
Cykl życia defektu, często opisywany jako bug life cycle, porządkuje drogę zgłoszenia od odkrycia problemu do jego zamknięcia. Dobrze ustawiony proces pomaga zespołowi testowemu szybciej reagować, precyzyjniej przekazywać kontekst do developmentu i nie gubić decyzji po drodze. W tym artykule pokazuję, jak ten mechanizm działa w praktyce, jakie ma etapy, kto odpowiada za każdy krok i jak go sensownie mierzyć w zarządzaniu testami.
Najważniejsze elementy procesu, które warto mieć pod kontrolą
- Defekt nie jest tylko „błędem do naprawy”, ale zgłoszeniem, które przechodzi przez kolejne stany i właścicieli.
- Najczęstsza ścieżka to: nowy, przypisany, w toku, naprawiony, do ponownego sprawdzenia i zamknięty.
- Nie każde zgłoszenie kończy się fixem. Część trafia do odrzucenia, duplikatów, odroczenia albo ponownego otwarcia.
- W dobrze prowadzonym procesie status mówi, gdzie jest zgłoszenie, a resolution wyjaśnia, dlaczego sprawę zakończono.
- Najbardziej użyteczne metryki to czas naprawy, odsetek reopenów, wiek otwartych defektów i liczba błędów uciekających na produkcję.
- Workflow powinien wspierać decyzje zespołu, a nie mnożyć formalności bez wpływu na jakość.
Czym jest cykl życia defektu i dlaczego nie każdy błąd przechodzi przez te same stany
W praktyce chodzi o uporządkowaną sekwencję kroków, przez które przechodzi zgłoszenie po wykryciu niezgodności między oczekiwanym a rzeczywistym wynikiem. Ja patrzę na to tak: statusy nie są dekoracją w narzędziu, tylko sygnałem, kto teraz jest właścicielem problemu i jaka decyzja ma zapaść dalej. To ważne, bo ten sam przypadek może być dla testerów oczywistym defektem, a dla zespołu technicznego duplikatem, błędną konfiguracją albo czymś, co trzeba odłożyć na później.
W dojrzałych zespołach nie miesza się także pojęć „status” i „rezultat”. Status mówi, gdzie jest zgłoszenie w przepływie pracy, a rezultat wyjaśnia, jak zakończono sprawę. Dzięki temu łatwiej analizować, ile problemów faktycznie naprawiono, ile odrzucono, a ile zostawiono na kolejną iterację. To właśnie od tej różnicy zależy, czy raport z defektów daje realny obraz jakości, czy tylko tworzy pozorny porządek.
Warto też pamiętać, że nie każdy zespół używa identycznych nazw. W jednym narzędziu zobaczysz „Open”, „In progress”, „Resolved” i „Closed”, w innym „Triaged” czy „Fixed”. Logika pozostaje jednak ta sama: od wykrycia do decyzji, od decyzji do weryfikacji, a potem do zamknięcia albo ponownego otwarcia. To prowadzi wprost do typowego przebiegu zgłoszenia.
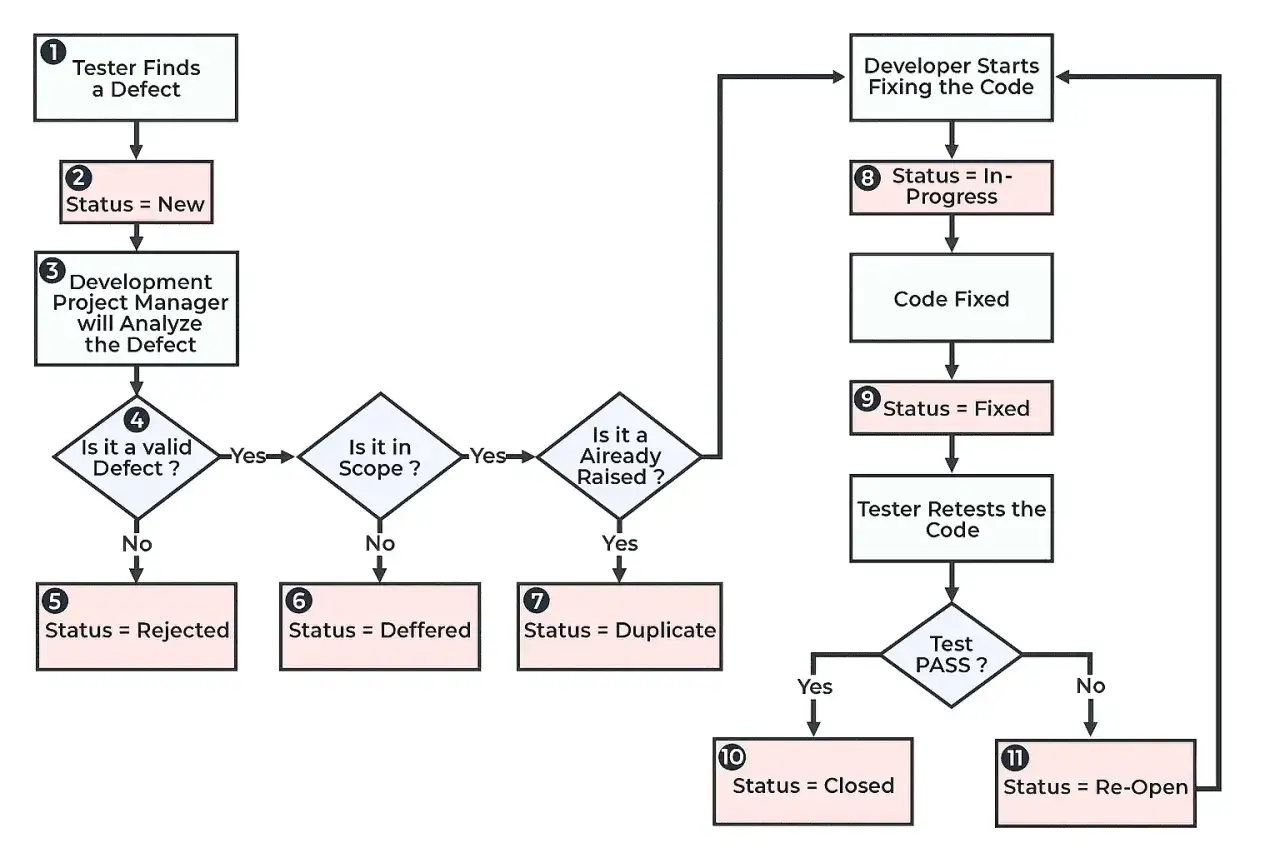
Jak wygląda typowy przepływ zgłoszenia krok po kroku
Najprostszy model zwykle wystarcza większości zespołów, o ile jest dobrze opisany i konsekwentnie stosowany. W praktyce zaczynam od kilku stanów, a dopiero później rozbudowuję workflow, jeśli raportowanie albo skala projektu tego naprawdę wymagają. Poniżej rozpisuję najczęstszy przebieg razem z tym, co dzieje się na każdym etapie.
| Stan | Co oznacza | Kto zwykle działa | Na co uważać |
|---|---|---|---|
| Nowy | Zgłoszenie właśnie powstało i czeka na pierwszą ocenę. | Tester lub osoba zgłaszająca | Bez dobrego opisu, kroków odtworzenia i środowiska zgłoszenie szybko traci wartość. |
| Przypisany lub zaklasyfikowany | Ktoś potwierdza, że zgłoszenie ma właściciela i trafia do właściwej ścieżki. | Test lead, QA manager, triage committee | Tu zapada decyzja, czy to naprawdę defekt, duplikat, czy coś do odroczenia. |
| W toku | Zespół analizuje problem, odtwarza go i przygotowuje poprawkę albo wyjaśnienie. | Developer, analityk, czasem QA | Jeśli nie da się odtworzyć błędu, trzeba szybko wrócić po dodatkowy kontekst. |
| Naprawiony | Zmiana została wdrożona lub przygotowana do testu weryfikacyjnego. | Developer | To jeszcze nie jest koniec. Bez retestu łatwo uznać problem za rozwiązany zbyt wcześnie. |
| Do ponownego sprawdzenia | Tester weryfikuje, czy poprawka faktycznie usuwa problem. | Tester, czasem QA automation | Warto sprawdzić też obszary sąsiednie, bo poprawka może wpływać na inne funkcje. |
| Zamknięty | Zgłoszenie osiągnęło stan końcowy i nie wymaga dalszej pracy. | Tester lub właściciel procesu | Przy zamknięciu dobrze zapisać powód, bo to później pomaga w analizie jakości. |
| Ponownie otwarty | Problem wrócił albo poprawka nie była wystarczająca. | Tester, QA, czasem support | Wysoki odsetek reopenów zwykle oznacza słabą weryfikację albo niepełny fix. |
Oprócz głównej ścieżki pojawiają się też poboczne zakończenia: odrzucony, duplikat, odroczony, niebędący błędem albo wymagający doprecyzowania. Ja traktuję je nie jak „kosz”, ale jak źródło informacji o jakości zgłoszeń, jakości wymagań i jakości samego procesu testowego. Jeśli takich przypadków jest dużo, problem zwykle nie leży wyłącznie w kodzie. To dobry moment, by sprawdzić, kto odpowiada za każdy etap i gdzie proces się zatyka.
Kto odpowiada za każdy etap i gdzie najczęściej pojawiają się tarcia
Cykl życia defektu działa dobrze tylko wtedy, gdy każdy wie, za co odpowiada. W typowym zespole tester wykrywa i raportuje problem, test lead albo osoba z triage decyduje o priorytecie i właścicielu, developer analizuje przyczynę i wdraża poprawkę, a QA wykonuje retest i kontrolę regresji. Przy większych organizacjach w grę wchodzi jeszcze product owner lub komisja triage, która ocenia koszt, ryzyko i sens naprawy w danym wydaniu.
- Tester powinien dostarczyć zgłoszenie, które da się odtworzyć bez zgadywania.
- Test lead lub QA manager musi rozróżnić priorytet od wagi błędu i przypisać odpowiednią ścieżkę.
- Developer odpowiada za analizę przyczyny, nie tylko za „zamknięcie ticketu”.
- Product owner decyduje, czy defekt naprawiamy teraz, czy przesuwamy do późniejszej wersji.
- QA weryfikuje poprawkę i sprawdza, czy nie pękło coś obok.
Najczęstsze tarcia zaczynają się tam, gdzie zespół miesza severity z priority. Severity mówi o wpływie na produkt lub użytkownika, priority o kolejności naprawy. Widziałem już przypadki, w których defekt o umiarkowanej wadze miał najwyższy priorytet, bo blokował release, i odwrotnie: bardzo poważny błąd trafiał do kolejki później, bo dotyczył rzadkiego scenariusza. To nie jest sprzeczność, tylko normalna decyzja biznesowo-techniczna.
Drugie klasyczne źródło problemów to zbyt słabe zgłoszenia. Jeśli opis nie zawiera środowiska, kroków odtworzenia, wyniku oczekiwanego i rzeczywistego, cały proces zwalnia. W efekcie developer traci czas na dopytywanie, QA wraca do wykonania tego samego testu, a zgłoszenie długo siedzi w stanie „w toku” bez realnego postępu. To prowadzi naturalnie do pytania, jak taki workflow skonfigurować, żeby pomagał, a nie przeszkadzał.
Jak sensownie ustawić workflow w Jira, Azure DevOps albo innym narzędziu
Ja zwykle zaczynam od prostego modelu, bo nadmiar statusów bardzo szybko zamienia proces w biurokrację. W narzędziach typu Jira bug może mieć własny workflow, a kolumny na boardzie tylko wizualizują to, co dzieje się pod spodem. To ważne rozróżnienie: board pokazuje przebieg pracy, ale to workflow definiuje reguły i odpowiedzialność.
| Kryterium | Workflow prosty | Workflow rozbudowany |
|---|---|---|
| Liczba stanów | 5-7 | 8-12 i więcej |
| Najlepsze zastosowanie | Zespoły agile, mniejsze produkty, szybkie wydania | Duże organizacje, środowiska regulowane, wiele zespołów |
| Plus | Szybkie decyzje i mało szumu | Lepsza kontrola audytu i więcej danych do analizy |
| Minus | Mniej precyzyjnego raportowania | Większe ryzyko przeciążenia procesu |
| Ryzyko | Zbyt duże uogólnienie | Zbyt wiele przekazań między rolami |
W praktyce pilnuję kilku zasad. Po pierwsze, jeden stan terminalny upraszcza analizę, bo końcowy rezultat jest wtedy jednoznaczny. Po drugie, kolejne stany powinny należeć do różnych ról, inaczej proces kręci się w miejscu. Po trzecie, nie dokładam do przejść obowiązkowych pól tylko dlatego, że „można”. Każde dodatkowe pole wydłuża czas obsługi i zwiększa szansę na niepotrzebny opór ze strony zespołu.
Jeśli pracujesz w Jira, sensownie jest też ujednolicić nazwy statusów dla różnych typów pracy, o ile organizacja na to pozwala. Dzięki temu raporty są czytelniejsze, a przełączanie się między bugami, taskami i user stories mniej męczące. Kiedy workflow jest już ustawiony, trzeba odpowiedzieć na ważniejsze pytanie: skąd wiadomo, że naprawdę działa dobrze?Jak mierzyć, czy proces naprawdę działa
Dobrze prowadzony cykl życia defektu powinien dawać się mierzyć, ale nie każda liczba jest równie użyteczna. W test management patrzę przede wszystkim na wskaźniki, które pokazują tempo reakcji, jakość naprawy i skuteczność wykrywania problemów przed wydaniem. Bez tego łatwo utknąć w raportach, które wyglądają dobrze, ale niczego nie poprawiają.
| Wskaźnik | Co pokazuje | Sygnał ostrzegawczy |
|---|---|---|
| Czas od zgłoszenia do zamknięcia | Jak szybko zespół przechodzi od wykrycia problemu do finału sprawy. | Rosnący czas oznacza wąskie gardło albo zbyt wolne decyzje triage. |
| Odsetek reopenów | Jak często problem wraca po rzekomej naprawie. | Wysoki poziom zwykle wskazuje na słabą poprawkę albo słaby retest. |
| Liczba otwartych defektów | Jak duży jest bieżący backlog błędów. | Jeśli rośnie szybciej niż liczba zamknięć, proces zaczyna się korkować. |
| Rozkład według severity | Jak poważne są problemy w danym obszarze produktu. | Dużo wysokich severity w krótkim czasie to sygnał o problemie z test coverage albo stabilnością komponentu. |
| Defekty uciekające na produkcję | Ile błędów zostało wykrytych dopiero po wydaniu. | Jeśli ten wskaźnik rośnie, testy nie domykają ryzyka. |
| Wiek otwartych defektów | Jak długo stare zgłoszenia czekają na decyzję lub naprawę. | Stare, nieruszone błędy zwykle oznaczają złe priorytety albo brak właściciela. |
Ja najczęściej patrzę na metryki łącznie, a nie osobno. Sam spadek liczby otwartych błędów nic nie znaczy, jeśli jednocześnie rośnie liczba reopenów albo defektów po release. Podobnie korelacja między otwartymi zgłoszeniami a liczbą wykonanych testów potrafi pokazać, czy zespół faktycznie redukuje ryzyko, czy tylko zamyka tickety szybciej niż wcześniej. Metryki mają pomagać w decyzji o kolejnym kroku, a nie być ozdobą na slajdzie.
Kiedy proces już jest mierzony, widać dużo wyraźniej, gdzie psuje go człowiek, a gdzie struktura workflow. To prowadzi do najczęstszych błędów, które w praktyce kosztują najwięcej czasu.
Najczęstsze błędy, które psują zarządzanie defektami
Największy problem nie tkwi zwykle w samym narzędziu, tylko w tym, jak zespół go używa. Z mojego doświadczenia najłatwiej zepsuć proces na czterech poziomach: za dużo statusów, za mało danych w zgłoszeniu, brak jasnych kryteriów zamknięcia i brak konsekwencji w triage. Każdy z tych błędów sam w sobie wydaje się drobny, ale razem potrafią zabić przejrzystość całego procesu.
- Zbyt wiele statusów sprawia, że nikt nie wie, co naprawdę dzieje się ze zgłoszeniem.
- Brak kroków odtworzenia zamienia analizę w zgadywanie.
- Zamykanie błędu bez retestu daje złudzenie postępu, a nie postęp.
- Mieszanie severity z priority powoduje niepotrzebne spory o kolejność naprawy.
- Traktowanie duplikatów i odrzuceń jako śmieci odbiera zespołowi dane o jakości wymagań i testów.
- Brak jednego wspólnego workflow między projektami utrudnia raportowanie i porównywanie wyników.
Warto też uważać na zbyt sztywne wymagania przy przejściach między stanami. Jeśli każde zgłoszenie wymaga długiej listy pól do uzupełnienia, ludzie zaczynają omijać proces albo wpisywać rzeczy na skróty. Lepiej zebrać mniej danych, ale takich, które naprawdę pomagają w decyzjach. To jedna z tych sytuacji, w których prostota jest nie tyle wygodna, ile po prostu skuteczniejsza.
Ostatnia rzecz, o której często się zapomina, to analiza przyczyn. Duplikaty, rejected czy deferred nie powinny zniknąć z radaru. Dla test management to cenne wskazówki, czy problem leży w produkcie, wymaganiach, jakości zgłoszeń, czy może w samym pokryciu testami. Gdy to widać, łatwiej zbudować workflow, który rzeczywiście wspiera zespół.
Proces, który warto utrzymać prosty, ale nie uproszczony
Najlepszy workflow defektów nie jest ani przesadnie rozbudowany, ani zbyt ogólny. Ma odpowiadać na trzy pytania: gdzie jest zgłoszenie, kto teraz za nie odpowiada i jaka decyzja ma zapaść dalej. Jeśli którykolwiek status nie pomaga odpowiedzieć na te pytania, zwykle jest zbędny.
W praktyce polecam trzymać się jednej wspólnej logiki w całej organizacji, dopuszczać powrót zgłoszenia do wcześniejszego stanu, gdy poprawka nie działa, i regularnie przeglądać metryki, które pokazują czas naprawy, reopen rate oraz liczbę defektów uciekających na produkcję. Taki proces nie tylko porządkuje pracę, ale też daje testom realną funkcję zarządczą. A to właśnie tam cykl życia defektu przestaje być teorią i staje się narzędziem do lepszych decyzji o jakości.