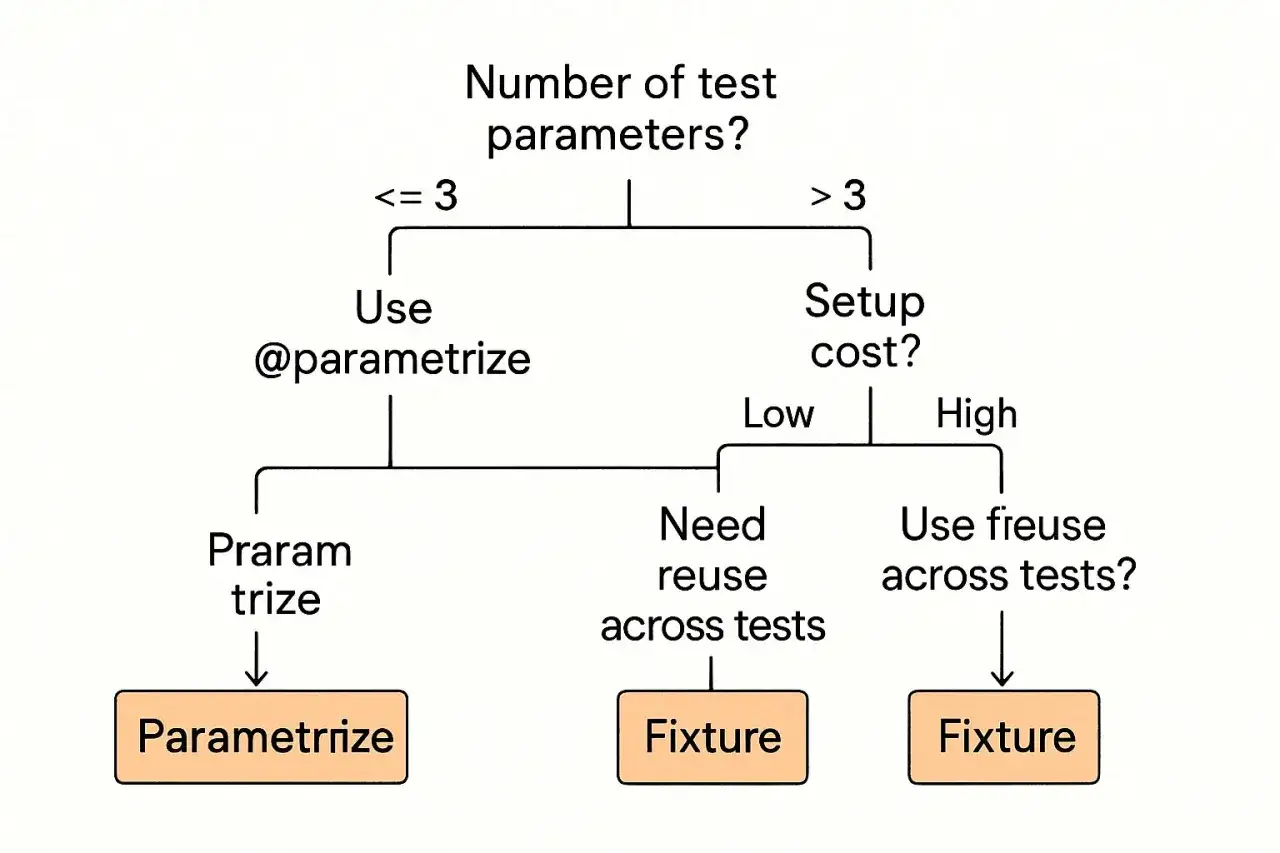
Jak działa połączenie parametrów i fixture’ów
Najprościej myśleć o tym tak: parametryzacja testu mnoży przypadki, a fixture przygotowuje warunki ich uruchomienia. Gdy łączysz oba mechanizmy, pytest najpierw buduje zestaw przypadków podczas kolekcji testów, a potem dla każdego wariantu wykonuje odpowiedni setup. To ważne rozróżnienie, bo od razu tłumaczy, dlaczego niektóre rzeczy powinny żyć w teście, a inne w fixture.import pytest
@pytest.fixture(params=["sqlite", "postgres"])
def backend(request):
return request.param
@pytest.mark.parametrize(
"user_role,expected",
[
("admin", True),
("guest", False),
],
)
def test_access(backend, user_role, expected):
assert isinstance(backend, str)
assert (user_role == "admin") is expectedW tym przykładzie każdy test uruchomi się dla obu backendów i obu ról, więc pytest wygeneruje cztery kombinacje. To działa dobrze, jeśli naprawdę chcesz sprawdzić produkt w pełnym macierzu scenariuszy. Jeśli nie, trzeba świadomie ograniczyć liczbę wariantów, bo inaczej łatwo stworzyć kosztowną lawinę przypadków.
- Pytest zbiera testy i rozwija zestawy parametrów.
- Fixture z `params` dostaje bieżącą wartość przez `request.param`.
- Setup wykonuje się zgodnie ze `scope` fixture, a nie z samą liczbą testów.
- W raporcie pojawiają się osobne przypadki z własnymi identyfikatorami.
To właśnie ten model działania pozwala pisać testy danych i konfiguracji bez powielania kodu, a dalej przejść do pytania, kiedy użyć którego mechanizmu w praktyce.
Kiedy użyć `parametrize`, a kiedy `params` w fixture
Ja zwykle rozdzielam te dwa narzędzia bardzo prosto: jeśli zmienia się tylko wejście i oczekiwany wynik, wybieram parametryzację testu. Jeśli zmienia się przygotowanie świata testowego, idę w fixture z `params`. To nie jest detal stylistyczny, tylko decyzja, która wpływa na czytelność, czas wykonania i łatwość utrzymania całej paczki testów.
| Sytuacja | Lepszy wybór | Dlaczego |
|---|---|---|
| Dane wpływają tylko na asercję | @pytest.mark.parametrize |
Test pozostaje prosty, a setup nie komplikuje się bez potrzeby. |
| Wariant zmienia obiekt, backend albo konfigurację | @pytest.fixture(params=...) |
Setup jest kontrolowany w jednym miejscu i nie trzeba duplikować logiki budowy środowiska. |
| Wartość ma trafić do fixture, ale definiujesz ją na poziomie testu | indirect=True |
Fixture dostaje surowe dane i sama zamienia je w obiekt lub zasób. |
| Chcesz czytelne nazwy przypadków lub osobne markery |
pytest.param() i ids
|
Raporty są czytelniejsze, a selekcja pojedynczych przypadków dużo prostsza. |
Jeśli mam wątpliwość, zaczynam od prostszego wariantu. Bardzo często okazuje się, że parametr należy do testu, a nie do fixture, bo dotyczy tylko porównania wyniku. To drobna decyzja architektoniczna, ale w większym projekcie robi dużą różnicę. Następny krok pojawia się wtedy, gdy wartość wejściowa ma przejść przez fixture i zostać zamieniona w coś bardziej złożonego.
Jak wykorzystać `indirect`, gdy fixture ma budować obiekt na podstawie danych
`indirect=True` jest użyteczne wtedy, gdy test ma podać tylko prostą wartość, a właściwa konstrukcja ma odbyć się w fixture. To dobry wzorzec dla baz danych, klientów API, profili konfiguracji albo generatorów obiektów, które wymagają dodatkowego setupu. Dzięki temu test nie musi znać szczegółów tworzenia zależności, a fixture może skupić się na budowie konkretnego wariantu.
import pytest
class DB1:
pass
class DB2:
pass
@pytest.fixture
def db(request):
if request.param == "d1":
return DB1()
if request.param == "d2":
return DB2()
raise ValueError("nieznany backend")
@pytest.mark.parametrize("db", ["d1", "d2"], indirect=True)
def test_db_initialized(db):
assert db is not NoneTu dane `d1` i `d2` nie są jeszcze gotowymi obiektami. Dopiero fixture zamienia je na konkretne instancje. To szczególnie ważne, gdy tworzenie obiektu jest drogie albo zależy od zewnętrznej infrastruktury, bo koszt przesuwa się z kolekcji testów na moment rzeczywistego uruchomienia.
Przy wielu argumentach można też zastosować `indirect` tylko dla wybranych nazw, na przykład `indirect=["db"]`. To wygodne, gdy jeden parametr ma iść przez fixture, a drugi ma pozostać zwykłą wartością testową. Z tego miejsca naturalnie przechodzimy do kwestii, która najbardziej wpływa na czas działania całej baterii testów: zakresu fixture.
Zakres fixture decyduje o kosztach uruchomienia
W projektach automatyzacji zakres fixture bywa ważniejszy niż sama liczba parametrów. Jeśli tworzysz drogi zasób przy każdym teście, nawet dobrze napisany zestaw danych zacznie działać wolno. Z drugiej strony zbyt szeroki zakres może ukryć zależności między testami i wprowadzić stan współdzielony, którego nikt nie planował.
| Scope | Kiedy ma sens | Główne ryzyko |
|---|---|---|
function |
Gdy potrzebujesz pełnej izolacji i prostego czyszczenia stanu. | Najsłabsza wydajność przy drogim setupie. |
class |
Gdy testy w jednej klasie używają tego samego przygotowania. | Łatwo przeoczyć współdzielony stan między metodami. |
module |
Gdy kilka testów w pliku korzysta z jednego zasobu. | Trudniejsze debugowanie, jeśli stan przecieka między przypadkami. |
package |
Gdy chcesz współdzielić zasób w obrębie całego pakietu testów. | Większa złożoność i większe znaczenie porządku teardownu. |
session |
Gdy setup jest naprawdę drogi, na przykład dla zewnętrznego serwisu. | Największe ryzyko ukrytej zależności i „magicznego” stanu globalnego. |
Pytest dodatkowo grupuje testy tak, aby ograniczać liczbę aktywnych instancji fixture. To pomaga przy zasobach, które mają własny teardown, ale też oznacza, że kolejność wykonania może wyglądać inaczej, niż intuicyjnie się spodziewasz. Ja traktuję to jako sygnał ostrzegawczy: jeśli testy zaczynają zależeć od kolejności, problem zwykle nie leży w pytest, tylko w stanie współdzielonym.
Gdy zakres jest dobrze dobrany, można skupić się na tym, żeby wyniki były czytelne. Tu wchodzą do gry identyfikatory przypadków i markery, które w większych suites robią zaskakująco dużą różnicę.
Jak poprawić raporty dzięki `ids`, markom i `pytest.param`
W raportach testowych nie wygrywa ten, kto ma najwięcej przypadków, tylko ten, kto potrafi szybko wskazać, który wariant się wysypał i dlaczego. Dlatego przy parametrówce bardzo cenię czytelne ID, bo zamiast bezosobowego `test_case[1]` dostaję nazwę, która od razu mówi, co testowałem. To oszczędza czas w CI, a przy diagnozie regresji bywa bezcenne.
import pytest
@pytest.fixture(
params=[
pytest.param("sqlite", id="sqlite"),
pytest.param(
"postgres",
id="pg",
marks=pytest.mark.xfail(reason="known issue"),
),
]
)
def backend(request):
return request.param
def test_backend_name(backend):
assert backend in {"sqlite", "postgres"}Najpraktyczniejsze elementy są trzy. Po pierwsze, `ids` może być listą albo funkcją, która generuje nazwę na podstawie wartości. Po drugie, `pytest.param()` pozwala przypisać do konkretnego przypadku markery typu skip lub xfail. Po trzecie, sensowne ID ułatwiają selekcję przez `-k` i analizę `--collect-only`, kiedy chcesz odpalić tylko jeden wariant.
To właśnie tutaj wielu zespołom zaczyna się opłacać mała dyscyplina redakcyjna w testach: nazwy wariantów powinny być krótkie, ale jednoznaczne. Z tak przygotowanym raportowaniem łatwiej wyłapać błędy, które zwykle pojawiają się dopiero po czasie.
Najczęstsze błędy, które wyglądają jak problem z pytestem
W praktyce największe kłopoty z parametryzacją fixture’ów zwykle nie wynikają z samego pytest, tylko z decyzji projektowych, które z czasem stają się kosztowne. Najczęściej widzę te same pułapki: za dużo kombinacji, za mało izolacji albo zbyt ciężki setup wykonywany w złym momencie.
- Parametryzowanie fixture tam, gdzie wystarczyłoby zwykłe `parametrize` na wejściu testu.
- Tworzenie zbyt wielu kombinacji przez bezrefleksyjne stackowanie dekoratorów, co mnoży liczbę przypadków w sposób trudny do utrzymania.
- Wrzucanie kosztownego setupu do czasu kolekcji zamiast do samej fixture, przez co uruchomienie testów staje się wolniejsze, niż musi.
- Ukrywanie stanu w globalnych zmiennych lub w module, co powoduje losowe zależności między przypadkami.
- Ignorowanie pustych zestawów parametrów, które mogą prowadzić do nieoczywistego zachowania zgodnie z konfiguracją `empty_parameter_set_mark`.
- Zakładanie, że szeroki scope zawsze przyspiesza testy, choć przy złym teardownie często tylko maskuje problem.
Ja zwykle sprawdzam jeden prosty test diagnostyczny: jeśli usunięcie jednego parametru nie zmienia jakości pokrycia, to najpewniej ten parametr był zbędny. Taka redukcja prawie zawsze poprawia stabilność i skraca czas działania całej paczki. Z tych obserwacji da się już złożyć sensowny wzorzec pracy dla zespołu, który rozwija automatyzację na serio.
Jak ułożyć z tego stabilny wzorzec w projekcie automatyzacji
Najlepiej działa podejście warstwowe. Dane, które wpływają tylko na asercję, zostawiam w `parametrize`. Setup, który buduje środowisko, przenoszę do fixture z `params`. A jeśli test ma dostać prosty znacznik, z którego fixture stworzy bardziej złożony obiekt, używam `indirect`. Dzięki temu każdy element ma jedną odpowiedzialność i łatwiej utrzymać porządek w rosnącej bazie testów.
- Rozdzielaj dane testowe od przygotowania środowiska.
- Trzymaj ciężki setup jak najniżej w liczbie uruchomień, ale nie kosztem przejrzystości.
- Nazywaj przypadki tak, jak naprawdę będziesz ich szukać w raporcie CI.
- Ograniczaj scope do tak szerokiego, jak naprawdę potrzebujesz.
- Unikaj tworzenia kombinacji, których nikt nie będzie analizował przy awarii.
Jeśli miałbym zostawić jedną praktyczną zasadę, brzmiałaby tak: nie parametryzuj dla samej liczby testów, tylko dla różnic, które coś zmieniają. W dobrze utrzymanym projekcie automatyzacji to właśnie ta dyscyplina decyduje, czy pytest pozostaje wygodnym narzędziem, czy zamienia się w źródło szumu. A gdy już masz poprawnie rozdzielone dane, fixture i zakres, dalsze rozbudowywanie suite’u staje się znacznie prostsze.