Najkrócej mówiąc, to praktyczne narzędzie do testów webowych dla zespołów JavaScriptowych
- Testy uruchamia w prawdziwej przeglądarce, a nie w oderwanym od UI symulatorze.
- Najlepiej sprawdza się w testach end-to-end i component testingu dla aplikacji webowych.
- Stabilność rośnie, gdy używasz data-* selektorów, cy.intercept() i cy.session().
- Domyślne retry zmniejsza liczbę fałszywych błędów, ale nie zastępuje dobrej architektury testów.
- Nie jest narzędziem do wszystkiego: trzeba ocenić wsparcie dla przeglądarek, zewnętrznych zależności i charakteru aplikacji.
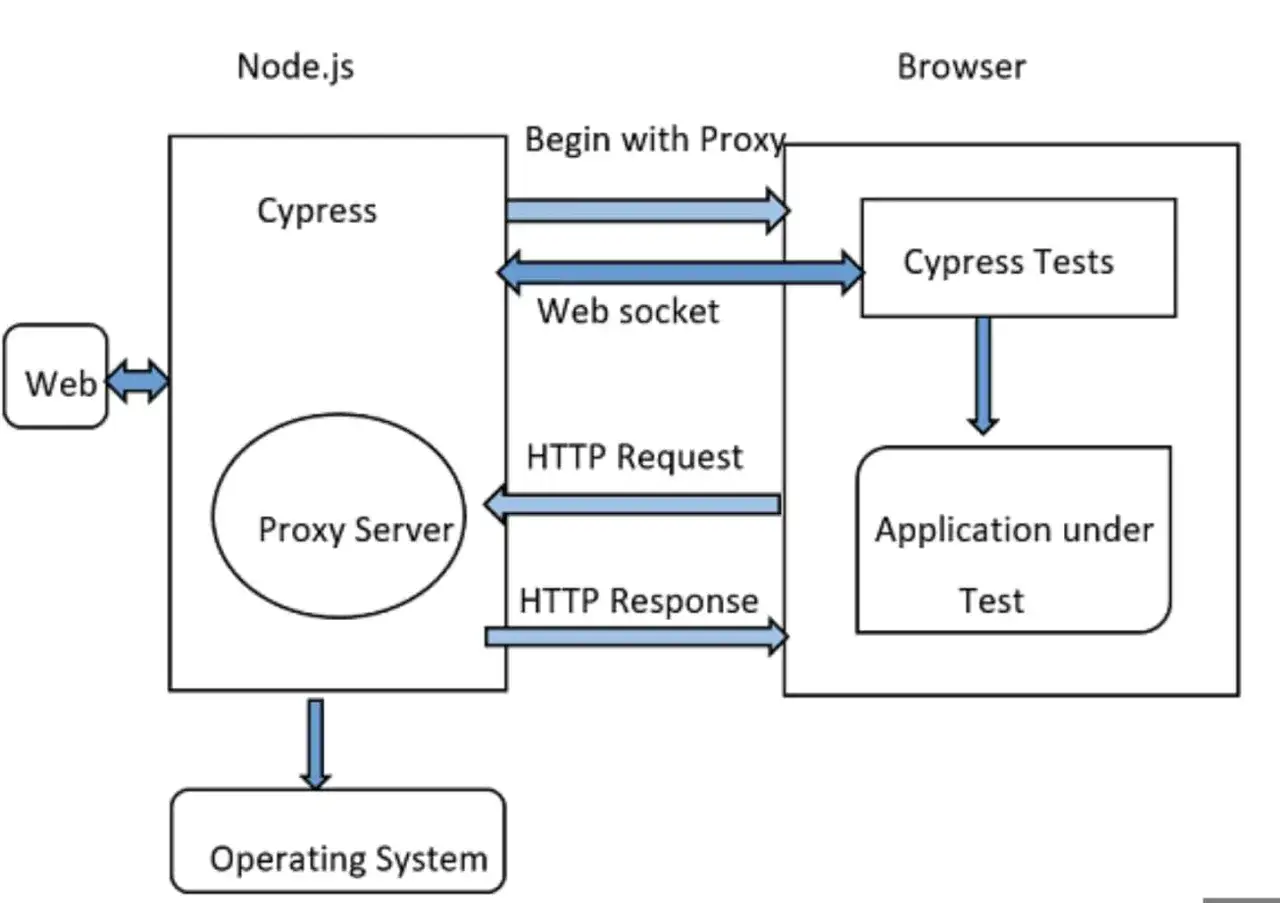
Czym jest Cypress i jak działa w przeglądarce
Cypress uruchamia testy w prawdziwej przeglądarce i dzięki temu pokazuje mi zachowanie aplikacji w warunkach bardzo zbliżonych do produkcji. To ważne, bo przy testach interfejsu najwięcej czasu nie zabiera samo sprawdzenie kliknięcia, tylko walka z opóźnieniami renderowania, asynchronicznością i elementami, które pojawiają się odrobinę później, niż oczekuje test.
Ja zwykle traktuję go jako warstwę, która ma sprawdzić najważniejsze zachowania użytkownika w środowisku, gdzie nadal mam dostęp do narzędzi developerskich, stanu przeglądarki i szczegółów debugowania. Cypress pracuje z Chrome i przeglądarkami z tej rodziny, obsługuje też Firefox i Electron, a WebKit ma obecnie wsparcie eksperymentalne. W praktyce oznacza to, że test nie jest tylko zbiorem asercji, ale obserwacją tego, co dzieje się w realnym browserze.
- Auto-wait i retry sprawiają, że `cy.get()` nie wybucha od razu, jeśli element jeszcze się nie wyrenderował.
- Komendy są kolejkowane, więc test jest bardziej przewidywalny niż chaotyczny miks przypadkowych opóźnień.
- Wbudowany runner i podgląd krok po kroku ułatwiają debugowanie bez ciągłego przeskakiwania między narzędziami.
- Domyślny czas ponawiania dla wielu komend to około 4 sekundy, co pomaga odsiać krótkie, przejściowe opóźnienia.
To właśnie ta mieszanka automatycznego czekania, debugowania i pracy w realnym browserze decyduje o tym, jak dobiera się typy testów, o czym piszę dalej.
Jak dobrać typ testów, żeby nie robić wszystkiego jako E2E
Największy błąd, jaki widzę w zespołach, to próba zrobienia całej automatyzacji wyłącznie przez testy end-to-end. Takie podejście szybko robi się drogie w utrzymaniu, a każda mała zmiana UI może pociągnąć za sobą serię poprawek. W Cypressie lepiej działa układ warstwowy: część przypadków pokrywasz E2E, część testami komponentowymi, a wybrane fragmenty uzupełniasz testami API albo kontrolą odpowiedzi sieciowych.
| Typ testu | Kiedy ma największy sens | Co daje | Na co uważać |
|---|---|---|---|
| End-to-end | Logowanie, zakup, zapis formularza, krytyczna ścieżka biznesowa | Sprawdza cały przepływ z perspektywy użytkownika | Jest wolniejszy i bardziej wrażliwy na środowisko |
| Component testing | Modal, formularz, tabela, pojedynczy widget, stan pusty i błędowy | Szybciej łapie regresje w UI i w logice komponentu | Nie zastępuje pełnej ścieżki użytkownika |
| API / kontrola sieci | Przygotowanie danych, trudne edge case’y, zależności backendowe | Zmniejsza flakiness i przyspiesza testy | Trzeba pilnować, by nie odciąć testu od rzeczywistego kontraktu |
W praktyce najlepiej działa zasada, że E2E obejmuje tylko to, co naprawdę musi być sprawdzone w pełnym przepływie, a resztę pokrywa się bliżej komponentu. Dzięki temu suite jest lżejszy, szybszy i mniej podatny na przypadkowe awarie. Kiedy już wiadomo, co testować, trzeba zadbać o stabilność selektorów i danych wejściowych, bo to zwykle psuje wyniki szybciej niż sama logika aplikacji.
Jak pisać stabilne testy, które nie pękają od drobnej zmiany interfejsu
Stabilność testów zaczyna się od selektorów. Jeśli test opiera się na klasach CSS, przypadkowych identyfikatorach albo tekście, który zespół UX zmieni przy następnym copy update, to prędzej czy później zacznie się sypać. Dlatego w Cypressie najczęściej stawiam na selektory testowe, jawne asercje i kontrolę nad tym, co przychodzi z sieci.
| Sposób selekcji | Ocena | Dlaczego |
|---|---|---|
| `button`, `.btn`, `#main` | Słaby | Łatwo pęka po zmianie stylów lub refaktorze komponentu |
| Tekst widoczny dla użytkownika | Umiarkowany | Dobrze oddaje zachowanie, ale copy może się zmieniać |
| `data-cy` lub inny atrybut `data-*` | Najlepszy | Jest odseparowany od layoutu, stylów i większości refaktorów |
| Role dostępnościowe, gdy pasują do scenariusza | Dobry | Pomagają testować zachowanie zgodne z dostępnością i semantyką UI |
cy.intercept('GET', '/api/orders', { fixture: 'orders.json' }).as('orders')
cy.visit('/orders')
cy.wait('@orders').its('response.statusCode').should('eq', 200)
cy.get('[data-cy="order-row"]').should('have.length', 3)Takie podejście daje mi trzy korzyści naraz. Po pierwsze, test nie zależy od przypadkowych klas CSS. Po drugie, sieć staje się przewidywalna, więc łatwiej odtwarzać edge case’y. Po trzecie, asercja mówi jasno, czego oczekuję, zamiast ukrywać intencję w długim łańcuchu przypadkowych kroków. W podobny sposób warto potraktować logowanie i stan sesji, bo to kolejny obszar, który zwykle generuje niepotrzebny hałas.
Jak wykorzystać Cypress w CI i ograniczyć flaky testy
W CI Cypress sprawdza się wtedy, gdy traktuję go jak narzędzie do wczesnego wykrywania regresji, a nie jak bezwzględny sędzia każdej drobnej zmiany. Flaky testy najczęściej biorą się z animacji, opóźnionych odpowiedzi API, niedostępności serwera lub bazy, zależności od zasobów zewnętrznych i zwykłych problemów sieciowych. Sam framework pomaga, ale nie naprawi architektury testów, która od początku była zbyt krucha.
Najbardziej praktyczne rzeczy, które wdrażam od razu, to `cy.session()` do logowania, lokalne retry zamiast globalnych sztuczek i porządne artefakty po błędzie. `cy.session()` czyści stronę i dane sesji przed uruchomieniem setupu, więc pozwala szybko przełączać użytkowników i nie powtarzać logowania w każdym teście. W większych suite’ach można też zapisać sesję na wiele specyfikacji, jeśli taki model naprawdę pasuje do projektu.
- Używaj `cy.session()` do programatycznego logowania zamiast przechodzenia przez UI przy każdym teście.
- Nie ustawiaj arbitralnych `cy.wait(1000)` tam, gdzie wystarczy asercja albo alias do requestu.
- Lokalnie korzystaj z trybu open, bo podgląd logu komend i stanu testu bardzo przyspiesza diagnozę.
- W CI zapisuj zrzuty ekranu i wideo tylko tam, gdzie pomagają znaleźć przyczynę błędu, a nie jako bezmyślny ciężar procesu.
- Jeśli jakaś ścieżka stale flakuje, ogranicz zależności sieciowe przez `cy.intercept()` zamiast udawać, że problemu nie ma.
To właśnie na etapie CI najlepiej widać, czy testy są rzeczywiście stabilne, czy tylko „działają u mnie lokalnie”. Gdy ten etap jest uporządkowany, warto spojrzeć uczciwie na ograniczenia samego narzędzia, żeby nie obiecać zespołowi więcej, niż Cypress faktycznie udźwignie.
Gdzie Cypress ma ograniczenia i kiedy lepiej się zatrzymać
Nie traktuję Cypressa jako uniwersalnego zamiennika całej automatyzacji. To bardzo mocne narzędzie do testów webowych, ale nie rozwiązuje wszystkiego. Jeżeli projekt wymaga natywnego mobile, bardzo szerokiego wachlarza języków albo niestandardowego środowiska poza przeglądarką, trzeba od razu sprawdzić, czy ten wybór naprawdę ma sens.
- Aplikacje natywne nie są jego naturalnym środowiskiem, bo Cypress skupia się na webie.
- Jeśli potrzebujesz pełnej pewności w bardzo nietypowych przeglądarkach lub engine’ach, najpierw zweryfikuj zakres wsparcia, a dopiero potem standardyzuj proces.
- Przy mocno zewnętrznych flow, takich jak logowania przez dostawców, płatności czy CAPTCHA, testy UI bywają kosztowne i wymagają skrótów przez API lub stuby.
- Gdy zespół buduje testy bez dobrych selektorów i bez kontroli nad stanem, nawet najlepsze narzędzie zaczyna wyglądać na „niestabilne”, choć problem leży gdzie indziej.
Ja patrzę na to bardzo pragmatycznie: Cypress wygrywa tam, gdzie aplikacja jest webowa, zespół pracuje w JavaScripcie lub TypeScripcie, a priorytetem jest szybka, czytelna automatyzacja krytycznych ścieżek. Jeśli te warunki są spełnione, można zacząć od małego, dobrze ustawionego zestawu reguł i szybko zobaczyć efekt.
Pierwsze decyzje, które dają najszybszy zwrot z automatyzacji
Jeżeli miałbym wdrażać ten framework od zera w zespole produktowym, zacząłbym od kilku prostych decyzji, które mają największy wpływ na jakość całego suite’u. Nie od liczby testów, tylko od sposobu ich konstrukcji.
- Wybierz 3 krytyczne ścieżki użytkownika, które naprawdę blokują biznes, jeśli przestaną działać.
- Dodaj `data-cy` do głównych elementów interakcji, zamiast opierać się na klasach CSS.
- Ustaw `baseUrl`, żeby nie powtarzać adresu w każdym `cy.visit()`.
- Opakuj logowanie w `cy.session()`, żeby nie przepalać czasu na powtarzalne kroki.
- Najbardziej niestabilne zależności sieciowe przejmij przez `cy.intercept()` i stuby, ale tylko tam, gdzie to rzeczywiście poprawia stabilność.
- Uruchamiaj testy w CI z retry i artefaktami po błędzie, żeby szybciej rozumieć, czy problem jest w aplikacji, czy w flake’u.
Tak ustawiony Cypress zwykle zaczyna dawać realny zwrot bardzo szybko: mniej ręcznego sprawdzania regresji, mniej przypadkowych błędów w pipeline’ach i szybszą diagnozę, gdy coś faktycznie się psuje. Największą różnicę robi nie sama technologia, tylko konsekwentne trzymanie się prostych zasad testowania w przeglądarce.