Dobrze zaprojektowane testy na poziomie jednostek pozwalają wykryć błąd tam, gdzie naprawdę powstaje, zamiast polować na niego w całej aplikacji. W praktyce to jedna z najtańszych metod zwiększania pewności zmian, zwłaszcza gdy kod rośnie, a wdrożenia są częste. Poniżej wyjaśniam, czym są takie testy, kiedy działają najlepiej, jak je pisać i gdzie kończą się ich możliwości.
Najważniejsze informacje o testach jednostkowych
- Sprawdzają małe fragmenty kodu w izolacji, bez uruchamiania całego systemu.
- Ich największą przewagą są szybkość, stabilność i łatwe wskazanie źródła błędu.
- Najlepszy test opisuje zachowanie, a nie wewnętrzną implementację.
- Jeśli trzeba mocno podmieniać wszystko wokół, kod zwykle wymaga lepszej separacji odpowiedzialności.
- Nie zastępują integracji ani testów end-to-end, tylko budują dla nich solidną bazę.
Czym są testy na poziomie jednostek i co naprawdę sprawdzają
W praktyce chodzi o sprawdzenie pojedynczej funkcji, klasy albo małego modułu w oderwaniu od reszty aplikacji. Taki test nie powinien potrzebować prawdziwej bazy danych, sieci, zegara systemowego ani całego procesu wdrożeniowego, bo wtedy przestaje być szybkim testem izolowanym i zaczyna przypominać inny poziom weryfikacji.
Najważniejsze jest tutaj pytanie: czy dana jednostka zachowuje się zgodnie z oczekiwaniem, gdy dostanie konkretny input? Jeśli funkcja ma policzyć rabat, przekształcić dane, zwrócić błąd walidacji albo wybrać właściwą ścieżkę biznesową, to właśnie to powinien pokazać test. Nie chodzi o sprawdzanie każdej linijki, tylko o potwierdzenie istotnego zachowania.
Dobry test zwykle trzyma się prostego schematu: przygotuj dane, wykonaj akcję, sprawdź wynik. To brzmi banalnie, ale ta prostota jest zaletą, nie ograniczeniem. Gdy test staje się trudny do przeczytania, najczęściej problem leży już nie w nim samym, tylko w strukturze kodu produkcyjnego. Gdy to już jasne, łatwiej zrozumieć, skąd bierze się ich przewaga w codziennej pracy.
Dlaczego ta warstwa testów tak dobrze przyspiesza pracę zespołu
Największy zysk daje szybkość informacji zwrotnej. Jeśli po zmianie kodu od razu widzę, co się zepsuło, mogę poprawić błąd zanim rozpłynie się po całym systemie. W dobrze utrzymanym projekcie takie testy uruchamiają się w milisekundach lub pojedynczych setkach milisekund, więc nadają się do codziennej pracy i do pipeline'ów CI.
Druga korzyść to lokalizacja problemu. Gdy test pada w małym, izolowanym zakresie, nie muszę od razu przeglądać logów z kilku usług, sprawdzać konfiguracji środowisk ani odtwarzać scenariusza ręcznie. Google Testing Blog od lat zwraca uwagę, że dobry test ma być szybki i pomagać w namierzeniu miejsca awarii. To dokładnie ten efekt, którego szuka zespół rozwijający produkt pod presją czasu.
Jest jeszcze trzeci aspekt, często niedoceniany: odwaga refaktoryzacji. Dobre testy pozwalają porządkować kod bez lęku, że każda zmiana rozbije kilka obszarów aplikacji naraz. Z mojego doświadczenia to właśnie tutaj pojawia się największa różnica między projektem „działającym” a projektem, który naprawdę da się rozwijać. Skoro znamy wartość, przejdźmy do praktyki: jak taki test zbudować, żeby był czytelny i odporny na zmiany.
Jak pisać je tak, żeby pomagały, a nie przeszkadzały
Najpierw opisuj zachowanie
Test powinien mówić, co ma się wydarzyć, a nie jak kod to robi. Jeśli po drobnej zmianie wewnętrznej test zaczyna się sypać, mimo że zachowanie pozostało poprawne, to znak, że zbyt mocno przywiązał się do implementacji. W praktyce lepiej sprawdza się weryfikacja wyniku niż kontrolowanie każdego kroku pośredniego.
Trzymaj się prostego układu arrange, act, assert
Ten schemat porządkuje myślenie i ułatwia czytanie testu po miesiącu albo po pół roku. Najpierw przygotowuję dane wejściowe i zależności, potem wywołuję badaną funkcję, a na końcu sprawdzam rezultat. Jeśli w teście zaczynają się mieszać wszystkie trzy kroki, zwykle trudno już powiedzieć, co dokładnie on udowadnia.
Przeczytaj również: Testy negatywne - Jak chronić produkt przed awariami?
Podmieniaj zależności tylko tam, gdzie to ma sens
W testach izolowanych często używa się trzech rodzajów podmian:
- Stub zwraca z góry ustalone dane, żeby test miał przewidywalne wejście.
- Mock sprawdza, czy kod wywołał zależność w oczekiwany sposób.
- Fake jest uproszczoną, działającą wersją komponentu, na przykład pamięciowym repozytorium.
Nie trzeba używać ich wszystkich naraz. W wielu przypadkach wystarczy jeden prosty stub i dobrze dobrane dane. Im mniej sztucznej konstrukcji wokół testu, tym mniejsze ryzyko, że sam stanie się trudniejszy w utrzymaniu niż kod, który ma chronić. Właśnie tu najczęściej pojawia się problem, więc warto przyjrzeć się błędom, które psują nawet dobrze brzmiące testy.
Najczęstsze błędy, które obniżają wartość testów
Największy błąd to testowanie szczegółów zamiast zachowania. Jeśli sprawdzam prywatne metody, kolejność wewnętrznych wywołań albo dokładny układ tymczasowych obiektów, bardzo łatwo zamienić test w delikatną konstrukcję, która łamie się przy każdym porządniejszym refaktorze. Lepszym kierunkiem jest test publicznego efektu działania.
Drugim problemem jest nadmierne mockowanie. Gdy pojedynczy test wymaga pięciu, sześciu albo ośmiu podmienionych współpracowników, zwykle sygnalizuje to zbyt silne sprzężenie klas albo zbyt rozdrobnioną odpowiedzialność. Taki test bywa trudny do zrozumienia, a czasem przestaje dawać zaufanie, bo weryfikuje już bardziej układ współpracowników niż realną regułę biznesową.Trzecia pułapka to zależność od czasu, losowości i zewnętrznych usług. Jeśli test raz przechodzi, a raz nie, nikt nie będzie chciał na nim opierać decyzji o wdrożeniu. Dlatego unikam prawdziwej sieci, rzeczywistej bazy danych i zegara systemowego, dopóki naprawdę nie są potrzebne. Czwarty błąd jest mniej spektakularny, ale równie kosztowny: ogólne nazwy testów, które nic nie mówią o scenariuszu. Nazwa powinna od razu wskazywać warunek i oczekiwany efekt. Na tym tle widać też, gdzie ta metoda stoi względem pozostałych poziomów testowania.
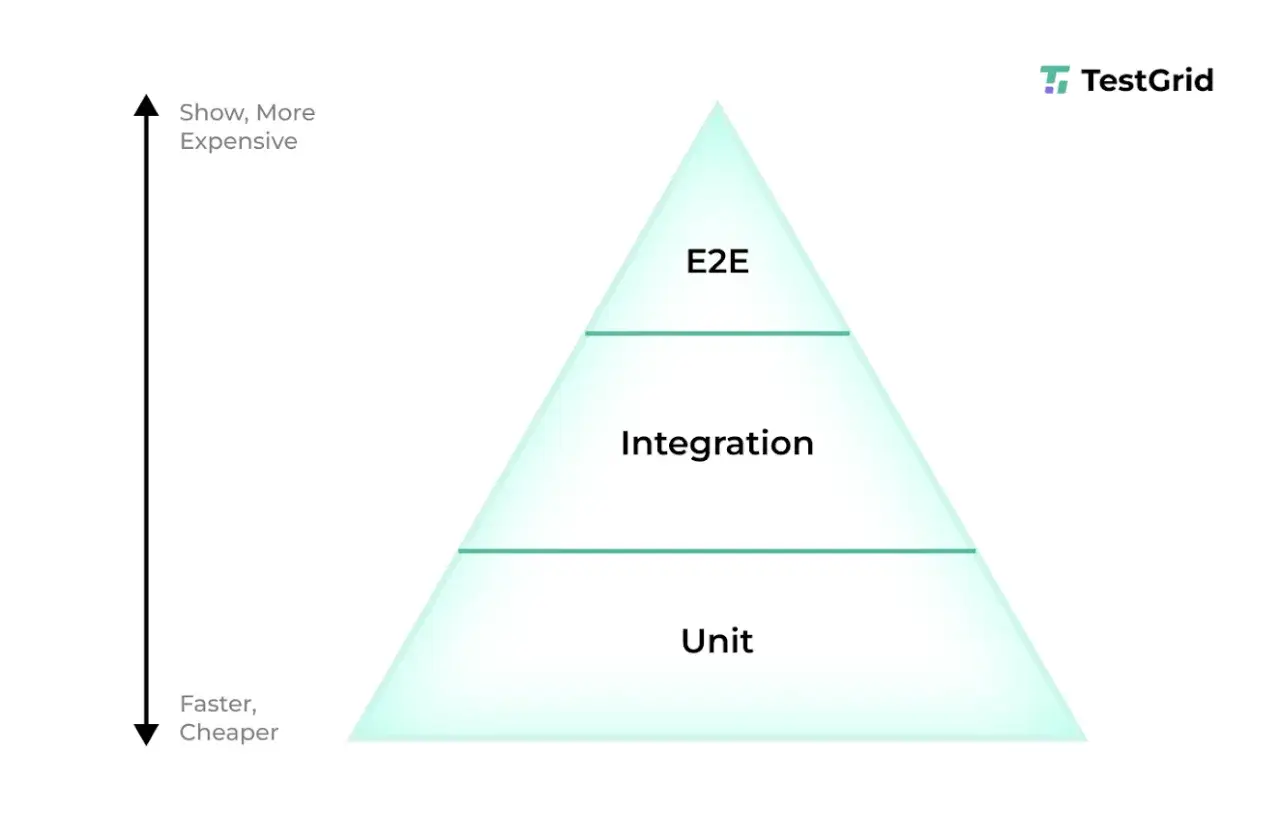
Jak wypadają na tle innych metod testowania
W praktyce najlepiej myśleć o tym w układzie piramidy testów: na dole jest dużo małych, szybkich sprawdzeń, wyżej mniej testów integracyjnych, a na samej górze tylko tyle testów pełnego przepływu, ile naprawdę trzeba. Taki układ nie jest dogmatem, ale dobrze oddaje koszt, tempo i wartość poszczególnych warstw.
| Poziom testu | Co sprawdza | Tempo | Największa zaleta | Główne ograniczenie |
|---|---|---|---|---|
| Testy na poziomie jednostek | Pojedynczą funkcję, klasę lub mały moduł w izolacji | Bardzo szybkie | Łatwo wskazują źródło błędu i świetnie nadają się do codziennej pracy | Nie pokazują, czy komponenty dobrze współpracują ze sobą |
| Testy integracyjne | Współpracę kilku elementów, na przykład serwisu z repozytorium albo bazą | Średnie | Wykrywają błędy na styku komponentów | Są wolniejsze i zwykle trudniejsze w utrzymaniu |
| Testy end-to-end | Cały przepływ użytkownika lub biznesowy | Najwolniejsze | Dają największą pewność, że scenariusz działa od początku do końca | Są podatne na flakiness i drogie w utrzymaniu |
To porównanie pokazuje prostą rzecz: każda warstwa ma inne zadanie. Jeśli próbujemy załatwić wszystko testami end-to-end, dostajemy wolny i kruchy zestaw. Jeśli opieramy się wyłącznie na testach izolowanych, możemy przegapić problemy z integracją. Rozsądny zestaw testów wykorzystuje moc każdej warstwy i nie obciąża jednej z nich całym ciężarem jakości. Z tego wynika najważniejsze pytanie: w jakich fragmentach systemu taka inwestycja zwraca się najmocniej.
Gdzie taka inwestycja zwraca się najszybciej
Najlepszy zwrot dają obszary, w których logika jest złożona, a błędy są drogie. Myślę tu przede wszystkim o regułach biznesowych, walidacjach, naliczaniu cen, przeliczeniach, parsowaniu danych oraz wszędzie tam, gdzie jedna mała zmiana może niepostrzeżenie zepsuć cały wynik. To są miejsca, w których test potrafi oszczędzić wiele godzin debugowania.
Szczególnie dobrze sprawdzają się też komponenty, które mają czyste wejście i wyjście: funkcje transformujące dane, klasy obsługujące reguły domenowe, parsery, kalkulatory, walidatory, formatery. W takich miejscach test nie tylko chroni kod, ale też dokumentuje intencję. Gdy ktoś nowy w zespole czyta test, od razu widzi, co jest dozwolone, co jest błędem i jakie są wyjątki od reguły.
Słabszy zwrot pojawia się tam, gdzie kod jest bardzo „cienki”, a większość roboty i tak wykonuje framework, zewnętrzny system albo interfejs użytkownika. W takich przypadkach lepiej nie wciskać na siłę dużej liczby testów izolowanych. Czasem sensowniejszy jest test integracyjny, który sprawdza realną współpracę z bazą, API albo kolejką wiadomości. Żeby to wykorzystać w praktyce, potrzebne są jeszcze proste zasady porządkujące cały zestaw.Proste zasady, które utrzymują zestaw testów w dobrej formie
- Jeden test powinien sprawdzać jeden scenariusz albo jedną regułę biznesową.
- Nazwa testu ma mówić, jaki był warunek wejściowy i jaki efekt jest oczekiwany.
- Jeśli test staje się długi i pełen przygotowań, najpierw sprawdź projekt kodu, a dopiero potem sam test.
- Unikaj prawdziwej sieci, dysku i czasu systemowego, jeśli nie są absolutnie potrzebne.
- Pokrycie kodu traktuj jako sygnał pomocniczy, nie jako cel sam w sobie.
- Gdy reguła biznesowa się zmienia, aktualizuj test razem z kodem, żeby dokumentacja nie zaczęła kłamać.
Jeśli miałbym sprowadzić cały temat do jednego zdania, powiedziałbym tak: dobre testy na poziomie jednostek nie mają imponować liczbą, tylko dawać szybki i wiarygodny sygnał, że rdzeń logiki nadal działa. To właśnie dlatego są tak ważne w nowoczesnym wytwarzaniu oprogramowania i tak dobrze wspierają pozostałe metody testowania.