Najważniejsze informacje, które warto zapamiętać
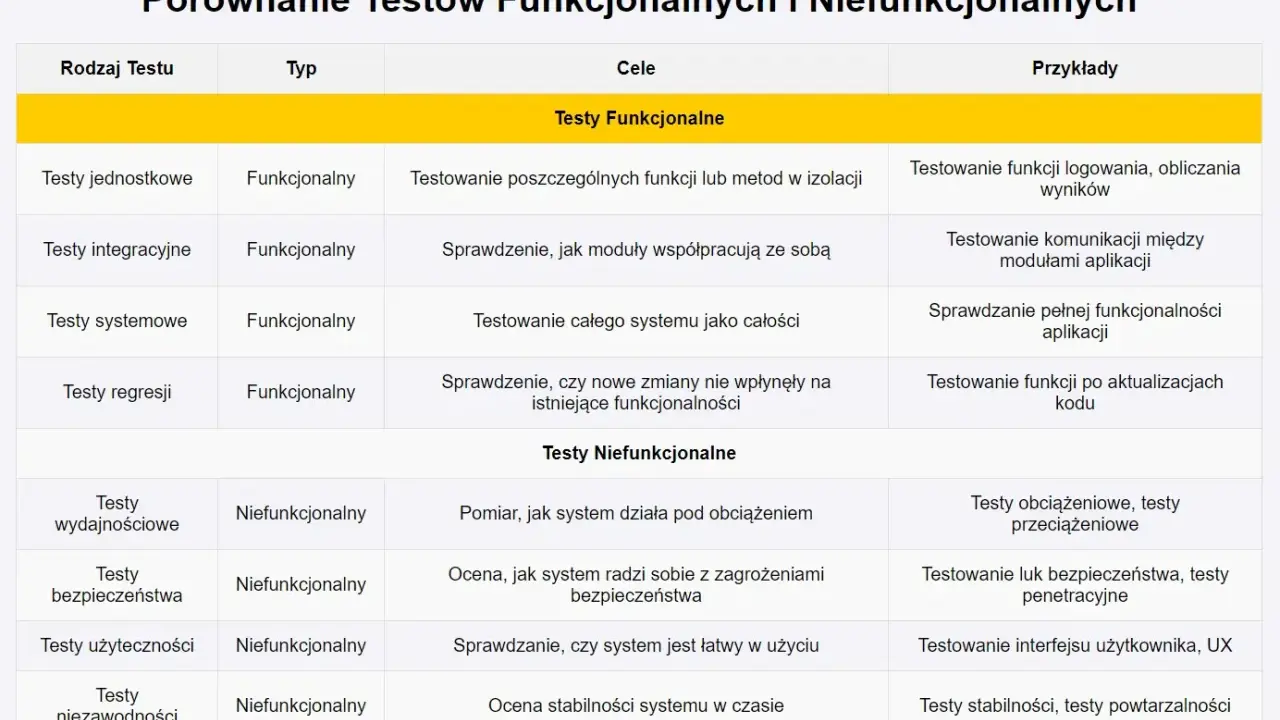
- To sprawdzanie, czy system realizuje funkcje opisane w wymaganiach i scenariuszach użytkownika.
- Najlepsze efekty dają techniki oparte na specyfikacji, danych brzegowych i przepływach stanów.
- Warto łączyć ręczne sprawdzanie nowych ścieżek z automatyzacją regresji i powtarzalnych przypadków.
- Największe straty powodują niejasne oczekiwania, brak danych testowych i ograniczenie się do „szczęśliwej ścieżki”.
- Proces powinien kończyć się czytelnym raportem defektów, a nie samym „przeszło/nie przeszło”.
Czym są testy funkcjonalne i co sprawdzają
W praktyce chodzi mi o sprawdzenie, czy system zachowuje się zgodnie z wymaganiami: przyjmuje właściwe dane, wykonuje właściwą akcję i zwraca oczekiwany wynik. Patrzę na aplikację z perspektywy użytkownika albo procesu biznesowego, więc interesuje mnie efekt, a nie to, jak program jest napisany od środka.
Dobry przykład to formularz rejestracji, koszyk zakupowy, zmiana hasła albo generowanie faktury. Jeśli użytkownik wpisze poprawne dane, system powinien przejść dalej; jeśli dane są błędne, powinien zareagować jasno i przewidywalnie. Właśnie tu najłatwiej wychwycić luki w wymaganiach, nie tylko błędy w kodzie.
Trzeba też rozróżnić zakres. Taki test nie ma zastępować sprawdzania wydajności, bezpieczeństwa czy architektury. On odpowiada na prostsze, ale kluczowe pytanie: czy funkcja działa tak, jak powinna.
Jeśli zakres jest dobrze nazwany, łatwiej dobrać technikę wykonania i uniknąć chaosu w scenariuszach.
Jakie techniki dają najlepszy efekt
Nie próbuję sprawdzać wszystkiego „na czuja”. W praktyce najlepiej działają techniki projektowania przypadków testowych, które pomagają ograniczyć liczbę testów, ale nadal dobrze pokrywają ryzyko.| Technika | Kiedy działa najlepiej | Co daje | Na co uważać |
|---|---|---|---|
| Podział na klasy równoważności | Gdy dane wejściowe można podzielić na grupy o podobnym zachowaniu | Zmniejsza liczbę przypadków bez utraty sensu pokrycia | Nie zakładaj, że jedna próbka zawsze reprezentuje całą klasę |
| Analiza wartości brzegowych | Przy limitach, zakresach i walidacjach formularzy | Łapie błędy, które najczęściej wychodzą na granicy dopuszczalnych danych | Łatwo pominąć wartości tuż obok progu, a to one często ujawniają problem |
| Tabele decyzyjne | Przy wielu regułach biznesowych i kombinacjach warunków | Porządkuje zależności między danymi, uprawnieniami i wynikami | Przy zbyt dużej liczbie warunków tabela robi się nieczytelna |
| Przejścia stanów | Gdy system zmienia status, np. zamówienie, subskrypcja, zgłoszenie | Pokazuje poprawne i błędne ścieżki między stanami | Warto opisać zarówno dozwolone, jak i niedozwolone przejścia |
| Testowanie eksploracyjne | Gdy wymagania są niepełne albo ryzyko jest jeszcze niejasne | Pomaga szybko odkryć problemy, których nie widać w sztywnym scenariuszu | Bez notatek i celu łatwo zamienić je w chaotyczne klikanie |
Ja zwykle łączę kilka technik zamiast trzymać się jednej. Dzięki temu testy nie są ani przypadkowe, ani przesadnie ciężkie do utrzymania, a to prowadzi prosto do pytania, jak ułożyć sam proces pracy.
Jak wygląda proces od wymagań do raportu
W dobrze prowadzonym projekcie nie zaczynam od klikania w aplikację. Najpierw porządkuję wymagania, bo bez tego nawet dobry test może sprawdzać coś innego, niż naprawdę trzeba.
- Odczytuję wymagania i kryteria akceptacji. Szukam nie tylko funkcji, ale też wyjątków, limitów i warunków brzegowych.
- Układam scenariusze. Przekształcam oczekiwania biznesowe w konkretne kroki, dane wejściowe i oczekiwane wyniki.
- Przygotowuję dane testowe. Jeśli dane są słabe, wynik też będzie słaby, nawet gdy sama aplikacja działa poprawnie.
- Wykonuję przypadki i zapisuję rezultat. Tu ważna jest powtarzalność: ten sam scenariusz powinien dać ten sam efekt przy kolejnym uruchomieniu.
- Raportuję defekty precyzyjnie. Dobrze opisany błąd zawiera kroki odtworzenia, oczekiwany wynik, rzeczywisty wynik oraz wpływ na użytkownika.
Najlepsze raporty nie są najdłuższe, tylko najczytelniejsze. Jeśli zespół potrafi szybko odtworzyć problem, naprawa rusza bez zbędnej wymiany maili, a ja mogę przejść do kolejnej decyzji: co warto zautomatyzować.
Kiedy ręczne sprawdzanie ma więcej sensu niż automatyzacja
Nie każde sprawdzanie trzeba automatyzować i to jest jedna z ważniejszych lekcji. Automatyzacja świetnie działa tam, gdzie scenariusz powtarza się często, a oczekiwany wynik jest jednoznaczny. Ręczne podejście lepiej sprawdza się tam, gdzie logika wciąż się zmienia albo trzeba ocenić coś bardziej „ludzkiego”, na przykład spójność interfejsu.
| Podejście | Najlepsze zastosowanie | Plus | Ograniczenie |
|---|---|---|---|
| Ręczne | Nowe funkcje, eksploracja, ocena zachowania w nieoczywistych sytuacjach | Szybko pokazuje problemy jakościowe i biznesowe | Trudniejsze do skalowania przy dużej regresji |
| Automatyczne | Regresja, krytyczne ścieżki, API, stabilne formularze | Przyspiesza powtarzalne sprawdzenia i zmniejsza ryzyko pomyłki człowieka | Wymaga utrzymania, a słabe skrypty szybko stają się balastem |
| Hybrydowe | Większość zespołów produktowych | Łączy elastyczność z szybkim feedbackiem | Wymaga dyscypliny w podziale odpowiedzialności |
W praktyce automatyzuję to, co ma być stabilne i często wraca w regresji, a ręcznie sprawdzam obszary wrażliwe na zmiany albo takie, w których ważna jest interpretacja. To pozwala zachować sens metod zamiast budować kosztowną maszynę do uruchamiania skryptów.
Najczęstsze błędy, które zaniżają wartość testowania
- Sprawdzanie wyłącznie „happy path”. System może przejść idealny scenariusz i jednocześnie wywracać się na błędnych danych, limitach albo wyjątkach.
- Brak danych brzegowych. Jeśli testujesz tylko typowe wartości, tracisz najwięcej sygnałów o realnych problemach.
- Niejasne oczekiwania. Bez jednoznacznego wyniku końcowego trudno stwierdzić, czy przypadek przeszedł, czy tylko „wyglądał dobrze”.
- Mieszanie sprawdzania funkcji z oceną estetyki. UI jest ważny, ale sam ładny ekran nie oznacza, że proces działa poprawnie.
- Za mało informacji w zgłoszeniu błędu. Jeśli nie ma kroków odtworzenia, środowiska i danych, naprawa zwykle się wydłuża.
- Testowanie w niestabilnym środowisku. Gdy system, dane albo integracje zmieniają się bez kontroli, wynik testu traci wartość diagnostyczną.
Te błędy są powtarzalne, bo często wynikają z pośpiechu, a nie ze złej woli. Żeby ich uniknąć, trzeba jeszcze przed startem projektu ustawić kilka prostych zasad współpracy.
Co przygotować, żeby testowanie wspierało produkt od pierwszego sprintu
Jeśli mam wskazać rzeczy, które naprawdę robią różnicę, to zaczynam od czterech elementów: jasnych kryteriów akceptacji, stabilnego środowiska testowego, dobrych danych i ustalonej odpowiedzialności za poprawki. Bez tego nawet dobrze napisane scenariusze szybko tracą wartość.
- Ustal, co dokładnie oznacza „działa poprawnie” dla każdej kluczowej funkcji.
- Oddziel przypadki krytyczne od pobocznych, żeby nie rozmywać priorytetów.
- Wprowadź krótką regresję po zmianach w logice biznesowej.
- Traktuj defekt jako wspólny problem produktu, a nie tylko „błąd do naprawienia”.
- Upewnij się, że zespół wie, kiedy wynik testu jest blokadą, a kiedy tylko obserwacją do dalszej analizy.
Jeżeli ten fundament jest ustawiony, sprawdzanie funkcji przestaje być formalnością, a staje się realnym narzędziem kontroli jakości. I właśnie wtedy daje zespołowi najwięcej: mniej domysłów, szybsze decyzje i mniej kosztownych poprawek po wdrożeniu.