Oś przodków w XPath przydaje się wtedy, gdy element, którego potrzebujesz w teście, jest łatwy do znalezienia dopiero od dołu drzewa DOM. W praktyce xpath ancestor pozwala przejść od konkretnego pola, tekstu lub przycisku do formularza, wiersza tabeli albo całej sekcji, bez opierania locatora na kruchych klasach CSS. To jedno z tych narzędzi, które szczególnie dobrze działają w automatyzacji testów, bo pomagają budować selektory bardziej odporne na zmiany interfejsu.
Najważniejsze informacje o osi przodków w XPath
- `ancestor` zwraca wszystkich przodków węzła, od rodzica aż po korzeń drzewa.
- `ancestor-or-self` obejmuje także bieżący węzeł, co bywa wygodne przy pracy z komponentami wielokrotnego użytku.
- `..` jest skrótem dla bezpośredniego rodzica, ale nie zastępuje całej osi przodków.
- Najlepiej sprawdza się w tabelach, formularzach, kartach, modalach i innych strukturach zagnieżdżonych.
- Najczęstszy błąd to zbyt ogólny selektor, na przykład oparty tylko na `div` bez dodatkowego zawężenia.
- W testach warto łączyć tę oś z czytelnymi atrybutami i stabilnym tekstem, zamiast wspinać się przez cały DOM.
Jak działa oś przodków w XPath
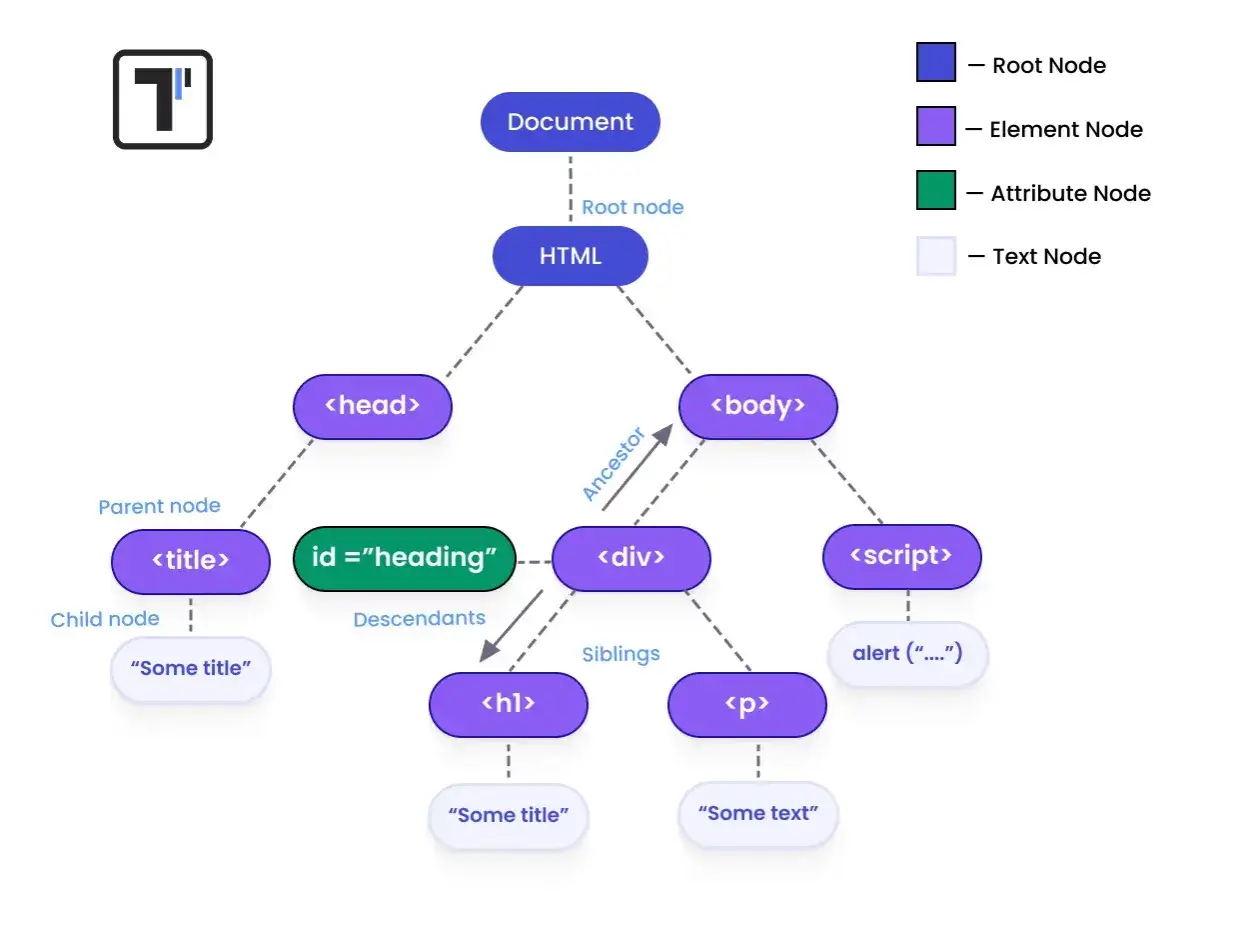
W specyfikacji XPath opisano 13 osi, a `ancestor` należy do osi odwrotnych, czyli takich, które poruszają się w górę drzewa. Punkt startu to węzeł kontekstu, a wynik obejmuje jego rodzica, dziadka, pradziadka i kolejne poziomy aż do korzenia dokumentu. Wyjątek jest prosty: jeśli sam jesteś na korzeniu, lista przodków będzie pusta.
Jeśli potrzebujesz nie tylko przodków, ale też bieżącego elementu, użyj ancestor-or-self. To praktyczne wtedy, gdy ten sam kod ma działać zarówno na elemencie docelowym, jak i na jego dziecku. Dla jednego poziomu wyżej wystarczy skrót .., który odpowiada parent::node().
| Wyrażenie | Co zwraca | Kiedy używam |
|---|---|---|
ancestor::form |
Wszystkie formularze nad bieżącym węzłem | Gdy chcę dojść od pola do otaczającego formularza |
ancestor-or-self::section |
Sekcje nad węzłem i ewentualnie sam węzeł | Gdy komponent może już być właściwą sekcją |
.. |
Bezpośredniego rodzica | Gdy wystarcza jeden krok w górę |
ancestor::tr[1] |
Najbliższy pasujący wiersz tabeli | Gdy chcę lokalnego kontenera, a nie całego drzewa |
Najważniejszy wniosek jest prosty: ta oś nie służy do „przeskakiwania” po DOM na ślepo, tylko do świadomego odnajdywania właściwego kontenera. To rozróżnienie dobrze prowadzi nas do praktycznych wzorców użycia.
Gdzie ta oś najbardziej się opłaca w testach UI
Ja sięgam po ancestor wtedy, gdy najłatwiej znaleźć wewnętrzny element, a dopiero potem dojść do jego kontekstu. W testach UI to częsty przypadek, bo tekst, etykieta lub wartość w komórce bywa stabilniejsza niż struktura otaczających kontenerów.
- Tabele i listy - najpierw lokalizujesz konkretną komórkę, a potem przechodzisz do wiersza. To ułatwia kliknięcie przycisku „Usuń” albo „Edytuj” dla właściwego rekordu.
- Formularze - od pola input przechodzisz do całego formularza, co pomaga odnaleźć przycisk zapisu w tym samym kontekście.
- Karty i kafelki - z poziomu ceny, nazwy produktu albo badge’a wracasz do całej karty, żeby wykonać akcję na właściwym komponencie.
- Modale i panele boczne - znajdujesz tekst nagłówka lub etykietę, a potem izolujesz konkretny dialog zamiast klikać w elementy poza nim.
- Komponenty wielokrotnego użytku - gdy struktura ma wiele podobnych bloków, przodek pomaga odróżnić właściwy egzemplarz bez zależności od losowych klas.
To podejście ma jedną dużą zaletę: przenosi ciężar selektora z kruchej struktury na stabilny kontekst biznesowy. Jeśli tekst „Zapisz” albo numer zamówienia zmienia się rzadziej niż układ `div`-ów, test zyskuje na trwałości. I właśnie dlatego ta oś jest tak cenna w automatyzacji.
W praktyce oznacza to, że zamiast zaczynać od całej ścieżki HTML, lepiej wejść do DOM od elementu, który naprawdę niesie znaczenie dla testu. Następny krok to nauczyć się pisać te selektory bez tworzenia przypadkowych pułapek.
Jak pisać selektory, które naprawdę pomagają w automatyzacji
Najlepsze selektory z przodkami są krótkie, czytelne i osadzone w logice interfejsu. Ja zwykle zaczynam od pytania: co w tym widoku jest najstabilniejsze? Odpowiedź prawie nigdy nie brzmi „kolejny anonimowy `div`”.
-
Od pola do formularza
//input[@name='email']/ancestor::form
Ten wzorzec jest dobry, gdy przycisk wysyłający formularz znajduje się bliżej rodzica niż samego pola. Dzięki temu nie musisz liczyć, ile wrapperów dzieli input od kontenera. -
Od komórki do wiersza
//td[normalize-space()='Anna Nowak']/ancestor::tr[1]
To jeden z najbardziej praktycznych przypadków w testach tabel.normalize-space()ogranicza ryzyko błędu związanego z dodatkowymi spacjami, a[1]wskazuje najbliższy pasujący wiersz. -
Od elementu wewnętrznego do karty
//*[@data-testid='price']/ancestor::article[1]
Tu dobrze widać połączenie stabilnego atrybutu testowego z ruchem w górę drzewa. To często lepsze niż szukanie całej karty po klasie CSS. -
Od etykiety do dialogu
//h2[normalize-space()='Usuń konto']/ancestor::*[@role='dialog'][1]
Jeśli modal ma semantyczną rolę, warto z niej skorzystać. Taki locator jest bardziej zrozumiały dla zespołu niż długa ścieżka przez kolejne warstwy layoutu.
Warto zapamiętać jedną rzecz: na osi odwrotnej kolejność wyników bywa myląca. Jeśli dopiszesz [1] do ancestor::..., zwykle dostaniesz najbliższego pasującego przodka, a nie najwyżej położony element. To detal, który potrafi uratować albo zepsuć test, więc dobrze mieć go z tyłu głowy.
Gdy ten mechanizm już działa, pojawia się kolejne pytanie: co najczęściej psuje takie selektory i jak tego uniknąć w codziennej pracy.
Najczęstsze błędy przy używaniu osi przodków
W praktyce błędy są dość powtarzalne. Widzę je szczególnie w projektach, gdzie XPath traktuje się jak ostatnią deskę ratunku po nieudanych próbach z CSS albo po przeprojektowaniu interfejsu.
-
Zbyt ogólny przodek -
ancestor::divbrzmi wygodnie, ale zwykle zwraca zbyt wiele dopasowań i szybko robi się nieczytelny. - Brak ograniczenia kontekstu - jeśli startujesz od zbyt szerokiego selektora, będziesz wspinać się po drzewie z kilku różnych miejsc naraz.
- Pomylenie liczby poziomów - gdy wystarczy jeden rodzic, nie ma sensu używać całej osi przodków. To nie poprawia jakości testu, tylko ją zaciemnia.
- Zaufanie do niestabilnych klas - jeśli selektor opiera się na klasie generowanej przez framework, zmiana stylu może złamać test bez żadnej zmiany funkcji.
-
Ignorowanie semantyki HTML - jeśli istnieje naturalny kontener typu
form,table,sectionalbodialog, warto go wykorzystać zamiast przypadkowego wrappera.
Najkrócej mówiąc: XPath ma pomagać zawężać kontekst, a nie maskować zły markup. Jeśli selektor robi się długi i wymaga komentarza, zwykle sygnalizuje problem z modelem UI albo z samym podejściem do lokalizacji. To prowadzi wprost do wyboru właściwej osi w zależności od zadania.
Kiedy lepiej wybrać rodzica, a kiedy sięgać po przodków
Nie każdy przypadek wymaga pełnego wejścia w górę drzewa. Czasem prostsza oś jest lepsza, bo szybciej ją odczytasz, łatwiej utrzymasz i trudniej zepsujesz przy refaktoryzacji interfejsu.
| Potrzeba | Lepszy wybór | Dlaczego |
|---|---|---|
| Jeden poziom w górę |
.. lub parent::node()
|
Najprostsze i najbardziej czytelne rozwiązanie |
| Dowolny pasujący kontener wyżej | ancestor::... |
Przydaje się, gdy struktura ma zmienną liczbę wrapperów |
| Bieżący element też ma być dopuszczony | ancestor-or-self::... |
Pomaga w komponentach, które mogą już być właściwym celem |
| Potrzebujesz elementów niżej |
descendant::... lub //
|
Nie ma sensu iść w górę, jeśli zadanie jest odwrotne |
| Szukasz rodzeństwa przy tym samym rodzicu |
following-sibling::... lub preceding-sibling::...
|
To bardziej precyzyjne niż wspinanie się do przodka i schodzenie z powrotem |
Ja stosuję prostą zasadę: wybieram najkrótszą możliwą ścieżkę, która nadal jest stabilna. Jeśli wystarcza rodzic, nie dokładam przodków. Jeśli potrzeba kilku poziomów w górę, nie próbuję sztucznie rozwiązywać problemu jednym skokiem w dół. Taka dyscyplina naprawdę zmniejsza liczbę kruchych locatorów.
To prowadzi do ostatniej, praktycznej warstwy: jak korzystać z tej osi tak, żeby była wsparciem dla testów, a nie źródłem kolejnych utrzymaniowych kłopotów.
Jak zbudować locator odporny na redesign i jednocześnie czytelny
Jeżeli miałbym zostawić jedną redakcyjną wskazówkę, brzmiałaby tak: najpierw stabilność, potem elegancja składni. W testach automatycznych czytelność jest ważna, ale dopiero po tym, jak selector faktycznie przetrwa zmianę układu strony.- Opieraj punkt startowy na stabilnym atrybucie, na przykład
data-testid, gdy jest dostępny. - Wspinaj się tylko do takiego przodka, który ma znaczenie biznesowe: formularza, wiersza, karty, dialogu albo sekcji.
- Unikaj łańcuchów złożonych z wielu anonimowych kontenerów, bo są trudne do utrzymania i trudne do zrozumienia dla zespołu.
- Łącz tekst widoczny dla użytkownika z semantyką HTML, zamiast polegać wyłącznie na klasach stylów.
- Jeśli selektor zaczyna przypominać drogę ewakuacyjną przez cały DOM, lepiej wrócić do markup-u lub dodać atrybut testowy.
W dobrze zaprojektowanym teście oś przodków nie jest sztuczką, tylko świadomym skrótem między rozpoznawalnym elementem a właściwym kontekstem. Taki selektor zwykle wygląda zwyczajnie, ale właśnie to jest jego siłą: jest krótki, zrozumiały i odporny na większość kosmetycznych zmian interfejsu. Jeśli mam wybierać między efektownym XPath-em a prostym locatorem, który działa po kolejnym wdrożeniu, wybieram ten drugi.