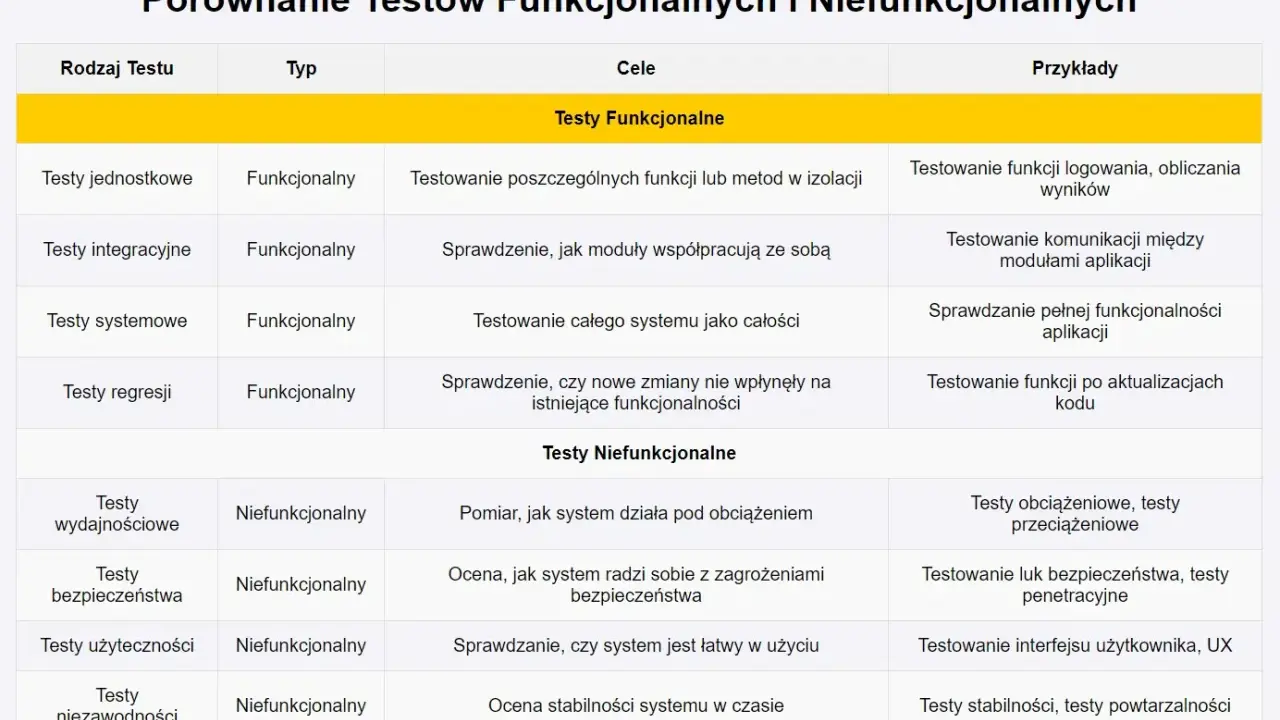
Najwięcej daje prosty układ, stabilne dane i testy oparte na zachowaniu widocznym dla użytkownika
- Skrypt testowy to powtarzalna instrukcja, która uruchamia scenariusz, sprawdza wynik i ogranicza ryzyko regresji.
- Najpierw warto automatyzować krytyczne ścieżki biznesowe, szybkie testy API i sprawdzenia regresji.
- Stabilność zależy bardziej od izolacji danych i doboru selektorów niż od samej nazwy narzędzia.
- Testy UI są potrzebne, ale tylko tam, gdzie faktycznie chronią wartość biznesową.
- Bez CI, logów, zrzutów ekranu lub trace’ów nawet dobry skrypt szybko staje się trudny w utrzymaniu.
Czym są skrypty testowe i kiedy mają sens
Skrypt testowy to zautomatyzowana instrukcja, która uruchamia konkretny scenariusz, sprawdza wynik i porównuje go z oczekiwaniem. W odróżnieniu od ręcznej checklisty taki zapis można odpalić wielokrotnie, w tym samym środowisku i z tym samym zestawem danych, co daje porównywalność i szybsze wykrywanie regresji.
Ja patrzę na to prosto: jeśli scenariusz ma sens powtarzać wiele razy, wymaga wielu kliknięć albo łatwo psuje się po zmianach w kodzie, to jest dobrym kandydatem do automatyzacji. Jeśli za to chodzi o jednorazową eksplorację, ocenę UX albo bardzo niestabilny fragment produktu, lepiej nie udawać, że skrypt rozwiąże problem.
Warto też rozróżnić trzy pojęcia: test case, test script i test suite. Pierwsze opisuje zamiar i oczekiwany wynik, drugie jest jego wykonaną, automatyczną wersją, a trzecie to zestaw takich skryptów uruchamianych razem. To rozróżnienie pomaga uniknąć chaosu w repozytorium i w komunikacji między QA a developmentem.
W praktyce najbardziej opłacają się scenariusze o wysokim ryzyku biznesowym: logowanie, płatności, rejestracja, tworzenie kluczowych rekordów, wyszukiwanie, eksport danych czy krytyczne integracje. Im częściej dana ścieżka jest uruchamiana ręcznie i im większa szkoda po regresji, tym mocniejszy argument za automatyzacją.
To prowadzi do pytania nie o samo narzędzie, ale o konstrukcję skryptu, bo właśnie tam zaczynają się różnice między automatyzacją użyteczną a tylko efektowną.
Jak zbudować stabilny skrypt krok po kroku
Dobry skrypt nie jest długi. Jest jednoznaczny. Zawiera stan początkowy, działania, asercję i sprzątanie po teście. Jeśli którykolwiek z tych elementów jest niejasny, za miesiąc będzie kosztował więcej niż oszczędził.
| Element | Co powinno się w nim znaleźć | Po co to jest |
|---|---|---|
| Preconditions | Stan systemu, konto, role, dane wejściowe, punkt startowy | Żeby test startował z przewidywalnego miejsca |
| Dane testowe | Przygotowane rekordy, fixture, identyfikatory, testowe API | Żeby nie zależeć od losowego stanu środowiska |
| Kroki | Tylko działania, które naprawdę wykonuje użytkownik lub system | Żeby skrypt był czytelny i łatwy do utrzymania |
| Asercje | Widoczny efekt, odpowiedź API, stan bazy, komunikat błędu | Żeby sprawdzać rezultat, a nie sam fakt uruchomienia |
| Cleanup | Usunięcie danych, reset sesji, odtworzenie stanu początkowego | Żeby kolejne testy nie dziedziczyły bałaganu |
Najlepszy wzorzec to proste prepare, act, assert, clean. W bardziej rozbudowanych projektach dorzucam jeszcze obserwowalność: log, screenshot albo trace, który pozwala odtworzyć błąd bez zgadywania, co poszło nie tak.
W asercjach skupiam się na tym, co użytkownik faktycznie widzi lub co system gwarantuje. Dokumentacja Playwright mocno akcentuje testowanie zachowania widocznego dla użytkownika, a nie szczegółów implementacji. To praktyczna zasada także poza tym narzędziem: jeśli sprawdzasz klasę CSS zamiast efektu działania, wnosisz do testu zbędny, kruchy punkt.
Przykładowy logiczny szkic wygląda tak: przygotuj konto i dane, otwórz stronę, wykonaj akcję, sprawdź komunikat, zweryfikuj zapis w API lub bazie, a na końcu przywróć środowisko do stanu wyjściowego. Taki układ jest prosty, ale łatwy do utrzymania.
Na tym etapie zwykle pojawia się pytanie, co testować najpierw, bo nie wszystko ma taką samą wartość biznesową.
Które rodzaje automatyzacji warto pokrywać najpierw
Jeśli mam ograniczony budżet czasu, zaczynam od warstw, które dają najwięcej stabilności przy najmniejszym koszcie utrzymania. Z reguły są to testy API i komponentowe, a dopiero potem cięższe testy UI.
| Rodzaj testu | Kiedy ma największy sens | Mocne strony | Ograniczenia |
|---|---|---|---|
| API | Logika biznesowa, integracje, walidacje danych | Szybkie, stabilne, łatwe do uruchamiania w CI | Nie pokazują problemów interfejsu użytkownika |
| Komponentowe i integracyjne | Moduły frontendu, formularze, fragmenty przepływów | Dobre połączenie szybkości i kontroli | Wymagają sensownie zaprojektowanej aplikacji |
| UI / E2E | Krytyczne ścieżki, które użytkownik widzi od początku do końca | Chronią najważniejsze procesy biznesowe | Bywają wolniejsze i bardziej kruche |
| Smoke | Weryfikacja, czy build nadaje się do dalszych testów | Szybko wyłapują awarie podstawowego przepływu | Nie zastępują pełnej regresji |
| Regresja | Ochrona przed powrotem wcześniej naprawionych błędów | Najlepsze wsparcie dla stabilności produktu | Rosną wraz z produktem i wymagają porządkowania |
Ja zwykle trzymam zasadę: im bliżej logiki i API, tym więcej testów; im bliżej UI, tym mniej, ale za to najważniejsze ścieżki muszą być szczelne. To ogranicza koszty i zmniejsza ryzyko, że zespół zacznie utrzymywać setki delikatnych skryptów do sprawdzania rzeczy, które szybciej i pewniej da się potwierdzić niżej w stosie.
Tu dobrze pasuje jeszcze jedna praktyczna uwaga: zalecenia Selenium przypominają, że jeśli termin jest bardzo ciasny, a automatyzacji jeszcze nie ma, sensowniejsze mogą być testy manualne niż pośpiesznie sklecony suite. To nie jest porażka automatyzacji, tylko zdrowe zarządzanie priorytetem.
Skoro wiadomo, co automatyzować, zostaje pytanie, w jakim narzędziu to zrobić i jakich praktyk pilnować na co dzień.
Narzędzia i praktyki, które naprawdę pomagają
Wybór narzędzia ma znaczenie, ale nie tak duże, jak zwykle się zakłada. W praktyce liczy się przede wszystkim to, czy framework ułatwia izolację testów, stabilne selektory, debugowanie i sensowne raportowanie po błędzie.
| Narzędzie | Kiedy wybrać | Na co uważać |
|---|---|---|
| Selenium | Gdy potrzebujesz szerokiego ekosystemu, wielu języków i mocno dojrzałej integracji z istniejącą infrastrukturą | Wymaga większej dyscypliny w projektowaniu suite’u i utrzymaniu stabilności |
| Cypress | Gdy zespół front-endowy chce szybciej pisać i debugować testy w przeglądarce | Łatwo popaść w nadmiar testów UI, jeśli nie ma jasnych granic odpowiedzialności |
| Playwright | Gdy zależy ci na izolacji, locators opartych na rolach i nazwach oraz wygodnym debugowaniu | Nadal wymaga dobrego modelu danych i kontroli nad stanem aplikacji |
Dokumentacja Playwright mocno podkreśla izolację testów i selektory oparte na tym, co widzi użytkownik. To dokładnie ten kierunek, który w 2026 robi największą różnicę: mniej zależności od DOM-u, mniej przypadkowych awarii, szybsze dochodzenie do źródła problemu.
Największą różnicę robi jednak nie samo narzędzie, ale zestaw nawyków. Dobry skrypt powinien korzystać z locatorów odpornych na zmiany UI, działać na odizolowanych danych i dawać czytelny ślad po porażce: screenshot, video, trace albo log z krokiem, na którym test się zatrzymał.
W 2026 coraz częściej dochodzi też generowanie testów wspierane przez AI. Traktuję je jako przyspieszacz startu, nie zastępstwo dla przeglądu. Automatycznie wygenerowany skrypt nadal trzeba odchudzić, uprościć i dopasować do zasad repozytorium, bo bez tego szybko staje się tylko hałaśliwym szkieletem.
Żeby to działało długo, trzeba jeszcze unikać kilku błędów, które regularnie niszczą nawet dobrze zaplanowaną automatyzację.
Najczęstsze błędy, które psują automatyzację
Najbardziej kosztowne błędy są zwykle proste. Nie chodzi o brak zaawansowanego frameworka, tylko o codzienne decyzje, które robią z testów kruchy system zależności.
- Współdzielone dane testowe - jeśli jeden test zostawia po sobie bałagan, kolejny zaczyna failować bez związku z kodem.
- Brittle selectors - wybieranie elementów po klasach lub strukturze DOM sprawia, że drobna zmiana UI rozwala cały suite.
- Nadużywanie sleep i waitTimeout - sztuczne pauzy maskują problem, zamiast go rozwiązać, i spowalniają całą paczkę testów.
- Zbyt dużo UI, za mało warstw niżej - jeśli każdy scenariusz idzie przez przeglądarkę, testy stają się drogie i wolne.
- Brak ownershipu - gdy nikt nie odpowiada za utrzymanie, flaky testy zostają w repozytorium na miesiące.
- Brak triage po błędzie - fail bez screenshotu, trace’a lub sensownego loga niemal zawsze kończy się zgadywaniem.
W praktyce najbardziej zdradliwy jest flaky test, czyli taki, który przechodzi i pada bez zmiany w kodzie. To zabija zaufanie szybciej niż pojedyncza awaria, bo zespół zaczyna ignorować czerwone buildy i traci sygnał, który automatyzacja miała dostarczać.
Ja zawsze sprawdzam też, czy skrypt nie testuje czegoś, czego nie kontrolujemy. Zewnętrzne integracje, nieprzewidywalne odpowiedzi osób trzecich albo niestabilne środowiska są wygodnym miejscem na fałszywe alarmy. Lepiej je odseparować albo zamockować, niż udawać, że suite jest odporny na wszystko.
Jeśli teraz zadajesz sobie pytanie, jak utrzymać te testy, gdy produkt zacznie rosnąć, to właśnie ten etap najczęściej decyduje, czy automatyzacja stanie się wsparciem, czy kosztem stałym.
Jak utrzymać skrypty, kiedy produkt rośnie
Dobry zestaw automatyzacji nie kończy się na pierwszym zielonym uruchomieniu. On zaczyna mieć wartość dopiero wtedy, gdy zespół potrafi go utrzymać przez kolejne sprinty, zmiany UI i refaktoryzacje backendu.
W praktyce trzymam się kilku prostych zasad. Po pierwsze, każdy nowy skrypt powinien mieć jasny cel biznesowy. Po drugie, testy trzeba uruchamiać w CI w takim miejscu procesu, w którym dają sygnał zanim zmiana trafi dalej. Po trzecie, suite trzeba regularnie czyścić z martwych przypadków i tych, które nic już nie chronią.
Warto też rozdzielić testy stabilne od eksperymentalnych. Jeśli jakiś scenariusz jest ważny, ale jeszcze niepewny, lepiej oznaczyć go osobno niż mieszać z kluczową regresją. Dzięki temu zespół wie, którym wynikom ufać od razu, a które wymagają jeszcze dopracowania.
Gdybym miał zacząć od zera, wybrałbym pięć krytycznych ścieżek, jedno stabilne środowisko testowe i prostą zasadę: każda awaria ma mieć właściciela, kontekst i ślad diagnostyczny. To wystarcza, żeby automatyzacja nie była ozdobą w repozytorium, tylko realnym filtrem jakości.
Jeśli chcesz budować to rozsądnie, zacznij od najważniejszych przepływów, nie od największej liczby testów. Wtedy skrypty testowe będą chronić produkt, zamiast tylko go obciążać.