
Pokrycie testami to jedna z najpraktyczniejszych metryk w automatyzacji: pokazuje, które fragmenty kodu uruchamiają testy, a które nadal pozostają poza ich zasięgiem. W praktyce test coverage pomaga szybko ocenić, gdzie testy dają realną ochronę, a gdzie zespół tylko ma wrażenie bezpieczeństwa. Ten tekst rozkłada temat na konkretne decyzje: jak czytać wynik, jakie typy pokrycia mają sens, dlaczego sam procent potrafi mylić i jak poprawiać sytuację bez pisania testów „na sztukę”.
Najważniejsze rzeczy o pokryciu testami
- Metryka pokazuje wykonanie kodu przez testy, a nie to, czy logika jest poprawna.
- Sam wysoki procent nie gwarantuje jakości, bo test może uruchamiać linię, ale niczego nie weryfikować.
- Pokrycie gałęzi i warunków zwykle mówi więcej niż samo pokrycie linii.
- Najpierw mierzę nowy kod i krytyczne ścieżki, a dopiero potem patrzę na globalny procent.
- Dobry próg zależy od ryzyka, złożoności modułu i dojrzałości bazy testów.
- Coverage działa najlepiej jako sygnał diagnostyczny, a nie jako jedyny cel pracy zespołu.
Jak czytać wynik pokrycia testami w praktyce
Najpierw trzeba odczarować samą metrykę. Pokrycie mówi, które fragmenty kodu zostały wykonane podczas uruchamiania testów, ale nie odpowiada na pytanie, czy testy dobrze sprawdziły zachowanie aplikacji. To ważne rozróżnienie, bo w projektach produktowych widzę regularnie sytuację, w której zespół ma wysoki procent pokrycia, a mimo to wpada na błędy w logice biznesowej, wyjątkach albo walidacji danych.
Dlatego ja traktuję tę metrykę jak mapę luk, nie jak pieczątkę jakości. Jeśli raport pokazuje, że jakiś moduł ma niskie pokrycie, to nie znaczy automatycznie, że jest zły. Zwykle oznacza raczej, że warto zajrzeć głębiej: czy brakuje tam testów jednostkowych, czy kod jest trudny do izolacji, czy może zespół testuje głównie „happy path”. Narzędzia typu SonarQube dodatkowo rozróżniają pokrycie kodu od wykonania samych testów, więc sam wykres bez kontekstu potrafi wprowadzić w błąd. Z tego powodu następny krok to nie gonienie liczb, tylko zrozumienie, co właściwie mierzymy.
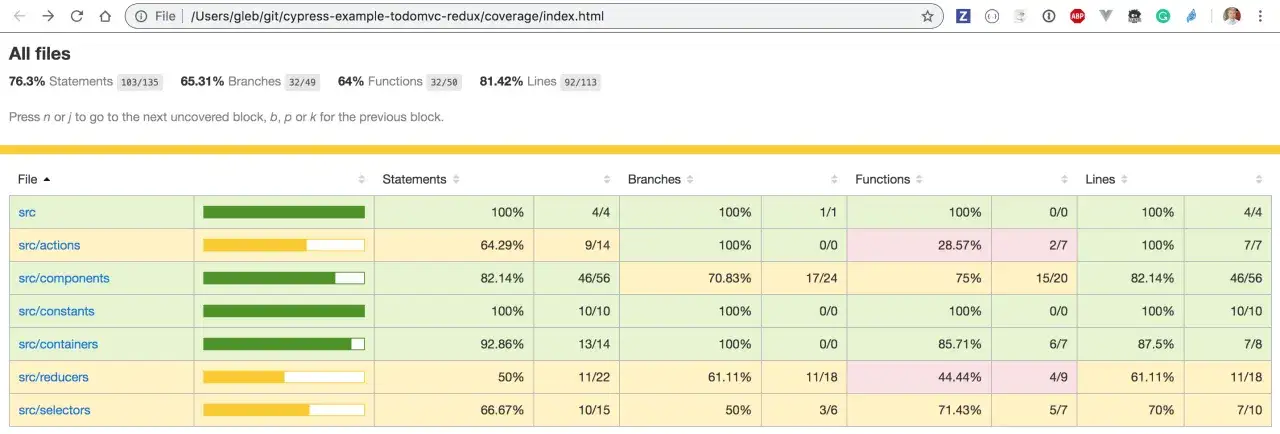
Jakie rodzaje pokrycia mają sens przy automatyzacji
Nie każda odmiana pokrycia mówi tyle samo. W praktyce najwięcej wartości daje mi porównanie kilku perspektyw, bo każda odkrywa inny rodzaj luki. Najprościej widać to w poniższym zestawieniu.
| Rodzaj pokrycia | Co pokazuje | Kiedy jest najbardziej użyteczny | Ograniczenie |
|---|---|---|---|
| Pokrycie linii | Które linie kodu zostały wykonane przez testy | Jako szybki punkt startowy i prosty sygnał regresji | Łatwo „nabić” je testami, które tylko przechodzą po kodzie |
| Pokrycie gałęzi | Czy testy weszły w różne ścieżki warunków, np. if/else | Przy logice decyzyjnej, walidacjach i obsłudze wyjątków | Bywa trudniejsze do osiągnięcia, ale zwykle jest bardziej wartościowe niż same linie |
| Pokrycie warunków | Czy pojedyncze warunki logiczne były oceniane w różnych stanach | Przy złożonych wyrażeniach boolean i regułach biznesowych | Wymaga większej dyscypliny testowej i dokładniejszego projektowania przypadków |
| Pokrycie funkcji lub metod | Czy dana funkcja została w ogóle wywołana | Na początku pracy z nowym modułem i przy szybkim przeglądzie obszarów bez testów | Nie mówi nic o jakości asercji wewnątrz testu |
Jeśli mam wybór, patrzę najpierw na gałęzie i warunki, a dopiero potem na linie. Pokrycie linii jest użyteczne, ale w dłuższej perspektywie może dawać zbyt optymistyczny obraz. W praktyce lepszy sygnał dostaję wtedy, gdy widzę, czy testy przechodzą przez odmienne ścieżki decyzji, a nie tylko wykonują ten sam blok kodu w kółko. Z tego powodu sam procent warto czytać razem z charakterem testów, a nie w oderwaniu od nich.
Dlaczego wysoki procent nie gwarantuje dobrych testów
To jeden z najczęstszych błędów w zespołach, które dopiero dojrzewają do automatyzacji. Można mieć 90 procent pokrycia i nadal nie sprawdzać niczego ważnego. Dzieje się tak wtedy, gdy test uruchamia kod, ale nie stawia sensownych asercji, albo kiedy pokrywa wyłącznie prostą ścieżkę działania, podczas gdy błędy kryją się w wyjątkach, granicach i alternatywnych warunkach wejściowych.
- Test może wejść w linię, ale nie zweryfikować wyniku biznesowego.
- Mocki mogą odtwarzać tylko „szczęśliwą ścieżkę”, przez co błąd w obsłudze błędów zostaje niewidoczny.
- Jedna rozbudowana asercja może formalnie dać pokrycie, ale nie zwiększy odporności systemu.
- Pokrycie nie mówi nic o tym, czy test jest stabilny, czy łatwo się psuje przy refaktorze.
Ja zwykle przypominam zespołowi prostą zasadę: pokrycie odpowiada na pytanie „czy kod był uruchomiony?”, a nie „czy kod działa poprawnie?”. To rozróżnienie jest kluczowe, bo bez niego łatwo zamienić automatyzację w produkcję zielonych raportów. Z tego powodu kolejny krok nie polega na podkręcaniu procenta, tylko na poprawie jakości samych scenariuszy.
Jak zwiększać pokrycie bez pisania testów na siłę
Najlepsze efekty daje nie mechaniczne dopisywanie testów, lecz uporządkowane podejście do miejsc, które naprawdę niosą ryzyko. W praktyce zaczynam od krytycznych przepływów, bo tam brak testów ma największą cenę: logowanie, płatności, walidację danych, przetwarzanie zamówień, zmiany stanu i integracje z zewnętrznymi usługami.
- Wydziel logikę biznesową od I/O, czyli od baz danych, API i systemów plików. Im prostszy kod domenowy, tym łatwiej go sensownie testować.
- Dodaj przypadki graniczne: wartości puste, null, zero, limity, błędne formaty i wyjątki. To często daje więcej niż kolejne testy na standardową ścieżkę.
- Sprawdzaj gałęzie decyzji, a nie tylko główny przebieg. Jeśli w kodzie jest if, to dobrze jest mieć test, który wchodzi w obie strony.
- Rozbij duże testy na mniejsze, jeśli obejmują kilka zachowań naraz. Krótsze testy łatwiej utrzymać i precyzyjniej diagnozują błędy.
- Unikaj duplikowania przypadków, które wykonują te same linie. Dwa testy przechodzące identyczną ścieżką rzadko są równie wartościowe jak dwa różne scenariusze.
W legacy code nie próbuję zwykle „naprawić wszystkiego” jednym sprintem. Wolę krokowy model: najpierw zabezpieczam obszary ryzyka, potem poprawiam projekt kodu, a dopiero później podnoszę wynik. Takie podejście daje realną wartość, bo zespół widzi mniej regresji, a nie tylko wyższy procent na dashboardzie. I to prowadzi wprost do pytania, jaki próg w ogóle ma sens ustawить.
Jak ustalać sensowne progi w zespole i w CI
Nie ma uniwersalnego progu, który byłby dobry dla każdego projektu. Ja wolę patrzeć na ryzyko, złożoność i dojrzałość bazy testów. Mimo to przydają się robocze widełki, bo pomagają szybko ocenić sytuację bez udawania, że każdy procent znaczy to samo.
| Zakres | Jak to odczytuję | Co bym zrobił dalej |
|---|---|---|
| Poniżej 50% | Pokrycie jest raczej szczątkowe, a luki są szerokie | Skupiłbym się na krytycznych ścieżkach i podstawowych przypadkach granicznych |
| 50-70% | Jest już jakaś baza, ale brakuje spójności i głębi | Ustawiłbym ochronę przed regresją, zwłaszcza dla nowego kodu |
| 70-85% | To zwykle zdrowy poziom dla wielu modułów, jeśli testy są sensowne | Rozszerzałbym pokrycie tam, gdzie ryzyko biznesowe jest największe |
| Powyżej 85% | Wygląda dobrze, ale nadal trzeba sprawdzić jakość asercji i scenariuszy | Ograniczyłbym pogoń za procentem i zaczął kontrolować głównie nowe zmiany |
W praktyce najrozsądniejszy model to osobny próg dla nowego kodu i osobny dla całego repozytorium. Globalny próg potrafi być pułapką, bo stary, trudny do refaktoryzacji moduł zaniża wynik i blokuje rozwój, mimo że nowa funkcjonalność jest testowana dobrze. Dlatego w CI bardziej ufałbym bramce jakości dla nowych zmian niż sztywnej liczbie dla całego projektu. To podejście zwykle lepiej wspiera automatyzację niż jednorazowe podkręcanie metryki.
Najczęstsze błędy, które fałszują obraz jakości
Największy problem z pokryciem zaczyna się wtedy, gdy traktuje się je jak cel sam w sobie. Wtedy zespół zaczyna optymalizować raport, a nie produkt. Z mojej perspektywy najczęściej psują obraz jakości cztery rzeczy: liczenie tylko linii, ignorowanie nowych i starych obszarów osobno, włączanie plików generowanych do raportu oraz mylenie uruchomienia kodu z jego sprawdzeniem.
- Pomijanie pokrycia gałęzi sprawia, że testy wyglądają lepiej, niż są w rzeczywistości.
- Wliczanie kodu generowanego lub technicznego rozmywa wynik i utrudnia interpretację.
- Brak podziału na nowe i stare obszary utrudnia ocenę, czy zespół faktycznie poprawia jakość pracy.
- Testy bez mocnych asercji dają zielony raport, ale nie chronią przed regresją.
- Gonienie za 100 procentami bywa kosztowne i często ma niewielki zwrot z inwestycji.
Jeżeli miałbym wskazać jeden praktyczny test jakości metryki, to byłaby to odpowiedź na pytanie: czy po wzroście pokrycia spadła liczba błędów lub skrócił się czas wykrywania regresji? Jeśli nie, sam procent niewiele znaczy. I właśnie dlatego ostatni krok polega na tym, żeby z metryki zrobić narzędzie do decyzji, a nie ozdobę raportu.
Jak zamienić metrykę w realny sygnał dla zespołu
Najlepsze zespoły nie ścigają się na liczby, tylko używają pokrycia jako jednego z sygnałów jakości. Ja zwykle łączę je z przeglądem kodu, analizą defektów, czasem z mutation testingiem i z prostą zasadą: jeśli ważna ścieżka biznesowa nie ma testów, to problem jest pilniejszy niż kolejny procent na dashboardzie. Taka dyscyplina działa lepiej niż ślepa wiara w sam wskaźnik.
Jeśli mam zostawić jedną praktyczną rekomendację, to tę: mierz pokrycie tam, gdzie ryzyko jest realne, a nie tam, gdzie najłatwiej uzyskać dobry wynik. Gdy połączysz to z rozróżnieniem na nowe i stare moduły, z sensownym podziałem na linie, gałęzie i warunki oraz z testami, które naprawdę sprawdzają zachowanie systemu, metryka zaczyna pomagać podejmować decyzje. Wtedy pokrycie testami przestaje być liczbą „do raportu”, a staje się użytecznym narzędziem w automatyzacji.