
W automatyzacji testów UI największy problem zwykle nie leży w samym klikaniu, tylko w utrzymaniu testów, gdy interfejs się zmienia. Właśnie dlatego page object pattern porządkuje locatory, akcje i logikę strony tak, żeby testy były krótsze, czytelniejsze i mniej kruche. Pokażę, kiedy ten wzorzec daje realny zwrot, jak go zbudować w praktyce oraz gdzie zaczyna bardziej przeszkadzać niż pomagać.
Najkrótsza odpowiedź o page object w testach UI
- To warstwa pośrednia między testem a interfejsem, która ukrywa selektory i techniczne kroki.
- Najlepiej działa tam, gdzie testy są powtarzalne, a UI często się zmienia.
- Dobra klasa strony opisuje zachowanie użytkownika, a nie sam układ HTML.
- Największy błąd to zamienianie page objectu w monolityczną klasę z całą logiką aplikacji.
- W małych projektach prostsze podejście bywa szybsze i tańsze.
Na czym polega model obiektów stron
Page object to po prostu obiekt, który reprezentuje ekran, fragment ekranu albo inny sensowny kawałek interfejsu. Zamiast rozrzucać po testach selektory, kliknięcia i wpisywanie danych, zamykam je w jednej klasie i daję testowi prosty, biznesowy interfejs: zaloguj się, dodaj produkt do koszyka, zapisz formularz.
W praktyce oznacza to, że test nie musi wiedzieć, czy przycisk ma dziś identyfikator, rolę ARIA czy tekst zmieniony po redesignie. Ta wiedza siedzi w jednym miejscu. Gdy UI się zmienia, poprawiam klasę strony, a nie kilkanaście albo kilkadziesiąt testów. Takie podejście jest dziś standardem zarówno w Selenium, jak i w Playwright, choć każdy framework pokazuje je trochę inaczej.
Ważny detal: page object nie musi odpowiadać 1:1 całej fizycznej stronie. Często lepiej modelować fragment, który ma znaczenie z punktu widzenia użytkownika, na przykład nagłówek, modal, koszyk, panel filtrów albo sekcję logowania. Kiedy już wiadomo, co taki obiekt ma wystawiać, trzeba go ułożyć tak, by nie stał się zlepkiem przypadkowych metod.
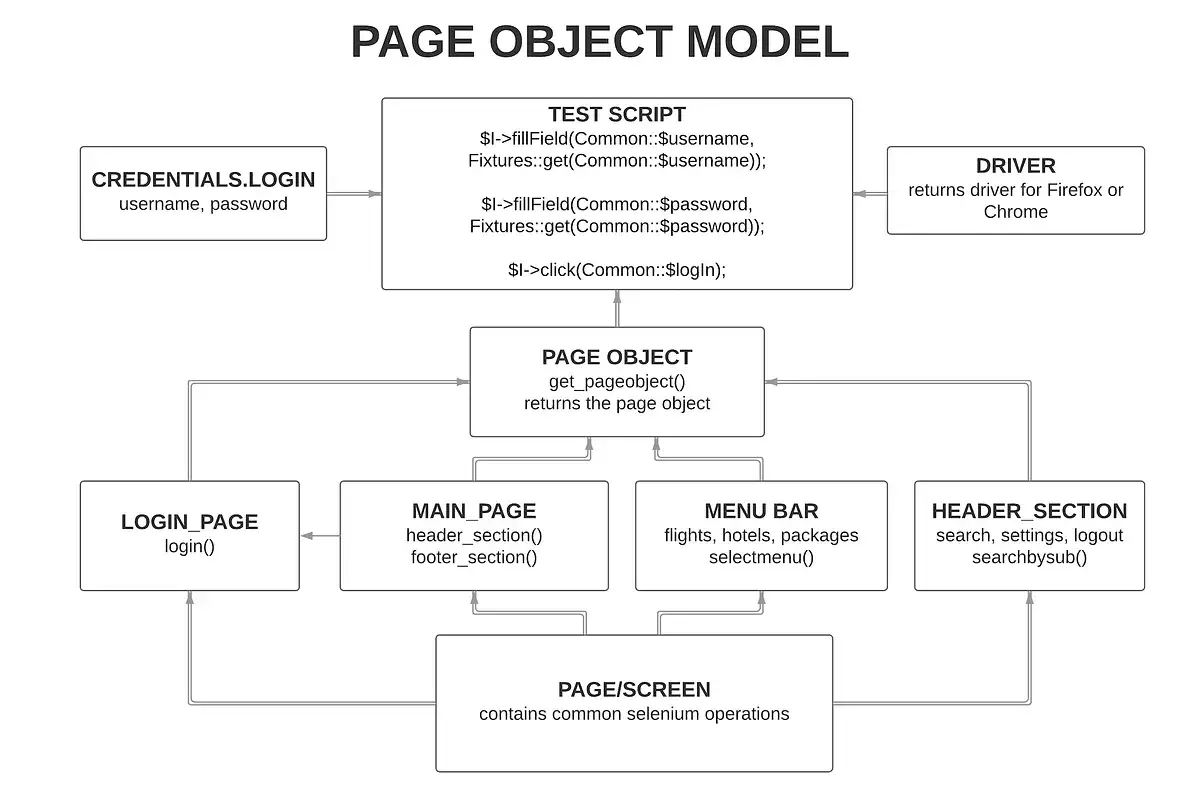
Jak zbudować klasę strony, która opisuje zachowanie
Ja zwykle zaczynam od jednej zasady: test ma widzieć intencję użytkownika, a page object ma widzieć techniczne szczegóły. Dzięki temu klasa nie staje się zbiorem getterów do przycisków, tylko warstwą języka testowego. Dobra metoda powinna mówić, co robi użytkownik, a nie który element DOM trzeba wcisnąć.
import { expect, Page } from '@playwright/test';
export class LoginPage {
constructor(private readonly page: Page) {}
async open() {
await this.page.goto('/login');
}
async signIn(email: string, password: string) {
await this.page.getByLabel('E-mail').fill(email);
await this.page.getByLabel('Hasło').fill(password);
await this.page.getByRole('button', { name: 'Zaloguj' }).click();
}
async isLoaded() {
await expect(
this.page.getByRole('heading', { name: 'Logowanie' })
).toBeVisible();
}
}W takim układzie test staje się krótki i czytelny:
const loginPage = new LoginPage(page);
await loginPage.open();
await loginPage.isLoaded();
await loginPage.signIn('ala@firma.pl', 'tajne-haslo');Zwróć uwagę na trzy rzeczy. Po pierwsze, selektory są ukryte. Po drugie, metoda ma nazwę wynikającą z zachowania użytkownika, a nie z HTML-a. Po trzecie, asercja sprawdza tylko stan wejścia strony, a nie całą logikę biznesową. To ważne rozróżnienie, bo page object nie powinien przejmować roli testu.
Jeśli w projekcie pojawiają się wspólne fragmenty, na przykład modale, tabelki, filtry albo pasek nawigacji, opłaca się wydzielić osobne obiekty komponentów i składać je z page objectów. To naturalny krok dalej, zwłaszcza gdy jeden ekran zaczyna być zbyt duży, by opisać go jednym rozsądnym plikiem.
Kiedy ten wzorzec daje największy zwrot
Najbardziej czuć to przy kilkudziesięciu albo kilkuset testach regresyjnych. Przy pięciu prostych scenariuszach dodatkowa warstwa bywa po prostu zbędna, ale gdy po redesignie trzeba poprawić jeden selektor w 27 testach, koszt ręcznej pracy robi się bardzo realny. Wtedy centralizacja interakcji zaczyna oszczędzać czas, a nie go konsumować.
Najlepsze zastosowania są dość przewidywalne:
| Sytuacja | Dlaczego page object pomaga | Na co uważać |
|---|---|---|
| Rozbudowana aplikacja SaaS albo e-commerce | Wiele ekranów, wiele kroków i częste zmiany UI | Nie budować jednej klasy na całą aplikację |
| Powtarzalne formularze i procesy zakupowe | Jedna zmiana w logice formularza trafia do jednego miejsca | Nie mieszać akcji użytkownika z walidacją biznesową |
| Wiele wspólnych elementów interfejsu | Modale, nagłówki, filtry i tabele można wydzielić do komponentów | Nie rozdrabniać się na obiekty, które nic nie upraszczają |
| Praca zespołowa przy automatyzacji | Jasne granice odpowiedzialności ułatwiają review i refaktoryzację | Potrzebna jest wspólna konwencja nazewnictwa |
To podejście szczególnie dobrze działa tam, gdzie UI zmienia się częściej niż logika testów. Gdy zespół ma jeden punkt prawdy dla selektorów i wspólny język dla akcji użytkownika, utrzymanie testów przestaje być ręcznym grzebaniem w dziesiątkach plików. Ale sam zwrot z inwestycji nie bierze się z abstrakcji; psują go bardzo konkretne błędy.
Gdzie kończą się zalety i zaczynają koszty
Najczęstszy błąd to zrobienie z page objectu wielkiej, wszystko wiedzącej klasy. Taki obiekt zaczyna wtedy obsługiwać nawigację, asercje, logikę biznesową, waity, a czasem nawet przygotowanie danych testowych. Efekt jest odwrotny do zamierzonego: zamiast uproszczenia dostaję warstwę pośrednią, którą trudno zrozumieć i jeszcze trudniej rozwijać.
- Zbyt wiele odpowiedzialności - obiekt strony nie powinien być miniaturową aplikacją testową.
- Asercje schowane w klasie - test traci czytelność, bo nie wiadomo już, co naprawdę sprawdza.
- Zbyt drobne metody - `clickButton`, `fillInput` i `selectOption` nic nie mówią o intencji użytkownika.
- Ukrywanie problemów z synchronizacją - page object nie naprawi flaky testów, jeśli aplikacja ładuje dane w nieprzewidywalny sposób.
- Brak granic między stroną a komponentem - gdy wszystko trafia do jednej klasy, refaktoryzacja staje się uciążliwa.
Jest jeszcze jedna pułapka, którą widzę często: przekonanie, że samo użycie page objectów automatycznie stabilizuje testy. To nieprawda. Jeśli selektory są niestabilne, dane testowe są losowe, a aplikacja ma problemy z asynchronicznością, wzorzec tylko lepiej opakowuje problem. Dlatego warto rozdzielać warstwę interakcji od warstwy sprawdzania zachowania i nie używać page objectu jako worka na wszystko.
Żeby nie wybierać abstrakcji na ślepo, dobrze porównać ją z prostszymi i bardziej wyspecjalizowanymi opcjami.
Page object, komponent czy bezpośredni locator
W praktyce nie chodzi o to, żeby wszędzie wdrożyć jeden wzorzec. Chodzi o dobranie poziomu abstrakcji do problemu. Czasem wystarczy prosty locator w teście. Czasem lepszy będzie page object. A czasem najbardziej opłaca się wydzielić obiekt komponentu, bo ten sam fragment interfejsu pojawia się w kilku miejscach.
| Podejście | Kiedy działa najlepiej | Plus | Minus |
|---|---|---|---|
| Bezpośrednie locatory | Krótki prototyp, pojedynczy test, szybki proof of concept | Minimum kodu i najmniej warstw | Duplikacja selektorów i większa kruchość |
| Page object | Powtarzalne flow, wiele kroków, częste zmiany interfejsu | Jeden punkt zmian i czytelne API dla testów | Ryzyko nadmiarowej abstrakcji, jeśli projekt jest mały |
| Component object | Modal, tabela, nagłówek, filtr, koszyk, dashboard widget | Świetny do współdzielonych fragmentów UI | Można przesadzić z liczbą klas, jeśli komponent jest banalny |
Ja zwykle łączę te trzy podejścia zamiast traktować je jako konkurencję. Testy najwyższego poziomu korzystają z page objectów, te z kolei składają się z komponentów, a najprostsze scenariusze czasem zostają przy locatorach. Najlepsze projekty nie wybierają jednego wzorca na wszystko, tylko dobierają poziom abstrakcji do części interfejsu.
Jak wdrożyć to w istniejącym repozytorium
Nie przepisywałbym całej bazy testów naraz. Najrozsądniej zacząć od tych flow, które najczęściej się psują albo najwięcej kosztują przy zmianach. W praktyce zwykle wystarcza kilka dobrze wybranych ekranów, żeby zespół zobaczył różnicę i przestał traktować wzorzec jak akademicki dodatek.
- Wybierz 3-5 najbardziej kosztownych scenariuszy i zacznij od nich.
- Przenieś do klas tylko to, co rzeczywiście się powtarza.
- Ustal jeden styl lokalizowania elementów, najlepiej oparty na rolach, etykietach lub stabilnych atrybutach testowych.
- Trzymaj asercje w testach, a nie w page objectach, poza krótkim sprawdzeniem, że ekran się otworzył.
- Wyciągaj współdzielone fragmenty do component objects, gdy zaczynają się powtarzać w kilku miejscach.
- W code review pilnuj, czy publiczne metody opisują intencje użytkownika, a nie techniczne kroki DOM.
W praktyce największą różnicę robi konsekwencja, nie sam fakt użycia wzorca. Jeśli każdy plik ma inny styl nazw, inne zasady waitów i inne granice odpowiedzialności, cała warstwa szybko robi się chaotyczna. Gdy jednak zespół trzyma się prostych reguł, page object przestaje być dodatkowym kodem, a staje się sposobem utrzymania porządku.
Co najbardziej poprawia utrzymanie testów w praktyce
Jeśli miałbym wskazać tylko kilka decyzji, które naprawdę obniżają koszt automatyzacji, postawiłbym na te:
- Stabilne locatory - selektory oparte na roli, etykiecie lub atrybucie testowym są zwykle bezpieczniejsze niż kruche XPathy.
- Metody na poziomie biznesowym - `addItemToCart` daje więcej niż trzy techniczne kroki rozrzucone po teście.
- Małe, wyraźne granice klas - jeden page object ma reprezentować sensowny fragment aplikacji, nie całą domenę.
- Komponenty dla wspólnych części UI - nagłówek, modal czy tabela powinny mieć własne miejsce, jeśli naprawdę są współdzielone.
- Asercje pozostawione w testach - dzięki temu od razu widać, co scenariusz sprawdza.
Jeśli miałbym zostawić jedną zasadę, to tę: page object ma chronić test przed zmianą HTML, a nie maskować brak dobrego projektu interfejsu. Gdy zaczyna opisywać zachowanie użytkownika, a nie tylko elementy, naprawdę obniża koszt utrzymania całej automatyzacji.