
Szybka weryfikacja poprawności ma jeden cel: w kilka minut potwierdzić, że świeża zmiana nie naruszyła najważniejszej logiki systemu. W praktyce sanity check to krótki, celowy test punktowy, który pomaga odsiać oczywiste błędy zanim zespół straci godzinę na dalsze testy lub wdrożenie. Poniżej pokazuję, kiedy taki test ma sens, jak go dobrze zaplanować, czym różni się od smoke testu i jak nie zamienić go w rytuał bez wartości.
Szybki test poprawności sprawdza tylko to, co musi działać po zmianie
- Sprawdza wyłącznie najważniejsze ścieżki po zmianie: logowanie, zapis, płatność, walidację albo kluczowy endpoint API.
- Najlepiej pasuje po hotfixie, zmianie konfiguracji, poprawce błędu lub małej funkcji.
- W praktyce powinien zamykać się w 5-15 minutach, a jeśli trwa dłużej, zakres zwykle jest zbyt szeroki.
- Nie zastępuje smoke testu ani regresji, tylko działa jako szybki filtr ryzyka.
- Najlepsze efekty daje z krótką checklistą, jasnym kryterium zaliczenia i środowiskiem podobnym do produkcyjnego.
Czym jest szybka weryfikacja poprawności i co naprawdę sprawdza
Ja traktuję ją jako najmniejszy sensowny test, który ma odpowiedzieć na jedno pytanie: czy po konkretnej zmianie system nadal zachowuje się logicznie tam, gdzie ryzyko jest największe. To może być poprawka w walidacji formularza, zmiana w backendzie, nowy warunek biznesowy albo korekta integracji z zewnętrznym API. Nie chodzi o pełną pewność, tylko o szybkie odrzucenie sytuacji, w której zespół powinien natychmiast wrócić do debugowania albo wycofać build.
Taki test zwykle obejmuje jedną do trzech krytycznych ścieżek. Jeśli nagle zaczynasz sprawdzać dziesięć ekranów, pięć ról i trzy integracje, to nie jest już szybka kontrola poprawności, tylko mini-regresja. Dla mnie granica jest prosta: zakres ma być wąski, ale sprawdzany na tyle głęboko, by wykryć błąd, którego nie złapałby sam build lub pojedynczy test jednostkowy. Żeby nie mieszać pojęć, warto od razu zestawić tę technikę z najbliższymi jej testami.
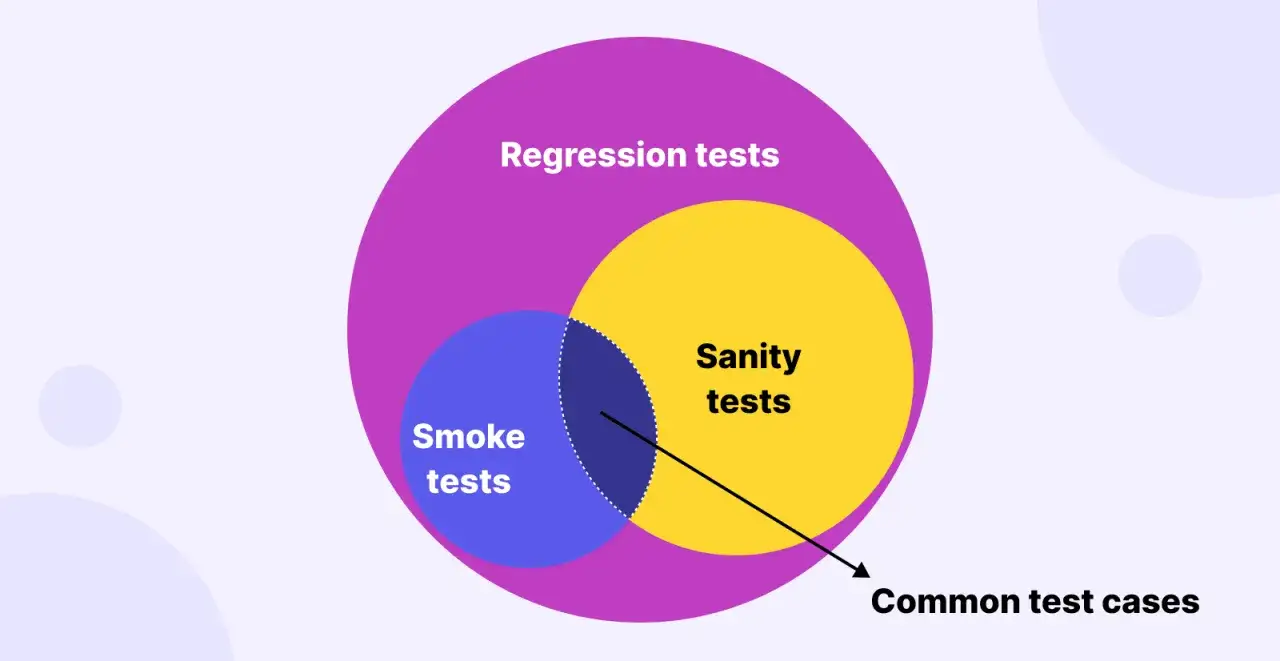
Jak odróżnić ją od smoke testu i regresji
| Cecha | Szybka weryfikacja poprawności | Smoke test | Regresja |
|---|---|---|---|
| Cel | Potwierdzić, że konkretna zmiana działa i nie psuje kluczowej logiki | Sprawdzić, czy build w ogóle nadaje się do dalszych testów | Wykryć niepożądane skutki zmian w szerszym obszarze |
| Zakres | Wąski i celowy | Szeroki, ale płytki | Szeroki lub selektywny, zależnie od ryzyka |
| Moment | Po poprawce, hotfixie, zmianie konfiguracji albo drobnej funkcji | Po nowym buildzie, przed głębszym testowaniem | Po większym zestawie zmian, przed release |
| Typowe wykonanie | Często manualne, czasem półautomatyczne | Coraz częściej automatyczne | Automatyczne, manualne albo mieszane |
| Co daje | Szybką odpowiedź, czy zmieniony fragment działa | Informację, czy można iść dalej z testami | Szerszą ochronę przed regresją |
| Czego nie daje | Nie potwierdza jakości całego systemu | Nie sprawdza szczegółowej logiki biznesowej | Nie jest błyskawicznym filtrem po małej poprawce |
W praktyce nazwy bywają mylone, szczególnie w zespołach, które nie mają spisanych definicji. Dlatego nie przywiązuję się do etykiety bardziej niż do pytania, co dokładnie ma zostać sprawdzone. Jeśli test ma potwierdzić, że poprawiony obszar działa po zmianie, mówimy o szybkim sprawdzeniu poprawności; jeśli ma udowodnić, że cały build nadaje się do dalszego testowania, jesteśmy bliżej smoke testu. Skoro granice są już jasne, można przejść do samego wykonania.
Jak przeprowadzić ją krok po kroku
- Opisz zmianę jednym zdaniem. Zanim cokolwiek uruchomię, chcę wiedzieć, co dokładnie się zmieniło: reguła walidacji, endpoint, integracja, ekran czy konfiguracja.
- Wybierz 3-5 krytycznych punktów kontrolnych. To ma być minimalny zestaw, który odpowiada na realne ryzyko. Przy małej poprawce nie potrzebujesz dwudziestu kroków.
- Przygotuj dane i środowisko. Jeśli testujesz logowanie, potrzebujesz aktywnego konta. Jeśli płatność, musisz mieć przewidziany scenariusz i odpowiedni stan zamówienia. Brak danych potrafi zabić sens testu szybciej niż sam błąd.
- Uruchom tylko to, co jest potrzebne. Nie rozpraszam się dodatkowymi ekranami i pobocznymi przypadkami, jeśli one nie zwiększają pewności co do zmienionego fragmentu.
- Porównaj wynik z oczekiwaniem. Ważne jest nie tylko to, że system się nie wywalił, ale też to, czy zwraca właściwy komunikat, status, kwotę, uprawnienie albo stan obiektu.
- Zapisz decyzję. Krótkie „pass/fail” z jedną notatką o tym, co sprawdzono, oszczędza pytania po godzinie i pomaga przy kolejnym wdrożeniu.
W dobrze poukładanym zespole cały proces zamyka się zwykle w 5-10 minutach. Jeśli test rośnie do 15-20 minut, to często znak, że zakres jest za szeroki albo że nie ma jednej, czytelnej checklisty. Następny krok to wybór formy wykonania, bo nie każdy przypadek wymaga tego samego podejścia.
Jakie metody wykonania sprawdzają się najlepiej
| Metoda | Kiedy ma sens | Zalety | Ograniczenia | Typowy czas |
|---|---|---|---|---|
| Manualna | Po hotfixie, małej zmianie, incydencie lub poprawce UI | Szybka, elastyczna, łatwa do uruchomienia bez dużego przygotowania | Zależna od człowieka, bardziej podatna na pominięcia | 5-15 minut |
| Półautomatyczna | Gdy ścieżka jest powtarzalna, ale nadal chcesz mieć kontrolę nad wynikiem | Łączy szybkość z powtarzalnością | Wymaga skryptu, danych testowych i utrzymania | 1-5 minut |
| Automatyczna | W CI/CD, przy częstych deployach i dobrze opisanych ścieżkach krytycznych | Najlepsza jako stała bramka jakości | Może być kosztowna w utrzymaniu i podatna na niestabilność, jeśli środowisko jest słabe | Sekundy lub kilka minut |
Ja najczęściej wybieram model hybrydowy. Najpierw ręcznie weryfikuję nowy lub ryzykowny obszar, a potem przenoszę powtarzalne kroki do automatu. To działa szczególnie dobrze tam, gdzie zmiana jest często wdrażana, ale nadal wymaga zdrowego rozsądku człowieka. Gdy metoda jest już dobrana, najwięcej wartości dają konkretne scenariusze.
Przykłady, które naprawdę warto sprawdzić po zmianie
Najlepsze scenariusze są nudne, bo dotyczą miejsc, od których zależy podstawowe działanie systemu. Właśnie tam jedna drobna pomyłka potrafi zablokować użytkownika albo zniekształcić dane. Poniżej podaję przypadki, które w praktyce najczęściej mają sens.
- Logowanie i sesja. Po zmianie w autoryzacji sprawdzam logowanie, odświeżenie tokena i wylogowanie. To ważne, bo błędy w tym obszarze potrafią wyglądać jak pojedynczy incydent, a w rzeczywistości psują całą aplikację.
- Checkout w e-commerce. Jeśli zmienia się rabat, koszt dostawy albo integracja płatnicza, testuję przejście od koszyka do potwierdzenia zamówienia. Tu liczy się nie tylko poprawny status, ale też właściwa kwota i stan zamówienia.
- Kluczowy endpoint API. Po zmianie walidacji sprawdzam odpowiedź dla poprawnych i niepoprawnych danych. Warto zwrócić uwagę na kod statusu, treść błędu i to, czy obiekt został zapisany zgodnie z regułą biznesową.
- Webhook lub integrację zewnętrzną. Jeśli system wysyła dane do partnera, sprawdzam jeden pełny przepływ: wysyłka, odpowiedź, retry i zapis wyniku. W integracjach błąd często nie leży w samym kodzie, tylko w kontrakcie między systemami.
- Uprawnienia w panelu administracyjnym. Po zmianie ról lub polityki dostępu sprawdzam, czy użytkownik widzi tylko to, co powinien. To jeden z tych obszarów, gdzie szybki test potrafi ujawnić błąd o dużym wpływie biznesowym.
Najczęstsze błędy i ograniczenia
- Zbyt szeroki zakres. Jeśli po drobnej zmianie zaczynasz sprawdzać pół systemu, test przestaje być szybki i traci sens operacyjny.
- Brak jasnego kryterium zaliczenia. Samo „wygląda dobrze” nie wystarcza. Potrzebny jest konkretny wynik: status, komunikat, stan rekordu albo efekt biznesowy.
- Uruchamianie na niestabilnym środowisku. Jeśli środowisko testowe różni się od produkcyjnego o kluczowe integracje, wynik może być mylący.
- Mylenie tego testu z regresją. Szybka kontrola ma złapać najważniejszy problem, a nie udowodnić pełną poprawność systemu.
- Brak danych testowych. Bez przygotowanych kont, stanów zamówień, tokenów lub stubów integracji test zamienia się w improwizację.
- Ignorowanie niestabilności testu. Jeśli wynik raz przechodzi, a raz nie, problemem nie jest tylko kod aplikacji. Czasem to test, dane albo środowisko są zbyt chwiejne, żeby dawać wiarygodny sygnał.
Ja patrzę na tę technikę jak na filtr ryzyka, nie jak na dowód jakości. To bardzo użyteczne narzędzie, ale tylko wtedy, gdy ktoś świadomie akceptuje jego ograniczenia. Żeby to nie było jednorazowe ćwiczenie, warto włączyć je w codzienną pracę zespołu.
Co zostawić w procesie, żeby szybka kontrola działała długo
Najlepiej działa prosty, powtarzalny układ: krótka lista kontrolna, znany właściciel, jasne kryterium zaliczenia i miejsce, w którym zapisujesz wynik. Jeśli zespół robi to z pamięci, po trzech sprintach pojawiają się skróty myślowe, pominięcia i rozjazd w interpretacji. Jeśli robi to z dokumentu lub skryptu, łatwiej utrzymać spójność.
- Zapisz checklistę obok kodu lub w repozytorium, a nie w prywatnych notatkach.
- Trzymaj zestaw kroków krótki, najlepiej do 3-7 punktów.
- Oddziel ścieżki krytyczne od przypadków pobocznych.
- Dodaj prostą regułę: jeśli test trwa dłużej niż 15 minut, wróć do zakresu.
- Automatyzuj to, co się powtarza, i zostaw człowiekowi ocenę tam, gdzie liczy się kontekst.
- Co jakiś czas sprawdzaj, czy zestaw kroków nadal odpowiada realnemu ryzyku po zmianach w produkcie.
Jeśli miałbym zostawić jedną regułę, byłaby prosta: szybka weryfikacja ma skracać decyzję, a nie ją zastępować. Dobrze działa wtedy, gdy każdy w zespole wie, co sprawdza, jak długo trwa, kiedy kończy się sukcesem i w którym momencie trzeba przejść do pełniejszego testu. Właśnie taka dyscyplina sprawia, że krótki test poprawności oszczędza czas, zamiast produkować fałszywe poczucie bezpieczeństwa.