
Defekt w oprogramowaniu nie kończy się na tym, że coś „nie działa”. W praktyce chodzi o konkretną niezgodność produktu z wymaganiami, projektem albo oczekiwanym zachowaniem, a to od razu wpływa na decyzje testowe, priorytety i sposób naprawy. W tym tekście rozkładam temat na czynniki pierwsze: od definicji, przez różnice między defektem a błędem czy awarią, aż po to, jak nim zarządzać w zespole testowym.
Najważniejsze informacje o defekcie w testach
- Defekt to wada produktu pracy, niekoniecznie sama awaria widoczna dla użytkownika.
- W testowaniu najczęściej opisuje się go jako niezgodność z wymaganiami, specyfikacją lub oczekiwanym użyciem.
- Defekt nie jest tym samym co błąd człowieka, a awaria to zwykle dopiero jego skutek w działającym systemie.
- Dobry proces defektowy obejmuje zgłoszenie, triage, naprawę, testy regresji i zamknięcie.
- Najwięcej zysku daje wczesne wykrywanie, sensowna priorytetyzacja i analiza przyczyny źródłowej.
- W backlogu warto odróżniać severity, czyli wagę problemu, od priority, czyli kolejności naprawy.
Defekt co to znaczy w testowaniu i poza nim
W języku ogólnym defekt oznacza po prostu wadę, usterkę albo niedoskonałość. W testowaniu oprogramowania znaczenie jest bardziej precyzyjne: chodzi o imperfekcję produktu pracy, przez którą nie spełnia on wymagań, specyfikacji albo planowanego sposobu użycia. W ujęciu ISTQB to właśnie taki formalny, procesowy sens ma największe znaczenie, bo pozwala zespołowi mówić jednym językiem.
Ja patrzę na defekt szerzej niż na sam kod. Może pojawić się w wymaganiach, projekcie, danych testowych, skrypcie testowym, pliku konfiguracyjnym albo w dokumentacji użytkowej. To ważne rozróżnienie, bo nie każdy problem, który widzimy na ekranie, powstał w warstwie programistycznej. Czasem źródłem jest źle napisany opis funkcji albo sprzeczne założenia biznesowe.
| Kontekst | Co oznacza defekt | Przykład |
|---|---|---|
| Produkt fizyczny | Wada materiału, wykonania lub zgodności z normą | Krzywo spasowana obudowa urządzenia |
| Dokument lub wymagania | Błąd, luka albo sprzeczność, która później psuje wdrożenie | Niejasny zapis o limicie kwoty bez reguły zaokrągleń |
| Oprogramowanie | Niezgodność z oczekiwanym zachowaniem, projektem albo standardem | Filtr zwraca inne wyniki niż zakłada specyfikacja |
To rozróżnienie pomaga już na starcie, bo w testach nie chodzi tylko o znalezienie „błędu”, ale o ustalenie, gdzie leży problem i jaki ma wpływ na produkt. Od tego przechodzę naturalnie do najczęściej mylonych pojęć, bo tam zaczyna się większość nieporozumień.
Czym różni się defekt od błędu, usterki i awarii
W praktyce te słowa bywają używane zamiennie, ale w dobrze poukładanym zespole nie powinny znaczyć tego samego. Najkrócej ujmuję to tak: błąd jest po stronie człowieka lub procesu, defekt siedzi w produkcie pracy, a awaria to moment, w którym system już faktycznie zachowuje się niezgodnie z oczekiwaniem podczas uruchomienia. To rozróżnienie nie jest akademicką zabawą, tylko podstawą sensownego raportowania i analizy przyczyn.
| Termin | Co oznacza | Gdzie go szukamy | Przykład |
|---|---|---|---|
| Błąd | Mylną decyzję, pominięcie lub nieprecyzyjne działanie człowieka | W pracy analityka, developera, testera lub w procesie | Zły warunek w wymaganiu |
| Defekt | Wadę w artefakcie, który powinien spełniać określone kryteria | W kodzie, projekcie, dokumencie, danych albo konfiguracji | Nieobsłużony przypadek brzegowy w logice rabatu |
| Awaria | Widoczny skutek defektu w działającym systemie | W czasie wykonania testu albo pracy użytkownika | Aplikacja pokazuje 500 zamiast formularza |
| Bug | Potoczne określenie defektu | W rozmowie zespołu i w narzędziu do śledzenia zgłoszeń | „Ten bug blokuje release” |
Przy okazji warto pamiętać, że nie każda anomalia z przeglądu czy testu jest od razu defektem. Czasem to tylko niejasność, czasem brak wymagania, a czasem świadoma decyzja biznesowa. Jeśli tej granicy nie ustalimy wcześnie, backlog szybko zamienia się w worek z problemami o zupełnie różnej naturze.
Skąd biorą się defekty i dlaczego warto szukać przyczyny źródłowej
Gdy testy ujawniają defekt, najgorszą możliwą reakcją jest szybkie „naprawić i zapomnieć”. W zarządzaniu testami lepiej zadać pytanie, dlaczego ten defekt w ogóle powstał. To właśnie analiza przyczyny źródłowej, czyli root cause analysis, pomaga odróżnić jednorazowy przypadek od powtarzalnego wzorca, który będzie wracał w kolejnych sprintach albo wydaniach.
Najczęstsze źródła defektów widzę w kilku miejscach:
- niepełne albo sprzeczne wymagania,
- pomyłki projektowe, na przykład zła logika stanu lub walidacji,
- błędy implementacyjne,
- nieodpowiednie dane testowe lub produkcyjne,
- problem z integracją z innym systemem,
- brak aktualizacji dokumentacji po zmianie funkcji.
W praktyce najcenniejsza jest nie sama etykieta defektu, ale odpowiedź na pytanie, czy to problem jednorazowy, czy symptom słabego procesu. Jeśli zespół ma trzy podobne zgłoszenia z tego samego obszaru, zwykle nie chodzi już o szczęście albo pecha, tylko o powtarzalną lukę w analizie, review albo regresji. Dzięki temu łatwiej zdecydować, czy naprawa ma być tylko punktowa, czy trzeba też poprawić sposób pracy.
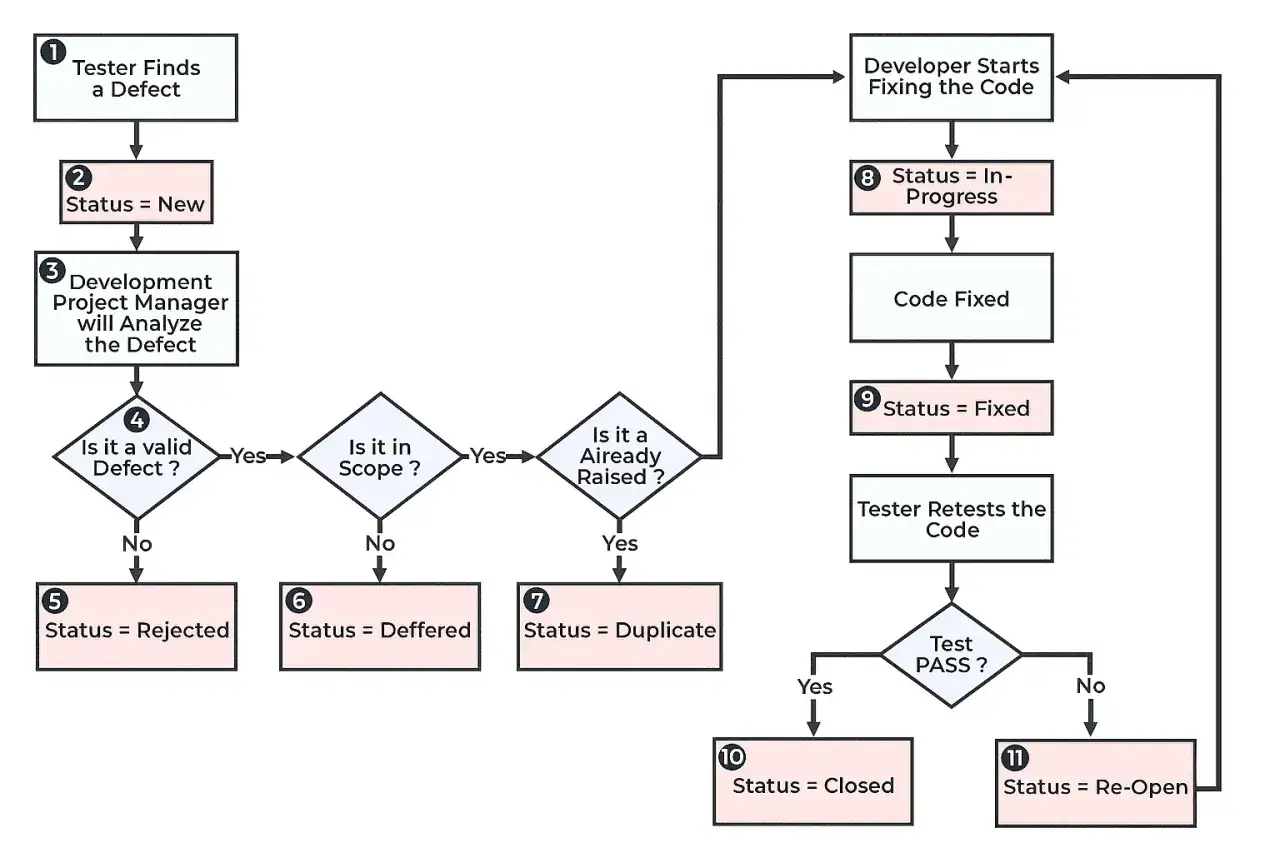
Jak wygląda zarządzanie defektami w praktyce
Dobry proces defektowy nie polega na tym, że ktoś wrzuca zgłoszenie do narzędzia i czeka na cud. Z mojego doświadczenia działa to tylko wtedy, gdy zespół ma jasny przepływ od wykrycia do zamknięcia oraz wie, kto podejmuje decyzję na każdym etapie. ISTQB słusznie podkreśla, że testowanie dostarcza informacji do działań naprawczych, a nie samo w sobie „naprawia” produkt.
- Zgłoszenie - tester opisuje problem tak, aby dało się go odtworzyć i zrozumieć bez domysłów.
- Triage - zespół ocenia, czy to rzeczywiście defekt, jak duży jest wpływ i kto powinien się nim zająć.
- Przydział - odpowiednia osoba lub zespół bierze zgłoszenie do pracy.
- Naprawa - defekt jest usuwany, a zmiana trafia do kolejnej wersji lub poprawki.
- Testy regresji - zespół upewnia się, że poprawka nie zepsuła innych obszarów.
- Zamknięcie - zgłoszenie dostaje finalny status, a historia zostaje zachowana do analizy.
Najczęstszy błąd widzę na poziomie zgłoszenia. Jeśli opis nie zawiera środowiska, wersji, kroków odtworzenia, oczekiwanego i rzeczywistego wyniku oraz dowodu, czyli na przykład zrzutu ekranu lub logu, to triage zajmuje dwa razy więcej czasu. Dobrze przygotowany raport defektu zwykle ma więc nie mniej niż pięć podstawowych elementów i oszczędza czas całego zespołu.
Jak oceniać wagę defektu bez chaosu w backlogu
Najwięcej zamieszania powstaje wtedy, gdy ktoś miesza severity z priority. Severity odpowiada na pytanie, jak poważny jest skutek defektu dla produktu i użytkownika. Priority mówi, kiedy trzeba go naprawić względem innych prac. To nie zawsze jest to samo. Defekt może mieć wysoką wagę techniczną, ale niską priorytetowość biznesową, jeśli dotyczy mało używanej funkcji. Zdarza się też odwrotnie.
| Kryterium | Na co odpowiada | Przykład | Kto zwykle decyduje |
|---|---|---|---|
| Severity | Jak duży jest wpływ problemu | Aplikacja nie pozwala się zalogować | Tester razem z zespołem technicznym |
| Priority | Jak szybko trzeba działać | Poprawka musi wejść przed publikacją | Product owner, QA lead, manager lub cały zespół |
Ja zwykle rekomenduję prostą, czteropoziomową skalę wagi, bo zbyt rozbudowane klasy robią więcej szkody niż pożytku. W praktyce wystarczą kategorie: krytyczny, wysoki, średni i niski. Taka skala jest czytelna dla devów, testerów i biznesu, a jednocześnie nie udaje matematycznej precyzji, której w ocenie defektu po prostu często nie ma.
- Krytyczny - blokuje kluczowy proces albo powoduje utratę danych.
- Wysoki - mocno ogranicza użycie funkcji, ale system da się jeszcze częściowo obsłużyć.
- Średni - problem jest realny, lecz nie zatrzymuje głównego scenariusza.
- Niski - wpływa na komfort, wygląd lub mało istotny przypadek brzegowy.
Ta klasyfikacja działa najlepiej wtedy, gdy zespół ustali wspólne kryteria przed pierwszym większym wydaniem. Bez tego każdy ocenia „pilność” po swojemu, a backlog staje się zbiorem emocji zamiast narzędziem decyzyjnym. Skoro już mamy priorytety, warto spojrzeć na to, jak ograniczać samą liczbę defektów, zanim trafią do raportu.
Jak ograniczać liczbę defektów w projekcie
Najbardziej opłacalne jest nie wykrywanie coraz większej liczby defektów, tylko zmniejszanie ich dopływu. To brzmi banalnie, ale w praktyce nadal wiele zespołów łata skutki zamiast poprawiać źródła problemów. Najlepsze efekty daje podejście „shift-left”, czyli przesuwanie weryfikacji wcześniej, jeszcze zanim kod trafi do pełnego testowania dynamicznego.
- Przeglądy wymagań i projektów - wiele defektów powstaje zanim pojawi się pierwsza linia kodu.
- Testy statyczne - przeglądy (review), inspekcje i analiza statyczna wychwytują niejasności oraz luki bez uruchamiania aplikacji.
- Automatyzacja regresji - szybko pokazuje, czy poprawka nie naruszyła starych obszarów.
- Testy eksploracyjne - dobrze znajdują defekty, których nie da się łatwo opisać prostym scenariuszem.
- Traceability - powiązanie wymagań z testami ułatwia sprawdzenie, co naprawdę zostało pokryte.
- Analiza trendów - jeśli defekty powtarzają się w tym samym module, problem jest zwykle systemowy, a nie przypadkowy.
Tu jest ważny kompromis: żadna pojedyncza technika nie wyeliminuje defektów. Testy statyczne zmniejszają liczbę błędów w wymaganiach, ale nie zastąpią testów wykonania. Automatyzacja przyspiesza regresję, ale nie rozwiąże źle zdefiniowanego biznesowo scenariusza. Dlatego skuteczny proces łączy kilka metod, zamiast liczyć na jedno cudowne narzędzie. To prowadzi do ostatniej rzeczy, którą zawsze warto sobie uporządkować, gdy temat defektów wraca w rozmowach zespołu.
Co warto zapamiętać o defekcie w pracy testera
Defekt nie jest wyłącznie technicznym wpisem w systemie śledzenia zgłoszeń. Dobrze opisany defekt to informacja o jakości produktu, stanie procesu i ryzyku dla wydania. Kiedy zespół rozumie, czym różni się defekt od błędu i awarii, szybciej znajduje przyczynę, trafniej ocenia wagę problemu i sprawniej zamyka sprawę.
- Najpierw ustalam, co dokładnie jest niezgodne, a dopiero później szukam winnego.
- Potem rozdzielam wagę problemu od kolejności naprawy.
- Na końcu pytam, czy defekt mówi coś o pojedynczym przypadku, czy o słabości procesu.
Jeśli taki porządek staje się standardem, testy zaczynają wspierać decyzje biznesowe, a nie tylko produkować kolejne zgłoszenia. I właśnie wtedy pojęcie defektu przestaje być abstrakcją, a staje się praktycznym narzędziem zarządzania jakością.