Dobrze zbudowane środowisko testowe decyduje o tym, czy testy pokazują prawdziwe ryzyko, czy tylko dają złudne poczucie kontroli. W praktyce test environment to kontrolowane środowisko, w którym odtwarza się kluczowe elementy produkcji, żeby sprawdzić funkcje, integracje, wydajność i zachowanie danych. Ten tekst porządkuje najważniejsze decyzje: jak je zaplanować, jak utrzymywać spójność, jak pracować z danymi oraz jakie błędy najczęściej psują wyniki.
Najważniejsze rzeczy, które trzeba ustawić od razu
- Środowisko testowe ma odzwierciedlać ryzyka produkcyjne, a nie być przypadkową kopią systemu.
- Najwięcej problemów powodują różnice w konfiguracji, danych i dostępach, nie sam kod aplikacji.
- Różne typy środowisk służą do różnych testów: integracyjnych, akceptacyjnych, wydajnościowych i bezpieczeństwa.
- Dane testowe trzeba maskować lub syntetyzować, inaczej testy tracą wiarygodność i rośnie ryzyko naruszeń.
- Automatyzacja, Infrastructure as Code i automatyczne czyszczenie środowisk ograniczają drift i skracają czas przygotowania.
- Dobre zarządzanie środowiskami to proces z właścicielem, monitoringiem, wersjonowaniem i mierzalnymi SLA, a nie tylko serwer „na wszelki wypadek”.
Czym naprawdę jest środowisko testowe i po co je utrzymywać
Środowisko testowe to nie „druga produkcja” i nie miejsce, gdzie wszystko ma być identyczne co do bajtu. Dla mnie jego sens jest prosty: ma być wystarczająco podobne tam, gdzie pojawia się ryzyko, i jednocześnie na tyle kontrolowane, by testy można było odtwarzać oraz porównywać. W praktyce chodzi o zestaw komponentów takich jak aplikacja, baza danych, usługi zewnętrzne, konfiguracja sieci, mechanizmy autoryzacji, logowanie i dane testowe.
Największa wartość dobrze utrzymanego środowiska polega na tym, że pozwala oddzielić błąd kodu od błędu konfiguracji. Jeśli test się wywraca, trzeba wiedzieć, czy winna jest logika biznesowa, niekompatybilna wersja biblioteki, brak uprawnień, czy po prostu zły zestaw danych. Bez tego zespół szybko zaczyna gasić pożary zamiast zarządzać jakością.Ja patrzę na to jeszcze szerzej: środowisko testowe wspiera nie tylko QA, ale też development, DevOps i release management. To ono decyduje, czy da się wiarygodnie odtworzyć błąd, czy regresja zostanie wychwycona przed wdrożeniem i czy wydanie nie będzie oparte na przypuszczeniach. Skoro cel jest tak praktyczny, trzeba najpierw zaplanować środowisko pod konkretne ryzyka, a dopiero potem wybierać narzędzia.
Jak zaprojektować środowisko, które daje wiarygodne wyniki
Najczęstszy błąd, jaki widzę, to budowanie środowiska „ogólnego przeznaczenia”. Takie podejście zwykle kończy się tym, że nie jest ono dobre do niczego. Lepiej zacząć od odpowiedzi na kilka prostych pytań: co testujemy, na jakim etapie, z jaką częstotliwością i jak blisko produkcji musi to działać.W praktyce dzielę projekt środowiska na pięć decyzji:
- Ustal zakres testów, które mają tam zachodzić, bo inne wymagania ma test funkcjonalny, a inne wydajnościowy.
- Określ zależności zewnętrzne, czyli które usługi muszą być prawdziwe, a które można zasymulować.
- Wybierz poziom izolacji, aby testy nie mieszały się z produkcją i nie wpływały na siebie nawzajem.
- Zdefiniuj właściciela środowiska, bo bez odpowiedzialności każdy problem staje się problemem wszystkich.
- Ustal cykl odświeżania, czyli kiedy environment ma być czyszczony, rekonfigurowany lub odtwarzany od zera.
Najbardziej praktyczna zasada brzmi: im większe ryzyko biznesowe, tym większa potrzeba podobieństwa do produkcji. Dla prostych testów funkcjonalnych wystarczy lżejsza konfiguracja, ale przy integracjach, płatnościach, raportowaniu czy wydajności trzeba pilnować wersji usług, schematów bazy i zachowania sieci. Dobrze zaprojektowane środowisko nie eliminuje wszystkich niespodzianek, ale mocno ogranicza liczbę fałszywych alarmów.
Kiedy projekt jest już uporządkowany, warto rozróżnić typy środowisk, bo każde odpowiada za inny fragment ryzyka.
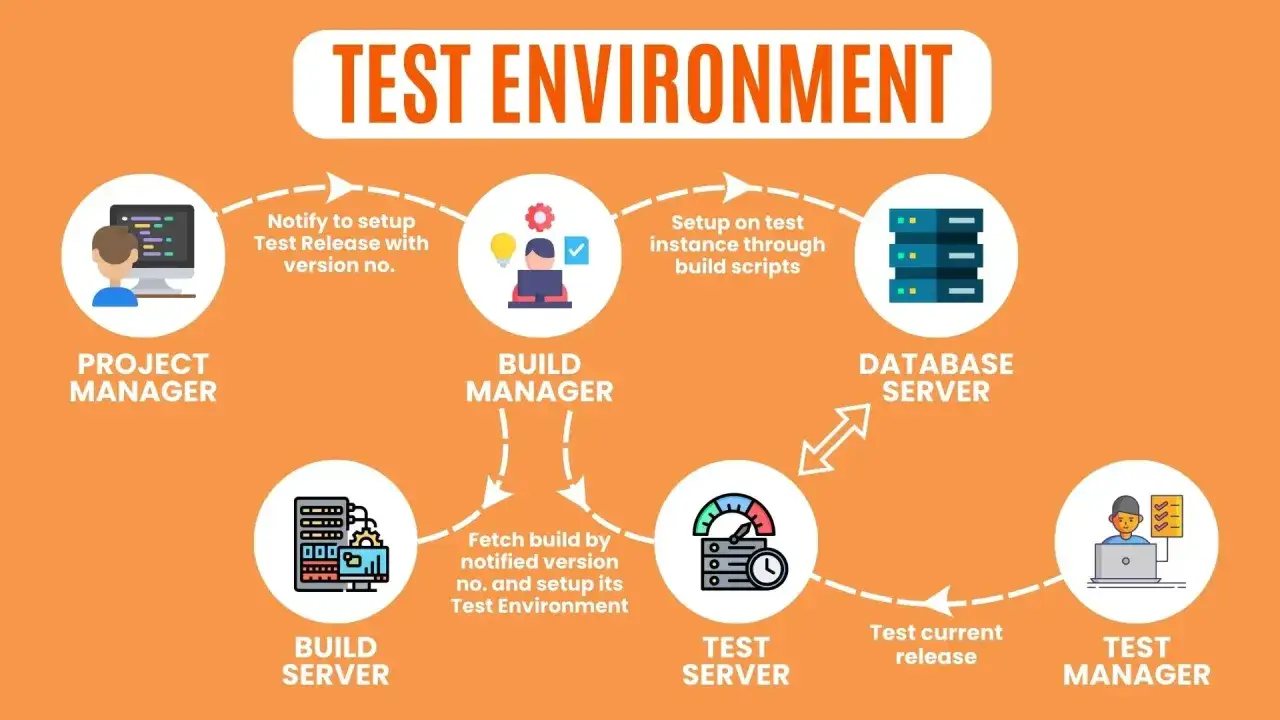
Jakie typy środowisk wykorzystuje się w praktyce
W dojrzałych zespołach nie ma jednego środowiska „do wszystkiego”. Zamiast tego pracuje się na kilku warstwach, z których każda pełni inną funkcję. To pozwala testować wcześnie, szybciej wykrywać regresje i nie blokować pracy całego zespołu jednym konfliktem konfiguracji.
| Typ środowiska | Do czego służy | Mocna strona | Ograniczenie |
|---|---|---|---|
| Lokalne / deweloperskie | Szybka praca nad kodem, debugowanie, testy jednostkowe | Najniższy koszt i najszybsza iteracja | Najmniejsze podobieństwo do produkcji |
| Integracyjne | Sprawdzanie współpracy modułów, API i zależności | Wcześnie pokazuje problemy kontraktów i integracji | Łatwo je „zaśmiecić” współdzielonymi zmianami |
| Staging | Finalna weryfikacja przed wdrożeniem, UAT, smoke testy | Najbliżej produkcji w warstwie konfiguracji i przepływów | Nie odtworzy wszystkiego, zwłaszcza pełnej skali ruchu |
| Wydajnościowe | Load, stress, soak i testy skalowania | Pokazuje wąskie gardła i problemy z zasobami | Wymaga bardzo dobrych danych i obserwowalności |
| Bezpieczeństwa | Weryfikacja podatności, konfiguracji dostępu i reakcji na ataki | Pomaga znaleźć słabe punkty bez ryzyka dla produkcji | Wymaga ścisłej izolacji i kontroli uprawnień |
Coraz częściej dochodzą do tego środowiska tymczasowe, tworzone na czas gałęzi kodu albo konkretnego pull requestu. To rozwiązanie jest szczególnie sensowne w projektach z dużą liczbą równoległych zmian, bo zmniejsza konflikty i skraca czas oczekiwania na dostęp. Nie jest jednak darmowe: jeśli provisioning jest wolny albo źle zautomatyzowany, zaleta znika bardzo szybko.
Dobór typów środowisk prowadzi wprost do kolejnego tematu, czyli danych. Bez nich nawet idealna infrastruktura nie da odpowiedzi, której naprawdę potrzebuje zespół.
Dane testowe, maskowanie i zgodność z wymaganiami
Dane są jednym z najczęściej niedoszacowanych elementów całego procesu. Zespół potrafi dopracować serwery, obrazy kontenerów i pipeline, a potem wrzuca do środowiska przypadkowe rekordy sprzed pół roku. Efekt jest przewidywalny: testy przechodzą albo padają z powodów, które nie mają wiele wspólnego z realnym scenariuszem użytkownika.
Ja trzymam się tu trzech zasad:
- Gdzie się da, używaj danych syntetycznych, bo są bezpieczniejsze i łatwiejsze do odtworzenia.
- Jeśli musisz pracować na danych zbliżonych do produkcyjnych, stosuj maskowanie, anonimizację lub pseudonimizację.
- Odświeżaj zbiory danych według ustalonego cyklu, zamiast liczyć na to, że „jeszcze coś się uda na tym samym snapshotcie”.
W praktyce największym problemem nie jest samo przechowywanie danych, tylko ich użycie w testach integracyjnych, wydajnościowych i akceptacyjnych. Na przykład przy systemach finansowych albo ERP potrzebujesz spójnych relacji między rekordami, ale nie potrzebujesz prawdziwych danych osobowych. Tę różnicę warto zrozumieć od razu, bo inaczej organizacja albo ryzykuje wyciek, albo testuje na danych tak uproszczonych, że wyniki tracą wartość.
Przy pracy z danymi dobrze sprawdza się też wersjonowanie zestawów wejściowych. Jeśli błąd pojawił się na konkretnym seedzie, trzeba móc go odtworzyć bez ręcznego grzebania w bazie. Taka powtarzalność naturalnie prowadzi do automatyzacji, bo ręczne przygotowanie środowisk szybko przestaje być skalowalne.
Automatyzacja i Infrastructure as Code zmieniają cały model pracy
Jeżeli środowisko testowe da się zbudować tylko ręcznie, to wcześniej czy później zacznie się rozjeżdżać. Jedna osoba ustawia wersję bazy, inna poprawia konfigurację aplikacji, ktoś trzeci dodaje wyjątek „na chwilę”, a po miesiącu nikt nie wie, dlaczego środowisko działa inaczej niż dokumentacja. Właśnie dlatego Infrastructure as Code i automatyzacja provisioning’u są tak ważne.
W praktyce chodzi o to, żeby środowisko dało się:
- odtworzyć z definicji zapisanej w repozytorium,
- uruchomić na żądanie, bez ręcznych kliknięć,
- zweryfikować testem zdrowia przed startem testów,
- usunąć po zakończeniu pracy, jeśli jest tymczasowe,
- zaktualizować w kontrolowany sposób, z pełnym śladem zmian.
To podejście ma jeszcze jedną przewagę: ogranicza configuration drift, czyli rozjazd między środowiskami. Im więcej ręcznych zmian, tym większa szansa, że test zacznie przechodzić lokalnie, ale padnie na stagingu albo odwrotnie. Automatyzacja nie jest więc ozdobą DevOps, tylko mechanizmem utrzymania spójności.
W środowiskach opartych o CI/CD najlepiej sprawdza się model, w którym infrastruktura jest tworzona razem z aplikacją, a po teście sprzątana. Taki model nie zawsze pasuje do wszystkich systemów, zwłaszcza monolitów lub rozwiązań z ciężkimi zależnościami sprzętowymi, ale tam, gdzie się da, skraca czas oczekiwania i zmniejsza liczbę konfliktów między zespołami. Gdy automatyzacja zaczyna działać, wychodzą na jaw błędy organizacyjne, które wcześniej przykrywało ręczne „dogadywanie się” ludzi.
Najczęstsze błędy, które psują wiarygodność testów
Większość problemów z testami nie wynika z tego, że zespół „źle testuje”. Częściej winne są warunki, w których testy są wykonywane. Z mojego doświadczenia najgroźniejsze są błędy, które wyglądają niewinnie, bo na początku po prostu spowalniają pracę, a później zaczynają fałszować wyniki.
- Zbyt małe podobieństwo do produkcji - jeśli wersje usług, bazy danych albo routing sieciowy różnią się za bardzo, test niczego sensownego nie potwierdza.
- Współdzielone środowisko bez kontroli dostępu - jedna zmiana może zepsuć testy kilku zespołów naraz.
- Brak właściciela i SLA - nikt nie reaguje szybko, gdy środowisko przestaje odpowiadać albo działa w trybie awaryjnym.
- Stare lub przypadkowe dane - testy przechodzą na danych, których użytkownicy już nigdy nie zobaczą, więc wynik jest mylący.
- Brak monitoringu i logów - bez obserwowalności nie wiadomo, czy awaria pochodzi z aplikacji, bazy, sieci, czy samej platformy testowej.
- Brak automatycznego czyszczenia - środowisko „puchnie”, rośnie koszt utrzymania i pojawiają się zależności, których nikt nie planował.
W praktyce ogromną różnicę robi też umiejętność rozpoznania, kiedy test jest flakiem, a kiedy realnym sygnałem o jakości. Jeśli środowisko jest niestabilne, nawet najlepsza automatyzacja zaczyna generować szum. Dlatego warto mierzyć nie tylko sukcesy testów, ale też odsetek awarii środowiskowych, czas odtworzenia i liczbę ręcznych interwencji.
Ta perspektywa prowadzi do ostatniego kroku: trzeba spojrzeć na środowisko nie jak na pojedynczy serwer, tylko jak na usługę wewnętrzną, którą da się ocenić i usprawniać.
Co odróżnia dojrzałe zarządzanie od zwykłego utrzymywania serwera
Dojrzałe zarządzanie środowiskami testowymi zaczyna się tam, gdzie kończy się improwizacja. Nie wystarczy, że aplikacja „jakoś działa” na jednej maszynie. Potrzebujesz procesu, który określa, kto odpowiada za provisioning, jak szybko środowisko ma się odtworzyć, kiedy dane mają być odświeżone i co zrobić, gdy pojawi się drift albo awaria.
Jeśli miałbym wskazać trzy metryki, które naprawdę warto obserwować, wybrałbym:
- czas przygotowania środowiska od zgłoszenia do gotowości,
- liczbę testów zablokowanych przez problemy środowiskowe,
- częstotliwość ręcznych zmian poza repozytorium konfiguracji.
Te trzy wskaźniki bardzo szybko pokazują, czy organizacja ma kontrolę nad infrastrukturą testową, czy tylko utrzymuje ją z przyzwyczajenia. Jeśli chcesz zacząć praktycznie, zacznij od audytu jednego środowiska: sprawdź jego skład, właściciela, dane, czas odtworzenia i poziom zgodności z produkcją. Z takiego przeglądu zwykle wychodzą konkretne poprawki, które dają więcej niż kolejna warstwa narzędzi.
W dobrze prowadzonym procesie środowisko testowe przestaje być źródłem chaosu, a staje się przewidywalnym elementem zarządzania jakością. I właśnie wtedy testy zaczynają robić to, do czego zostały stworzone: ograniczać ryzyko przed wdrożeniem, zamiast tylko je opisywać.