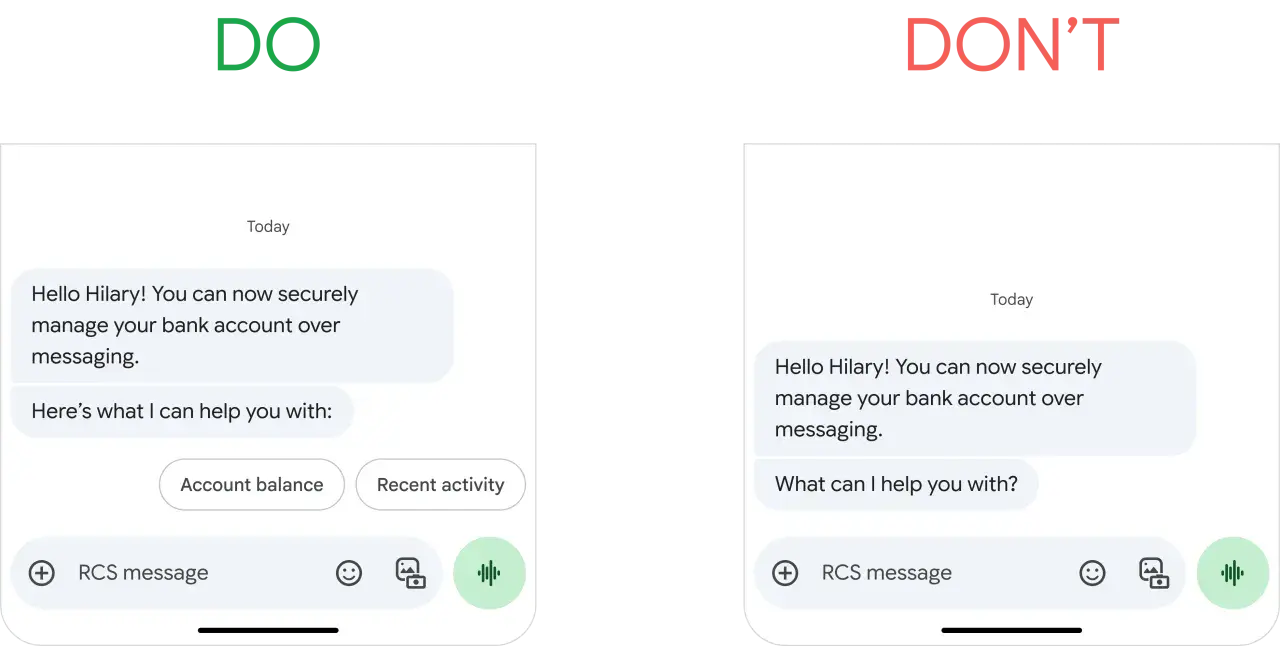
Najważniejsze rzeczy o dobrych przypadkach testowych
- Przypadek testowy to konkretny scenariusz weryfikacji z danymi wejściowymi, krokiem działania i oczekiwanym wynikiem.
- Dobry zapis jest wystarczająco precyzyjny, ale nie przeładowany detalami, które tylko utrudniają utrzymanie.
- Najlepsze przypadki testowe powstają z wymagań, user stories i analizy ryzyka, a nie z kopiowania ekranu po ekranie.
- W praktyce liczą się też priorytety, wersjonowanie, śledzenie powiązań z wymaganiami i regularne porządki w bazie testów.
- Automatyzacja nie zastępuje dobrego projektu testu, tylko wzmacnia te przypadki, które są stabilne i powtarzalne.
Czym jest przypadek testowy i po co się go tworzy
W mojej pracy przypadek testowy traktuję jako małą, jednoznaczną instrukcję weryfikacji zachowania systemu. Ma odpowiedzieć na trzy proste pytania: co sprawdzamy, na jakich danych to robimy i skąd wiemy, że wynik jest poprawny. To odróżnia go od ogólnego scenariusza testowego, który zwykle opisuje szerszy obszar, ale nie daje jeszcze gotowej instrukcji wykonania.
W terminologii ISTQB test case może mieć poziom wysoki albo niski. Wysoki poziom dobrze sprawdza się na etapie planowania i pokrycia wymagań, a niski wtedy, gdy ktoś ma wykonać test bez domyślania się czegokolwiek. Ja zwykle pilnuję, żeby zespół nie mylił tych dwóch rzeczy, bo to właśnie tam rodzi się większość późniejszych nieporozumień.
Najprościej mówiąc, przypadek testowy ma zmniejszać chaos. Bez niego łatwo pominąć ważny wariant, powtórzyć ten sam test kilka razy albo uznać coś za „sprawdzone”, choć nikt nie zdefiniował jeszcze, co dokładnie miało być wynikiem poprawnym. Skoro to już jasne, można przejść do tego, jak taki zapis powinien wyglądać w praktyce.
Z czego składa się dobry przypadek testowy
Dobry przypadek testowy nie musi być długi, ale powinien być kompletny. Jeśli brakuje w nim danych wejściowych albo oczekiwanego rezultatu, wykonujący test zaczyna dopowiadać resztę samodzielnie, a to niemal zawsze obniża jakość całego procesu. Poniżej pokazuję zestaw pól, które w praktyce naprawdę mają znaczenie.
| Element | Po co jest | Jak pisać praktycznie |
|---|---|---|
| Identyfikator | Ułatwia śledzenie, raportowanie i linkowanie do wymagań | Stosuj prosty, stabilny format, np. `LOGIN-001` |
| Tytuł | Szybko mówi, czego dotyczy test | Niech opisuje cel, a nie tylko kliknięcie w interfejs |
| Cel | Pokazuje, jaki warunek biznesowy lub techniczny ma zostać sprawdzony | Jedno zdanie wystarczy, jeśli jest konkretne |
| Precondition | Określa stan, który musi istnieć przed startem testu | Wpisz tylko to, co faktycznie jest potrzebne |
| Dane testowe | Eliminują zgadywanie podczas wykonania | Podawaj wartości, które mają znaczenie dla wyniku |
| Kroki | Prowadzą osobę wykonującą test przez scenariusz | Każdy krok powinien być prosty i jednoznaczny |
| Oczekiwany wynik | Definiuje, co uznajemy za sukces lub porażkę | Opisuj to, co da się zaobserwować lub zmierzyć |
| Priorytet | Pomaga ustawić kolejność wykonania testów | Rozróżniaj krytyczne ryzyka od przypadków pobocznych |
| Powiązanie z wymaganiem | Daje ślad audytowy i ułatwia coverage | Łącz test z user story, wymaganiem lub defektem |
| Wynik wykonania | Przechowuje rezultat uruchomienia testu | Przydaje się szczególnie w narzędziu do zarządzania testami |
Jeśli potrzebujesz pełnej instrukcji, trzymaj się zasady „na tyle szczegółowo, by ktoś obcy mógł wykonać test bez pytań, ale nie tak szczegółowo, by lista kroków starzała się po każdej zmianie interfejsu”. To zdanie dobrze oddaje różnicę między użytecznym przypadkiem testowym a dokumentem, który tylko wygląda formalnie. Z tego miejsca naturalnie przechodzimy do samego procesu pisania.
Jak pisać przypadek testowy krok po kroku
Ja zwykle zaczynam nie od formularza, tylko od pytania: co tu może pójść źle i co jest naprawdę ważne dla użytkownika lub biznesu. Dopiero potem rozbijam to na konkretne przypadki. Dzięki temu testy nie robią się przypadkową listą kliknięć, tylko sensownym zestawem kontroli.
-
Weź punkt wyjścia z wymagania albo user story
Najpierw ustal, co system ma robić. Jeśli masz wymaganie „użytkownik może zresetować hasło”, to nie piszesz jeszcze o wszystkich możliwych ekranach, tylko o tym, jakie zachowania trzeba potwierdzić.
-
Rozbij funkcję na istotne warunki
Sprawdź ścieżkę pozytywną, błędy walidacji, granice danych i wyjątki. W przypadku logowania będzie to na przykład poprawny login, błędne hasło, pusty formularz, konto zablokowane i przekroczenie limitu prób.
-
Dobierz technikę projektowania testów
Tu bardzo pomagają klasy równoważności i analiza wartości brzegowych. Pierwsza technika redukuje liczbę testów, gdy wiele danych zachowuje się podobnie, a druga pilnuje granic, na których błędy wychodzą najczęściej.
-
Zapisz kroki tak, by nie było pola do interpretacji
Nie pisz „przejdź przez proces logowania”, jeśli w rzeczywistości ktoś ma wpisać adres e-mail, hasło i kliknąć konkretny przycisk. Kroki powinny być krótkie, ale nie mglisto ogólne.
-
Określ oczekiwany rezultat jako coś obserwowalnego
Zamiast „system działa poprawnie” napisz „użytkownik widzi panel główny, a w prawym górnym rogu pojawia się jego nazwa”. To drobna różnica, ale właśnie ona odróżnia test od luźnej notatki.
-
Dodaj priorytet i powiązanie z ryzykiem
Nie każdy test musi być wykonywany w tym samym tempie i z tą samą częstotliwością. Najpierw powinny iść te przypadki, które zabezpieczają krytyczne ścieżki biznesowe albo obszary najbardziej podatne na regresję.
Przykład: dla pola z numerem telefonu nie pisałbym jednego testu „sprawdź walidację”, tylko osobno przypadek dla poprawnego numeru, osobno dla zbyt krótkiego ciągu i osobno dla znaków niedozwolonych. Dzięki temu od razu wiadomo, co dokładnie działa, a co nie. Następny krok to decyzja, jak bardzo szczegółowy ma być taki zapis.
Jak dobrać poziom szczegółowości bez przeładowania dokumentacji
W testowaniu szczegółowość bywa pułapką. Zbyt lakoniczny zapis zmusza do zgadywania, a zbyt rozbudowany staje się ciężarem przy każdej zmianie produktu. Ja najczęściej wybieram poziom szczegółowości zależnie od tego, jak stabilny jest obszar, kto będzie wykonywał test i czy przypadek ma żyć tylko na potrzeby ręcznego sprawdzenia, czy także automatyzacji.
| Sytuacja | Lepszy poziom szczegółowości | Dlaczego |
|---|---|---|
| Stabilny, prosty proces | Krótki scenariusz z jasnym wynikiem | Nie ma sensu przepisywać oczywistości przy każdej wersji produktu |
| Interfejs zmienia się często | Zapis oparty na celu, nie na dokładnym klikaniu | Zmiany UI nie powinny wymuszać ciągłego przepisywania testów |
| Obszar krytyczny biznesowo | Więcej precyzji, danych i warunków wstępnych | Ryzyko błędu jest zbyt duże, żeby zostawiać miejsce na interpretację |
| Przypadek pod automatyzację | Opis celu i danych, mniej technicznych detali interfejsu | Skrypt i tak załatwi mechanikę wykonania |
| Nowy członek zespołu wykonuje testy | Nieco większa instrukcyjność | Zmniejsza liczbę pytań i błędnych założeń |
W praktyce dobrze działa zasada: im większe ryzyko i im mniej przewidywalny obszar, tym więcej kontekstu trzeba dopisać. Przy prostych ścieżkach nie ma jednak potrzeby zamieniać każdego testu w instrukcję obsługi. To prowadzi nas do zarządzania bazą testów, bo tam najczęściej ujawnia się koszt nadmiernej szczegółowości.
Jak zarządzać testami, gdy przypadków przybywa
Sama umiejętność pisania testów nie wystarczy, jeśli po kilku sprintach nikt nie wie, które przypadki są aktualne, które już nie mają sensu, a które zostały stworzone trzy razy pod różnymi nazwami. Zarządzanie testami polega dla mnie na utrzymaniu porządku w trzech rzeczach: zakresie, historii wykonania i powiązaniu z wymaganiami.Najbardziej praktyczne działania są zwykle bardzo proste: grupowanie przypadków w zestawy według funkcji, oznaczanie priorytetów, przypisywanie właścicieli oraz regularny przegląd martwych lub zduplikowanych testów. Jeśli zespół pracuje w modelu iteracyjnym, to po każdej większej zmianie trzeba też sprawdzić, czy istniejące testy nadal opisują aktualne zachowanie systemu. Bez tego baza szybko robi się głośna, ale mało użyteczna.
W dużych zespołach przydaje się dedykowane narzędzie do zarządzania testami, bo ułatwia wersjonowanie, raporty i śledzenie wykonania. Mniejszym zespołom czasem wystarcza dobrze prowadzony arkusz, ale tylko do momentu, gdy liczba testów i osób zaczyna rosnąć. Poniżej prosty podział, który dobrze oddaje różnicę.
| Obszar | Arkusz lub prosty rejestr | Dedykowane narzędzie |
|---|---|---|
| Wersjonowanie | Ręczne, podatne na pomyłki | Łatwiejsze do kontrolowania i audytu |
| Wykonanie testów | Trudniej śledzić historię uruchomień | Jasny status, wynik i osoba wykonująca |
| Powiązanie z wymaganiami | Często robione ad hoc | Zwykle wspierane bezpośrednio w strukturze projektu |
| Raportowanie | Wymaga ręcznego składania danych | Łatwiej zbudować widok pokrycia i regresji |
| Skalowanie zespołu | Im więcej osób, tym większy chaos | Lepsza współpraca i mniej konfliktów wersji |
Moja praktyczna obserwacja jest taka: porządek w testach daje większy zwrot niż dokładanie kolejnych szablonów. Lepiej mieć mniej, ale aktualnych i dobrze opisanych przypadków, niż rozrastającą się bazę, której nikt nie ufa. A skoro tak, to warto zobaczyć, jakie błędy najczęściej niszczą wartość testów już na etapie ich tworzenia.
Najczęstsze błędy, które obniżają wartość testów
Wiele problemów z testami nie wynika z braku wiedzy, tylko z przyzwyczajeń. Zespół chce działać szybko, więc zapisuje wszystko w jednym przypadkach albo zostawia zbyt dużo domyślnych założeń. To oszczędza kilka minut dziś, ale kosztuje godziny przy pierwszej regresji.
- Zbyt ogólne kroki - jeśli opis brzmi jak hasło, a nie instrukcja, różni testerzy wykonają go inaczej.
- Niejasny oczekiwany wynik - „system działa poprawnie” nie nadaje się do weryfikacji.
- Łączenie wielu sprawdzeń w jednym przypadku - gdy jeden test sprawdza pięć rzeczy naraz, trudno ustalić, co naprawdę zawiodło.
- Brak danych granicznych - dużo błędów wychodzi właśnie na limitach, a nie w typowych ścieżkach.
- Powielanie tych samych testów pod innymi nazwami - baza puchnie, a pokrycie nie rośnie.
- Brak aktualizacji po zmianie produktu - stare testy tworzą fałszywe poczucie bezpieczeństwa.
- Skupienie wyłącznie na ścieżce pozytywnej - to najłatwiejszy sposób, żeby przegapić defekty w walidacji i obsłudze błędów.
Co naprawdę działa w zespole, który chce testować szybciej i pewniej
W 2026 najlepiej sprawdza się podejście hybrydowe: ręczne przypadki testowe tam, gdzie liczy się analiza, zmiany i eksploracja, oraz automatyzacja tam, gdzie ścieżka jest stabilna i często wraca w regresji. Nie próbowałbym automatyzować wszystkiego, bo to zwykle kończy się kosztownym utrzymaniem i frustracją zespołu. Lepiej zacząć od miejsc krytycznych i powtarzalnych.
Gdybym miał zostawić tylko kilka praktycznych zasad, wskazałbym te:
- Jednolity standard zapisu dla całego zespołu.
- Mniej testów, ale z lepszym pokryciem ryzyka.
- Regularne przeglądy i usuwanie martwych przypadków.
- Priorytetyzacja zamiast traktowania wszystkich testów tak samo.
- Ślad do wymagań, żeby każdy test miał swoje uzasadnienie.
W dobrze poukładanym procesie przypadek testowy nie jest papierem dla papieru, tylko narzędziem do szybszej decyzji: co działa, co wymaga poprawki i czego jeszcze nie sprawdzono. Jeśli zespół trzyma ten standard, testy zaczynają wspierać rozwój produktu, a nie go spowalniać.