Coraz więcej zespołów nie przegrywa dziś na jakości kodu, tylko na chaosie wokół testów: środowiskach, danych, raportach i odpowiedzialności za decyzję o wdrożeniu. To właśnie tutaj pojawia się test ops, czyli podejście, które traktuje testowanie jak ciągły, operacyjny proces, a nie pojedynczy etap przed releasem. W tym tekście pokazuję, jak to działa w praktyce, gdzie daje największy zwrot i jakie błędy najczęściej psują cały model QA.
Najważniejsze jest nie więcej testów, tylko lepszy przepływ decyzji o jakości
- TestOps łączy testowanie, automatyzację, środowiska i raportowanie w jeden spójny proces.
- Największa zmiana dotyczy odpowiedzialności: QA, development i operations pracują na wspólny wynik.
- Najlepiej działa tam, gdzie releasy są częste, a czas na feedback musi być krótki.
- Bez stabilnych środowisk i dobrych danych testowych nawet rozbudowana automatyzacja generuje szum.
- Skuteczność warto mierzyć czasem reakcji, flakiness i jakością triage, a nie samą liczbą testów.
Czym jest TestOps i dlaczego realnie zmienia QA
W praktyce patrzę na TestOps jak na warstwę operacyjną nad jakością. Nie chodzi tylko o to, by testy się uruchamiały, ale by cały proces był przewidywalny: wiadomo, co testujemy, gdzie testujemy, kto reaguje na awarię i na jakiej podstawie podejmujemy decyzję o wdrożeniu. To zmienia QA z roli „etapu kontrolnego” w rolę systemu zarządzania ryzykiem.
W klasycznym modelu testy często są „na końcu” i działają trochę jak bramka. W modelu TestOps są częścią przepływu dostarczania oprogramowania od samego początku. To oznacza mniej ręcznych przekazań, lepszą widoczność wyników i większą odpowiedzialność po stronie całego zespołu, nie tylko testerów. W polskich zespołach produktowych to ważne zwłaszcza tam, gdzie tempo wdrożeń rośnie szybciej niż liczba osób w QA.
| Obszar | Klasyczne QA | Podejście TestOps |
|---|---|---|
| Odpowiedzialność | Głównie zespół QA | Wspólna odpowiedzialność QA, dev i ops |
| Moment testowania | Przed wydaniem | Przez cały cykl delivery |
| Środowiska | Często ręcznie utrzymywane | Wersjonowane i odtwarzalne |
| Dane testowe | Ad hoc, czasem niestabilne | Maskowane, resetowalne, spójne |
| Raportowanie | Raport po wykonaniu testów | Stały sygnał do decyzji o ryzyku |
Jeśli to rozróżnienie wydaje się subtelne, w praktyce jest odwrotnie: właśnie ono decyduje, czy zespół naprawdę przyspiesza, czy tylko produkuje więcej testów. Skoro to już widać na poziomie idei, naturalnie trzeba przejść do tego, jak taki proces wygląda krok po kroku.
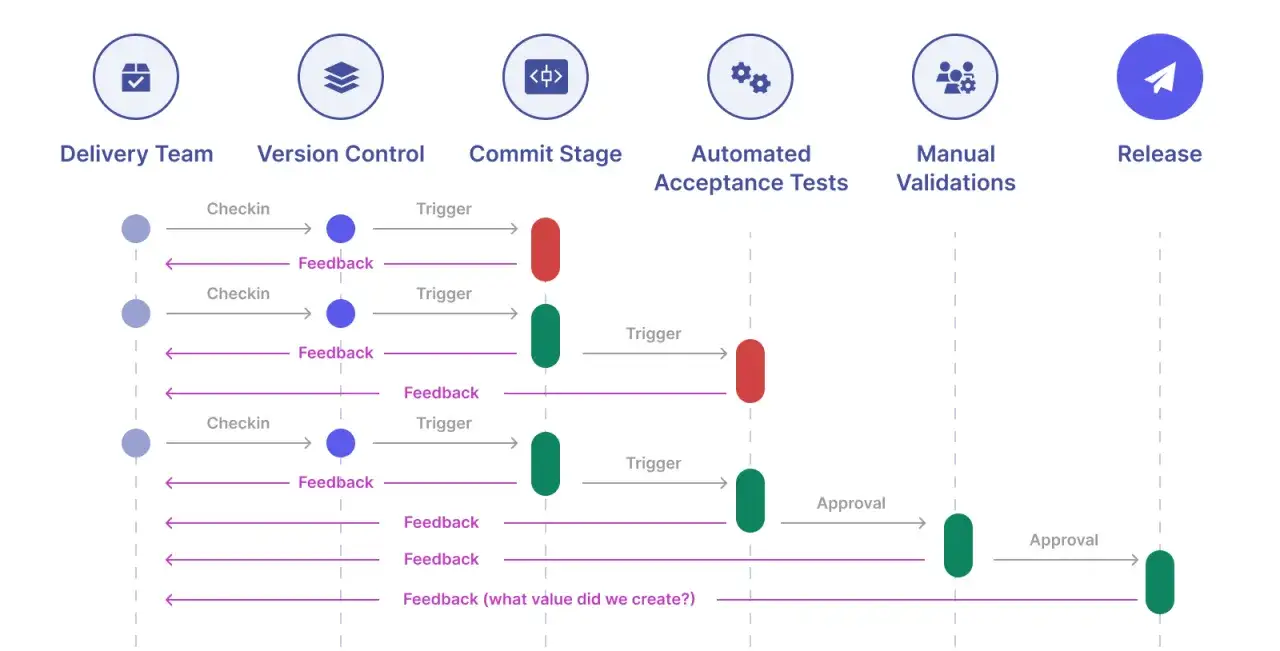
Jak wygląda proces od commita do decyzji o wdrożeniu
Najprościej rozbijam ten przepływ na kilka etapów. Najpierw kod trafia do systemu integracyjnego, potem uruchamiają się szybkie testy, a dopiero później szersza regresja i analizy jakościowe. Najważniejsze jest to, żeby każda faza miała swój cel: inne zadanie ma smoke test, inne test integracyjny, a jeszcze inne pełna regresja.
Od zmian w kodzie do pierwszego sygnału
Pierwszą linią obrony są krótkie testy, które powinny dawać wynik szybko, najlepiej w kilka minut. W praktyce zestaw smoke testów dobrze, jeśli mieści się w oknie 5-15 minut. Jeśli trwa dłużej, przestaje być szybkim filtrem i zaczyna spowalniać cały zespół. Tu chodzi o odpowiedź na pytanie: czy podstawowy przepływ nadal działa?
Od sygnału do decyzji
Jeśli szybka walidacja przejdzie, uruchamia się szersza warstwa testów: API, integracje, krytyczne ścieżki biznesowe i wybrane scenariusze end-to-end. Nie wszystko trzeba odpalać za każdym razem. Ja zwykle patrzę na to pragmatycznie: najpierw chronisz najbardziej ryzykowne obszary, dopiero potem rozszerzasz zasięg. Dzięki temu pipeline nie zamienia się w wielogodzinną blokadę.
Od decyzji do uczenia się
Sam wynik testu to za mało. Potrzebny jest jeszcze sensowny triage, czyli szybkie ustalenie, czy winny jest kod, dane, środowisko czy sam test. Jeśli zespół nie potrafi odpowiedzieć na to pytanie tego samego dnia, sygnał jakości robi się bezużyteczny. W dobrze ułożonym procesie TestOps wynik testu nie kończy rozmowy, tylko ją porządkuje.
Ten przepływ działa jednak tylko wtedy, gdy za kulisami stoją właściwe elementy techniczne i organizacyjne. I właśnie one najczęściej rozstrzygają o sukcesie albo porażce.
Co musi się spiąć, żeby automatyzacja nie zaczęła kłamać
Największy błąd, jaki widzę, polega na myleniu automatyzacji z dojrzałością procesu. Testy można mieć świetne, a mimo to generować fałszywy obraz jakości, jeśli środowiska są niestabilne, dane nieodtwarzalne, a raporty nie pokazują źródła problemu. W TestOps nie wystarczy „mieć testy” - trzeba jeszcze umieć je utrzymać.
Środowiska testowe
Środowisko powinno dać się odtworzyć, a nie tylko „jakoś postawić”. Tu najlepiej działają podejścia oparte na automatycznym provisioningu, wersjonowanych konfiguracjach i możliwie dużej zgodności z produkcją. Im większa różnica między środowiskiem testowym a produkcyjnym, tym mniej zaufania do wyników. Jeśli przygotowanie środowiska trwa dwa dni, to proces nie jest ciągły, tylko ręcznie sklejamy go z przypadków.
Dane testowe
Dobre dane testowe to nie luksus, tylko warunek stabilności. Trzeba umieć je odświeżać, maskować dane wrażliwe i tworzyć zestawy, które można bezpiecznie powtarzać. W praktyce dobrze sprawdza się podział na trzy poziomy: dane bazowe do smoke, dane scenariuszowe do testów funkcjonalnych i dane specjalne do przypadków granicznych. Bez tego każdy run zaczyna wyglądać inaczej, a zespół traci czas na zgadywanie.
Automatyzacja i selekcja testów
Nie automatyzuję wszystkiego, bo to zwykle kończy się przeciążeniem utrzymaniowym. Lepiej zacząć od stabilnych, krytycznych ścieżek: logowania, płatności, integracji z kluczowymi systemami, zapisów danych i procesów biznesowych, które są drogie w awarii. Flaky tests, czyli testy niestabilne, trzeba eliminować szybko. Gdy około 5% uruchomień daje losowe błędy, ludzie zaczynają ignorować wynik zamiast na niego reagować.
Obserwowalność i raportowanie
Raport nie powinien być zrzutem ekranu z czerwonymi i zielonymi kropkami. Potrzebujesz kontekstu: który commit, które środowisko, jaka wersja danych, który krok padł i kto ma kolejny ruch. To właśnie obserwowalność jakości robi największą różnicę, bo skraca triage z godzin do minut. Bez tego nawet duża liczba automatycznych testów nie daje przewagi.
Przeczytaj również: QA - Zbuduj Skuteczny Proces i Ogranicz Błędy w Projekcie
Odpowiedzialność
Jeśli tylko QA „ma testy”, to proces szybko wraca do starego modelu silosów. Lepszy układ to taki, w którym developer rozumie wpływ zmian na testy, a operations dba o warunki ich wykonania. Wtedy testowanie przestaje być czyjąś prywatną działką i staje się wspólną usługą zespołu. A to prowadzi prosto do najczęstszych błędów wdrożeniowych.
Najczęstsze błędy, które psują cały model
W projektach, które obserwuję, problem rzadko polega na braku narzędzi. Częściej winne są złe nawyki organizacyjne: zbyt szeroka regresja, brak właściciela testów, chaos w danych i mylenie szybkości z dojrzałością. Jeśli te rzeczy nie są nazwane wprost, proces zaczyna się sypać po kilku sprintach.
- Traktowanie TestOps jak samej automatyzacji - wtedy rośnie liczba testów, ale nie rośnie jakość decyzji.
- Ręczne utrzymywanie środowisk - każda zmiana wymaga osobnej interwencji i cały pipeline się spowalnia.
- Brak ownershipu - nikt nie czuje się odpowiedzialny za stabilność testów, danych i raportów.
- Za szeroka regresja uruchamiana wszędzie - zabija czas feedbacku i marnuje zasoby na przypadki o niskiej wartości.
- Ignorowanie testów eksploracyjnych - automatyzacja nie zastępuje ludzkiego myślenia o ryzyku i nietypowych scenariuszach.
- Mierzenie liczby testów zamiast skuteczności procesu - to jeden z najgorszych KPI, bo dobrze wygląda na slajdzie, a słabo działa w rzeczywistości.
Wszystkie te błędy mają wspólny mianownik: zespół widzi aktywność, ale nie widzi realnego wpływu na decyzję o wydaniu. Dlatego sensownie jest też odpowiedzieć sobie, kiedy taki model naprawdę się opłaca, a kiedy można zacząć skromniej.
Kiedy TestOps daje największy zwrot, a kiedy można zaczekać
Nie każdy zespół potrzebuje pełnej dojrzałości od pierwszego dnia. Ja zwykle patrzę na częstotliwość releasów, liczbę integracji i koszt błędu produkcyjnego. Im bardziej złożony produkt i im krótszy cykl wydawniczy, tym większy sens ma operacyjne podejście do testów.
| Sytuacja | Czy TestOps ma sens | Dlaczego |
|---|---|---|
| Codzienne lub kilka wdrożeń tygodniowo | Tak, bardzo duży | Bez szybkiego feedbacku zespół traci kontrolę nad ryzykiem |
| Wiele integracji API i mikroserwisów | Tak | Najwięcej błędów pojawia się na styku systemów |
| Branże regulowane lub z wysokim kosztem błędu | Tak | Trzeba lepiej dokumentować, kto i na jakiej podstawie dopuścił release |
| Mały zespół z rzadkimi wdrożeniami | Niekoniecznie od razu | Wystarczy lekka automatyzacja i dobra dyscyplina QA |
W małych projektach pełny model może być po prostu zbyt ciężki. Wtedy rozsądniej zacząć od kilku stabilnych testów krytycznych, sensownego zarządzania danymi i jednego miejsca do raportowania wyników. Dopiero później dokładać kolejne warstwy, zamiast od razu budować cały system naraz. Jeśli chcesz, żeby taki proces nie był tylko ładnym konceptem, trzeba go też mierzyć.
Jak mierzyć skuteczność bez pozornych KPI
Najgorsze metryki to te, które wyglądają profesjonalnie, ale nie pomagają podjąć decyzji. Liczba uruchomionych testów albo procent automatyzacji brzmi dobrze, tylko że niewiele mówi o tym, czy zespół szybciej i pewniej dowozi jakość. Ja wolę metryki, które skracają rozmowę o ryzyku.
| Metryka | Po co ją śledzić | Dobry sygnał |
|---|---|---|
| Czas do pierwszego feedbacku | Pokazuje, jak szybko zespół widzi problem | Smoke testy zamykają się w 5-15 minutach |
| Flaky rate | Mówi, czy testom można ufać | Niski i stale redukowany, najlepiej poniżej kilku procent |
| Czas triage | Pokazuje, jak szybko zespół rozumie przyczynę awarii | W tym samym dniu roboczym, nie po kilku dniach |
| Stabilność środowisk | Wskazuje, czy problem leży w produkcie, czy w infrastrukturze | Środowisko rzadko blokuje pipeline |
| Defect leakage | Mierzy, ile błędów przechodzi dalej niż powinno | Trend spadkowy po kolejnych iteracjach |
Jeśli te wskaźniki są złe, nie ma sensu maskować problemu większą liczbą testów. Lepiej najpierw poprawić źródło chaosu: zwinąć czas feedbacku, ustabilizować środowiska i zrobić porządek w triage. Właśnie z tego powodu rozsądny start jest ważniejszy niż efektowne wdrożenie.
Co warto zbudować najpierw, żeby TestOps zadziałał
Gdybym zaczynał taki proces od zera, nie próbowałbym wdrażać wszystkiego równocześnie. Najpierw wybrałbym jeden strumień dostarczania o najwyższym ryzyku i wokół niego zbudowałbym podstawową dyscyplinę: stabilne środowisko, powtarzalne dane, krótki zestaw testów krytycznych i jasne zasady reakcji na awarie.
- Wyznacz jeden krytyczny flow biznesowy, który chcesz chronić w pierwszej kolejności.
- Ogranicz zestaw smoke do absolutnego minimum i pilnuj, by działał szybko.
- Wprowadź odtwarzalne dane testowe oraz reset środowiska po każdym ważnym runie.
- Ustal jedno źródło prawdy dla raportów i triage, zamiast rozpraszać wyniki po wielu narzędziach.
- Przypisz właścicieli: kto naprawia test, kto poprawia środowisko, kto rozstrzyga konflikt interpretacji.
- Dopiero potem rozszerzaj zakres automatyzacji na kolejne warstwy produktu.
Jeśli ten porządek zadziała, zespół zacznie szybciej ufać wynikom, a mniej czasu pójdzie na gaszenie niejasnych błędów. I właśnie o to chodzi: test ops ma skracać drogę od wykrycia problemu do decyzji, a nie dokładać kolejny poziom złożoności. Gdy ten warunek jest spełniony, QA przestaje być wąskim gardłem i staje się przewidywalnym elementem procesu dostarczania.