
Test dymny, czyli smoke test, to najszybsza forma sprawdzenia, czy nowa wersja aplikacji w ogóle nadaje się do dalszej pracy. W praktyce taki przegląd chroni zespół przed marnowaniem czasu na głębsze testy, kiedy system nie przechodzi nawet podstawowego startu, logowania albo zapisu danych. Poniżej pokazuję, co powinien obejmować dobry zestaw kontrolny, kiedy go automatyzować i gdzie najczęściej traci sens.
Najważniejsze fakty, które warto znać przed wdrożeniem testu dymnego
- To szybka weryfikacja krytycznych ścieżek po buildzie lub wdrożeniu, a nie pełny przegląd jakości.
- Dobry zestaw obejmuje zwykle 3-10 scenariuszy, nie kilkadziesiąt przypadków.
- Jeśli test nie przejdzie, dalsze testowanie powinno się zatrzymać do czasu naprawy.
- Najczęściej sprawdza się uruchomienie aplikacji, logowanie, zapis danych i kluczowe integracje.
- Automatyzacja ma sens wtedy, gdy te same kroki powtarzają się często i środowisko jest stabilne.
Czym jest test dymny i kiedy ma sens
Najprościej ujmując, to szybka bramka wejściowa: sprawdzam, czy build albo świeżo wdrożona wersja systemu działa na poziomie podstawowym. W materiałach ISTQB ten typ kontroli jest traktowany jako sposób na potwierdzenie, że wersja nadaje się do dalszych testów, a nie jako pełna ocena jakości produktu. Ja patrzę na niego jak na filtr, który ma odpowiedzieć na jedno pytanie: czy w ogóle warto iść dalej?
Taki test uruchamia się najczęściej po kompilacji, po wdrożeniu na środowisko testowe albo po wypchnięciu nowej wersji na produkcję w modelu canary. W praktyce to właśnie wtedy widać najwięcej problemów z integracją, konfiguracją, migracją danych albo samym startem aplikacji. Jeśli ta warstwa nie przechodzi, dalsze testy tylko spalają czas.
W polskich zespołach częściej mówi się po prostu o teście dymnym niż o angielskim określeniu, ale sens pozostaje ten sam: najpierw weryfikacja podstaw, dopiero potem głębsze sprawdzanie. Skoro tak, trzeba ustalić, co dokładnie powinno znaleźć się w takim zestawie.
Co powinien sprawdzać dobry zestaw kontrolny
Największy błąd, jaki widzę, to próba upchnięcia do testu dymnego wszystkiego, co wydaje się ważne. To nie ma działać jak regresja. Ma być krótkie, powtarzalne i odporne na przypadkowe zmiany w interfejsie.
Ścieżki, które muszą działać
Dobry zestaw powinien obejmować przede wszystkim te kroki, bez których użytkownik nie ruszy dalej. W praktyce są to zwykle 3-10 scenariuszy, a nie 30. Gdy liczba kroków rośnie do 15 i więcej, test zaczyna przypominać małą regresję i traci swoją funkcję szybkiej bramki.
| Typ systemu | Co sprawdzić | Dlaczego to ważne |
|---|---|---|
| Aplikacja webowa | Start, logowanie, wejście na dashboard, wykonanie jednej kluczowej akcji | To najszybciej ujawnia problemy z backendem, sesją lub frontem |
| API | Health endpoint, autoryzacja, odczyt i zapis kluczowego zasobu | Jeśli API nie odpowiada, reszta testów nie ma sensu |
| E-commerce | Wejście na stronę, wyszukiwanie produktu, koszyk, checkout w sandboxie | Tu szybko widać, czy ścieżka sprzedażowa działa od początku do końca |
| Aplikacja mobilna | Uruchomienie, połączenie z kontem, synchronizacja, otwarcie kluczowego ekranu | Błędy startowe w mobile'u są szczególnie kosztowne, bo blokują całe użycie aplikacji |
Przeczytaj również: Skuteczne testowanie oprogramowania - Jak podnieść jakość produktu?
Elementy techniczne, których nie widać na pierwszy rzut oka
Poza ścieżką użytkownika sprawdzam też minimum techniczne: czy aplikacja łączy się z bazą danych, czy odpowiada zewnętrzne API, czy działa kolejka wiadomości i czy mechanizm logowania nie wywala się przy pierwszym żądaniu. To są rzeczy, które użytkownik zwykle odczuwa dopiero po chwili, ale w testach powinny wyjść od razu.
Jeśli test dymny ma być naprawdę użyteczny, nie może być zbyt głęboki. Wystarczy potwierdzić, że rdzeń produktu żyje. Wszystko poniżej tego poziomu należy już do innych rodzajów testów. Z takiego rozróżnienia naturalnie wynika pytanie, jak odróżnić tę metodę od sanity testu i regresji.
Jak odróżnić go od sanity testu i regresji
W praktyce zespoły często mieszają te pojęcia, a potem dziwią się, że pipeline blokuje coś, co miało być tylko szybkim checkiem. Ja wolę rozdzielać je twardo, bo wtedy łatwiej ustalić, który zestaw testów ma blokować wdrożenie, a który służy tylko do szybkiej oceny.
| Cecha | Test dymny | Sanity test | Regresja |
|---|---|---|---|
| Cel | Sprawdzić, czy system działa na poziomie podstawowym | Potwierdzić, że konkretna poprawka działa w obszarze zmiany | Sprawdzić, czy zmiana nie zepsuła innych funkcji |
| Zakres | Szeroki, ale płytki | Wąski i trochę głębszy | Szeroki i zwykle bardziej szczegółowy |
| Moment uruchomienia | Po buildzie lub wdrożeniu | Po drobnej poprawce lub hotfixie | Przed wydaniem lub po większej zmianie |
| Czas | Minuty | Minuty do kilkunastu minut | Od kilkunastu minut do godzin |
| Pytanie, na które odpowiada | Czy system żyje? | Czy ta konkretna zmiana działa? | Czy nic innego się nie rozsypało? |
Wiele firm używa tych nazw zamiennie, ale to nie pomaga. Ważniejsze od etykiet jest to, czy zespół wie, co dokładnie ma zatrzymać release, a co jest tylko sygnałem do dalszej diagnostyki. Kiedy ten porządek jest jasny, można przejść do samego procesu uruchamiania.
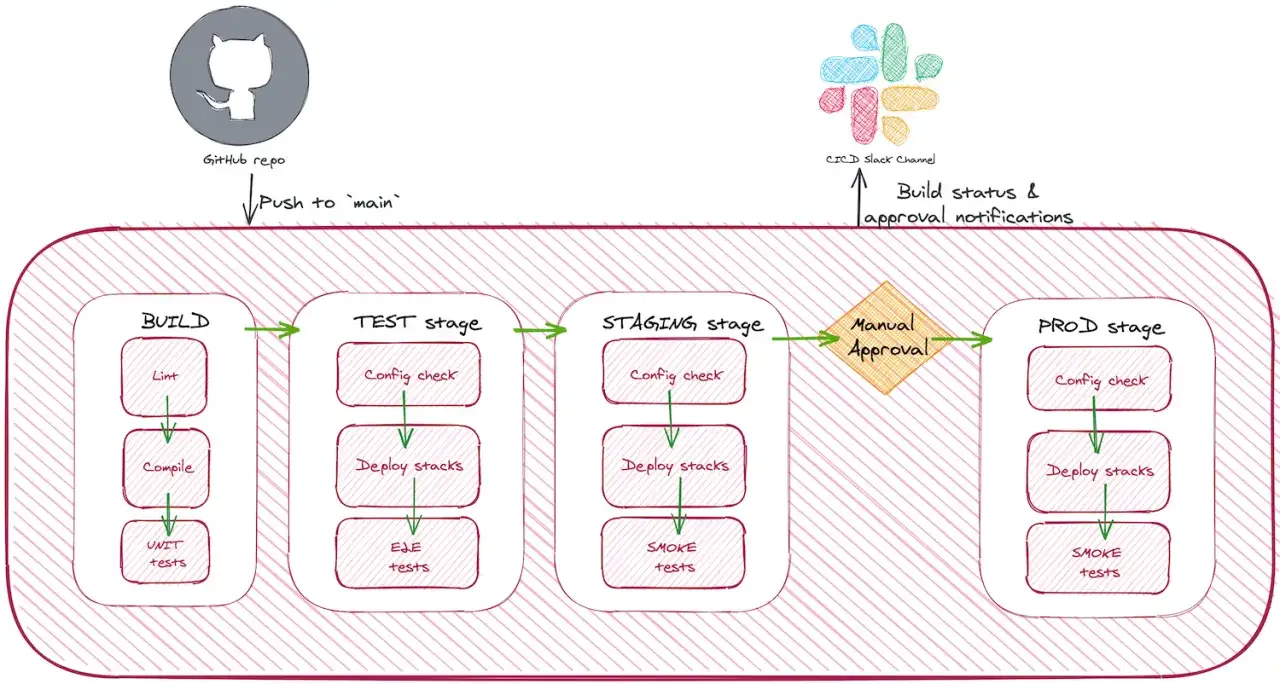
Jak przeprowadzić go krok po kroku
Najlepszy test dymny jest prosty, powtarzalny i ma jasno zdefiniowaną decyzję końcową. Nie chodzi o to, by znaleźć wszystkie defekty. Chodzi o to, by szybko odsiać wersję, która nie powinna trafić dalej.
- Ustal punkt wejścia. Zanim cokolwiek uruchomisz, potwierdź, że build jest zidentyfikowany, środowisko gotowe, a dane testowe przygotowane.
- Sprawdź start aplikacji. Jeśli system nie otwiera się poprawnie, nie ma sensu przechodzić dalej.
- Przejdź przez 3-5 krytycznych akcji. Wystarczy login, jedna operacja biznesowa i zapis wyniku, jeśli to odpowiada produktowi.
- Zweryfikuj integracje. Jedno lub dwa połączenia z bazą, kolejką albo zewnętrznym API zwykle wystarczą na tym etapie.
- Oceń logi i metryki. Gdy coś wygląda podejrzanie, sprawdź błędy 4xx/5xx, czas odpowiedzi i komunikaty w logach.
- Podejmij decyzję bez negocjacji. Jeśli którykolwiek krytyczny krok padnie, test jest niezaliczony i dalsze testowanie powinno się zatrzymać.
Najważniejsza zasada brzmi: jeden fail powinien oznaczać jasny stop. Jeżeli zespół zaczyna dyskutować, czy jeszcze „da się testować dalej”, to znaczy, że test nie ma już roli bramki. Kiedy proces działa przewidywalnie, pojawia się kolejne pytanie: czy opłaca się go automatyzować.
Kiedy automatyzacja pomaga, a kiedy przeszkadza
Automatyzacja ma sens wtedy, gdy te same kroki wykonuje się często, a środowisko jest na tyle stabilne, że test nie będzie co chwilę fałszywie padał. Flaky test, czyli test niestabilny, który raz przechodzi, a raz nie bez zmiany w kodzie, jest tutaj szczególnie groźny. Taki automat nie oszczędza czasu, tylko dokłada hałas.
| Wariant | Kiedy go wybieram | Zalety | Ograniczenia |
|---|---|---|---|
| Ręczny | Na początku projektu, przy niestabilnym UI, przy małej liczbie wydań | Szybki start, mały koszt wejścia, łatwo wychwycić problemy wizualne | Zależność od człowieka, większe ryzyko pomyłki i mniejsza powtarzalność |
| Automatyczny | Przy częstych deployach, stabilnych ścieżkach i pipeline CI/CD | Powtarzalność, szybki feedback, możliwość blokowania wdrożenia | Wymaga utrzymania, może być kruchy przy zmianach interfejsu |
| Hybrydowy | W większości zespołów, które chcą połączyć szybkość z kontrolą jakości | Dobry balans między kosztem a skutecznością | Wymaga dyscypliny w doborze zakresu i regularnej aktualizacji |
W praktyce staram się, by automatyczny zestaw kończył się w 1-5 minutach, a ręczny przegląd nie przekraczał 5-15 minut. Gdy test zaczyna trwać 20-30 minut, zwykle nie jest już szybkim filtrem, tylko zbyt cienką regresją. Wtedy lepiej odchudzić zakres niż udawać, że wszystko nadal mieści się w tej samej kategorii.
Najbardziej opłaca się automatyzować kroki o wysokiej powtarzalności: uruchomienie systemu, logowanie, jedną kluczową akcję biznesową i wylogowanie. Wszystko, co wymaga kreatywnej oceny, ręcznego klikania po niestabilnym UI albo dziwnych danych przygotowywanych ad hoc, zwykle zostawiam poza takim zestawem. To prowadzi do najczęstszych błędów.
Najczęstsze błędy, które odbierają mu wartość
- Zbyt szeroki zakres. Kiedy test próbuje sprawdzać pół aplikacji, przestaje być szybki i zaczyna konkurować z regresją.
- Brak stabilnych danych. Jeśli każdorazowo trzeba ręcznie przygotowywać środowisko, test będzie opóźniał cały proces.
- Za dużo zależności zewnętrznych. Gdy jedna usługa trzecia pada co drugi dzień, wynik testu staje się mało wiarygodny.
- Brak jasnego progu fail. Bez prostego kryterium zespół zaczyna interpretować wynik zamiast działać.
- Mylenie z regresją. Test dymny ma potwierdzić podstawy, a nie udowodnić pełną zgodność produktu ze specyfikacją.
- Za dużo asercji w UI. Asercja to warunek, który test ma spełnić. Im więcej drobnych sprawdzeń wyglądu, tym większa kruchość.
Jeżeli miałbym wskazać jeden objaw ostrzegawczy, byłby to test, który każdy w zespole interpretuje inaczej. Wtedy problemem nie jest technika, tylko brak wspólnej definicji i właściciela procesu. Gdy to jest uporządkowane, test dymny zaczyna realnie chronić wdrożenia.
Na co patrzę, gdy test dymny ma chronić wdrożenia
W projektach, które wdrażają często, nie patrzę już tylko na sam wynik testu. Patrzę też na to, czy proces daje szybki obraz ryzyka po deployu i czy potrafi uratować zespół przed wypuszczeniem wadliwej wersji szerzej. Sama kontrola techniczna to za mało, jeśli nie ma jasnego planu reakcji.
- Rollback. Jeśli wersja nie przechodzi podstawowej weryfikacji, trzeba wiedzieć, jak szybko wrócić do stabilnej wersji.
- Monitoring. Warto od razu sprawdzić błędy, czasy odpowiedzi i alerty z logów, a nie czekać, aż zrobi to użytkownik.
- Canary lub feature flag. To dobry sposób, by ograniczyć ryzyko i nie wystawiać całego ruchu na jedną nową wersję.
- Właściciel reakcji. Ktoś musi mieć jasną odpowiedzialność za decyzję, że wdrożenie zatrzymujemy albo wycofujemy.
- Minimalny zestaw startowy. Jeśli dopiero budujesz proces, zacznij od pięciu kroków: uruchomienie aplikacji, logowanie, jedna kluczowa akcja biznesowa, zapis danych i sprawdzenie logów.
Taki rdzeń zwykle daje najlepszy zwrot przy najmniejszym koszcie. Dopiero później dorzucałbym kolejne scenariusze, jeśli naprawdę pojawiają się nowe ryzyka, które trzeba wyłapać wcześniej. Właśnie tak rozumiem dobrze zrobiony test dymny: ma być mały, szybki i bezdyskusyjny, bo tylko wtedy rzeczywiście oszczędza czas całemu zespołowi.