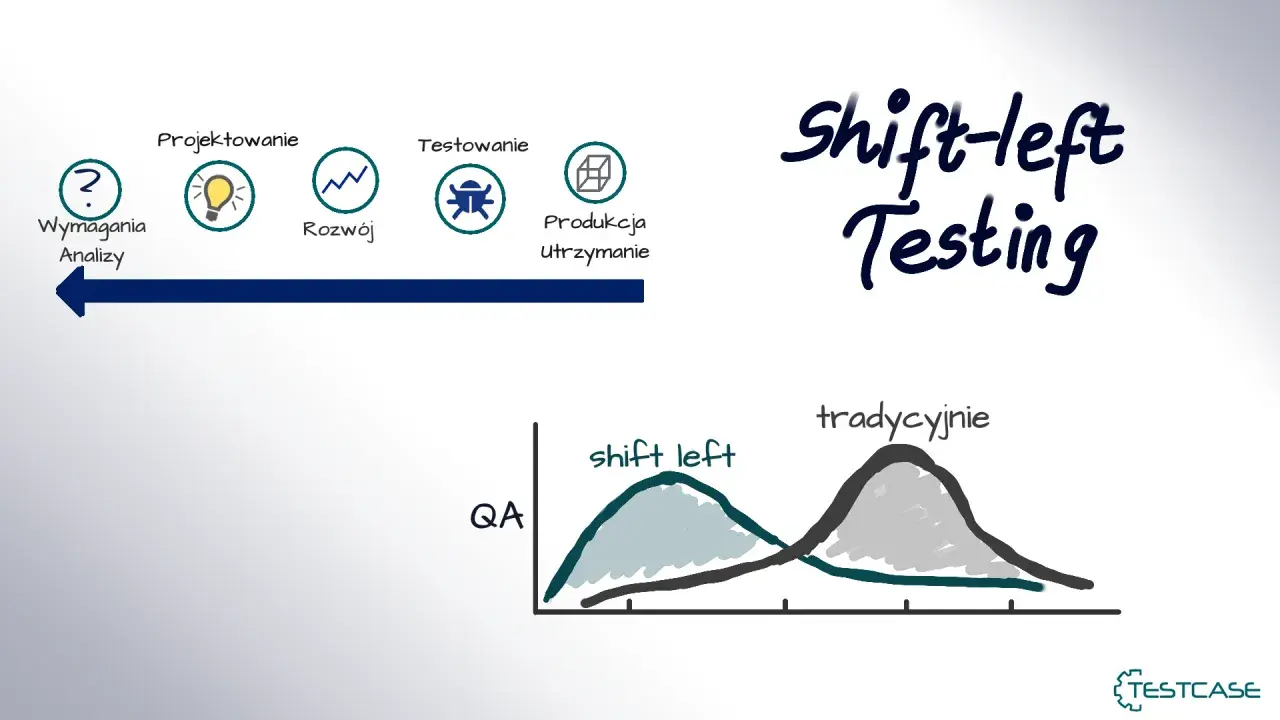
W dobrze prowadzonym procesie QA testowanie nie zaczyna się dopiero po zakończeniu developmentu. Im wcześniej zespół wychwyci niejasne wymagania, błędną logikę albo konflikt integracyjny, tym mniej kosztownych poprawek trafia do końcowej fazy wydania. To właśnie sedno podejścia shift left testing: przesunąć kontrolę jakości bliżej momentu powstawania kodu, a nie odkładać ją na sam koniec. W tym tekście pokazuję, jak to działa w praktyce, które testy warto przenieść wcześniej i jak uniknąć typowych błędów wdrożeniowych.
Najkrócej mówiąc, jakość zaczyna się wcześniej niż sama implementacja
- Shift-left oznacza wspólne projektowanie jakości przez QA, developerów i osoby decyzyjne, a nie tylko wcześniejsze uruchamianie testów.
- Największy zysk daje szybki feedback: błędy łapie się, gdy są jeszcze małe i łatwe do naprawienia.
- Najlepiej przenosić wcześniej testy jednostkowe, API, kontraktowe, statyczną analizę i część kontroli bezpieczeństwa.
- Testy end-to-end i eksploracyjne nadal są potrzebne, ale nie powinny dźwigać całego procesu jakości.
- Bez stabilnego pipeline’u, danych testowych i jasnej odpowiedzialności shift-left łatwo zamienia się w slogan bez efektu.
Co naprawdę oznacza testowanie przesunięte w lewo
Najczęstsze nieporozumienie jest proste: wiele osób myśli, że chodzi wyłącznie o to, by testy uruchamiać wcześniej. To za mało. W praktyce chodzi o to, by jakość wkroczyła do procesu już na etapie wymagań, projektowania, implementacji i pierwszej integracji, a nie dopiero wtedy, gdy produkt „prawie jest gotowy”. Ja patrzę na to jak na zmianę sposobu myślenia: QA nie jest bramką na końcu, tylko elementem budowania rozwiązania od pierwszej decyzji.
W dobrze ustawionym procesie wcześniej pojawiają się pytania o kryteria akceptacji, ryzyko, zależności między usługami i oczekiwane zachowanie systemu. Tester nie czeka biernie na gotowy build, tylko pomaga doprecyzować to, co ma zostać zbudowane, oraz wskazuje miejsca, w których późniejsza weryfikacja byłaby już zbyt kosztowna. To jest właśnie różnica między „testowaniem po pracy” a podejściem, w którym jakość jest częścią pracy od początku. Skoro wiemy, o co chodzi, warto zobaczyć, co to zmienia w codziennej pracy zespołu QA.
Dlaczego to podejście tak dobrze działa w procesach QA
Największa korzyść jest bardzo praktyczna: błędy wychwycone wcześnie są zwykle prostsze, tańsze i mniej bolesne do naprawy. Jeśli problem pojawi się na etapie wymagania albo pierwszej implementacji, poprawka często oznacza jedną zmianę w kodzie lub dokumentacji. Jeśli ten sam problem dotrze do końca sprintu, zaczyna dotykać testów regresji, integracji, release’u i czasem nawet kilku zespołów jednocześnie. Wtedy koszt rośnie nie dlatego, że sam bug jest „większy”, tylko dlatego, że urósł jego kontekst.
Drugim efektem jest krótsza pętla informacji zwrotnej. Developer szybciej widzi, że coś nie działa, a QA nie musi czekać na pełny, ciężki cykl testów, by zareagować. To poprawia też współpracę: osoby projektujące funkcje, piszące kod i weryfikujące go zaczynają patrzeć na ten sam problem z różnych stron, zanim jeszcze utrwali się zły kierunek. W efekcie zespół nie tylko wydaje szybciej, ale też rzadziej wraca do tych samych usterek. Różnica najlepiej widać, gdy porówna się klasyczny model z pracą ustawioną na wcześniejsze wykrywanie ryzyka.
| Obszar | Tradycyjny model QA | Podejście przesunięte w lewo |
|---|---|---|
| Moment wykrycia błędu | Na końcu cyklu lub tuż przed wydaniem | Podczas projektowania, kodowania lub pierwszej integracji |
| Rola QA | Końcowa bramka jakości | Współtwórca kryteriów, automatyzacji i analizy ryzyka |
| Rodzaj pracy | Duże, ciężkie testy regresji | Krótka pętla: testy jednostkowe, API, statyczna analiza, szybka integracja |
| Koszt poprawki | Wysoki, bo problem dotyka już kilku warstw | Zwykle niższy, bo błąd jest świeży i lokalny |
| Ryzyko przed releasem | Duża kumulacja defektów | Mniej niespodzianek, ale tylko przy dobrej automatyzacji |
To nie znaczy, że każda organizacja natychmiast zyskuje na samym przesunięciu testów. Korzyść pojawia się dopiero wtedy, gdy zmieni się też sposób pracy, odpowiedzialność i sposób podejmowania decyzji. I właśnie dlatego warto przejść od teorii do konkretnego wdrożenia.
Jak wdrożyć to bez rozbijania procesu zespołu
Ja zwykle zaczynam od dwóch pytań: czy wymaganie da się jednoznacznie przetestować i czy zespół ma możliwość dostać wynik testu wystarczająco szybko, by jeszcze zareagować na niego w tym samym dniu pracy. Jeśli odpowiedź na oba pytania brzmi „nie”, to problemem nie jest brak testów, tylko zła organizacja procesu. Wtedy warto iść krok po kroku, a nie próbować naraz przebudować całego QA.
Zacznij od wymagań i kryteriów akceptacji
Największe oszczędności zaczynają się nie w testach, tylko w doprecyzowaniu tego, co w ogóle ma zostać zbudowane. Dobre kryteria akceptacji, spisane razem z biznesem i developmentem, zmniejszają liczbę sporów na końcu. Jeśli coś nie da się sprawdzić, to zwykle znaczy, że wymaganie jest zbyt ogólne albo ma kilka możliwych interpretacji. W praktyce wolę wyłapać taki problem na warsztacie niż po tygodniu implementacji.
Włącz automatyzację tam, gdzie daje najszybszy zwrot
Najlepszym kandydatem do wcześniejszego testowania są obszary stabilne, powtarzalne i ważne biznesowo. Tu świetnie sprawdzają się testy jednostkowe oraz API. Testy jednostkowe weryfikują logikę małego fragmentu kodu, a testy API sprawdzają komunikację między usługami bez ciężaru interfejsu użytkownika. Właśnie tam najłatwiej zbudować szybki, wiarygodny feedback.
Ustal wspólną odpowiedzialność za jakość
Shift-left nie działa, jeśli QA zostaje zepchnięte do roli „osoby od klikania na końcu”. Z mojego punktu widzenia zespół wygrywa wtedy, gdy developerzy piszą część testów, QA projektuje strategię ryzyka, a product owner pilnuje sensu biznesowego scenariuszy. Taka współpraca nie oznacza rozmycia odpowiedzialności, tylko jej lepszy podział. Każdy wie, za co odpowiada, a jakość nie jest już jednym wąskim gardłem.
Przeczytaj również: QA w IT - Zbuduj proces, który wspiera rozwój produktu
Spraw, by feedback był naprawdę szybki
Automatyzacja ma sens tylko wtedy, gdy wynik wraca szybko i jest czytelny. Jeśli pipeline trwa długo, testy są niestabilne albo raport nie pokazuje, co faktycznie się zepsuło, cały model traci sens. Dla mnie dobre wdrożenie zaczyna się tam, gdzie zespół może uruchomić zmianę, dostać informację zwrotną i poprawić błąd bez przełączania się w tryb gaszenia pożaru. Właśnie dlatego warto wiedzieć, które typy testów przenosić wcześniej, a które zostawić na później.
Które testy warto przenieść wcześniej, a których nie należy wypychać na siłę
Nie wszystkie testy zyskują na przesunięciu do lewej strony procesu. W praktyce najlepiej sprawdzają się te, które są szybkie, deterministyczne i tanie w utrzymaniu. Poniżej pokazuję, jak patrzę na najważniejsze grupy testów.
| Typ testu | Dlaczego warto go zrobić wcześniej | Ograniczenie, o którym trzeba pamiętać |
|---|---|---|
| Testy jednostkowe | Szybko sprawdzają logikę biznesową i łatwo wskazują źródło błędu | Nie zastąpią sprawdzenia współpracy kilku komponentów |
| Testy API i integracyjne | Łapią błędy w komunikacji między usługami i warstwami systemu | Wymagają dobrze kontrolowanych środowisk i danych testowych |
| Testy kontraktowe | Sprawdzają, czy dwa systemy nadal rozumieją się tak samo po zmianie | Są szczególnie ważne w architekturze mikroserwisowej, ale trzeba je utrzymywać konsekwentnie |
| Static analysis i linting | Wykrywają błędy bez uruchamiania aplikacji, często jeszcze przed commitem | Nie potwierdzają zachowania biznesowego, tylko jakość kodu i zgodność ze standardem |
| Sprawdzenia bezpieczeństwa | Pozwalają wcześnie wykrywać luki w kodzie, zależnościach i konfiguracji | Wymagają sensownej selekcji reguł, by nie zalać zespołu fałszywymi alarmami |
| Testy eksploracyjne | Pomagają znaleźć nieoczywiste problemy UX i błędy scenariuszy | Nie da się ich w pełni zautomatyzować, więc najlepiej traktować je jako uzupełnienie |
| Testy end-to-end | Potwierdzają kluczowe ścieżki użytkownika w prawdziwym przepływie | Powinny być nieliczne i krytyczne, bo zbyt łatwo stają się wolne i kruche |
Jeśli miałbym uprościć temat do jednego zdania, najwięcej sensu ma przenoszenie wcześniej testów, które są szybkie, przewidywalne i dobrze izolują problem. Tam, gdzie zależności są ciężkie, a scenariusz mocno przypomina realne zachowanie użytkownika, lepiej nie udawać, że wszystko da się rozwiązać jednym typem testu. To prowadzi do drugiej strony medalu: kilka pozornie rozsądnych decyzji potrafi zniszczyć cały efekt.
Najczęstsze błędy, które zamieniają dobrą ideę w frustrację
Najczęściej widzę pięć potknięć. Pierwsze to mylenie wcześniejszego testowania z samym przyspieszaniem pipeline’u. Jeśli testy są uruchamiane wcześniej, ale nadal są wolne, kruche i nieczytelne, to zespół dostaje tylko wcześniejsze zmęczenie, a nie lepszą jakość.
- Przesuwanie odpowiedzialności bez wsparcia - gdy developerom mówi się tylko „macie testować więcej”, ale nie daje im się czasu, standardów i narzędzi, jakość zwykle spada zamiast rosnąć.
- Budowanie zbyt ciężkich testów na każdym poziomie - jeśli wszystko staje się testem end-to-end, pipeline zamienia się w wąskie gardło, a debugowanie jest coraz trudniejsze.
- Brak stabilnych danych i środowisk - bez powtarzalnych danych testowych nawet dobry zestaw testów daje losowe wyniki i zabija zaufanie do całego procesu.
- Liczenie liczby testów zamiast jakości informacji - duża liczba przypadków nie jest sukcesem, jeśli nikt nie potrafi na podstawie wyniku podjąć decyzji.
- Ignorowanie utrzymania automatyzacji - testy też się starzeją; gdy produkt się zmienia, nieaktualny zestaw testów zaczyna ukrywać problemy zamiast je wykrywać.
Drugi częsty błąd to zbyt duża wiara w jeden rodzaj sprawdzenia. Sam unit test nie ochroni przed błędną integracją, a sam E2E nie naprawi złej logiki w kodzie. Najlepsze zespoły budują warstwy testów, a nie jeden rozdmuchany mechanizm, który ma rzekomo załatwić wszystko. I właśnie tutaj wchodzi temat granic: kiedy warto pójść dalej, a kiedy trzeba dołożyć obserwację produkcyjną.
Kiedy potrzebujesz też testów po wdrożeniu
W systemach opartych na wielu usługach, zewnętrznych API i dynamicznym ruchu użytkowników wcześniejsze testy są konieczne, ale nie wystarczają. Nie wszystko da się przewidzieć w stagingu, bo prawdziwe problemy często ujawniają się dopiero pod realnym obciążeniem, z prawdziwymi danymi i z zachowaniem użytkowników, którego nie da się w pełni zasymulować. Dlatego dojrzały proces nie kończy się na przesunięciu testów w lewo.
W takich środowiskach dokładam testy po wdrożeniu: monitoring, alerting, testy syntetyczne, canary release i obserwowalność, czyli możliwość śledzenia zachowania systemu przez logi, metryki i trace’y. To nie jest krok wstecz. To sposób na domknięcie pętli jakości tam, gdzie ryzyko wykracza poza to, co można zweryfikować przed produkcją. Jeśli zewnętrzny dostawca zmieni API, jeśli wystąpi problem tylko przy konkretnym wzorcu ruchu albo jeśli regresja ujawni się dopiero w produkcyjnej konfiguracji, właśnie te mechanizmy pozwalają zareagować szybko i bez zgadywania.
Najlepsze efekty widzę wtedy, gdy zespół nie wybiera między wcześniejszym testowaniem a obserwacją produkcji, tylko łączy oba podejścia w jeden spójny proces. To dla mnie najbardziej uczciwa definicja dojrzałego QA: nie więcej testów dla zasady, tylko lepiej rozłożona odpowiedzialność za jakość. Jeśli mam wskazać jeden praktyczny punkt startowy, to wybrałbym mały obszar produktu, jeden pipeline i kilka najważniejszych scenariuszy, a potem mierzyłbym nie liczbę uruchomień, tylko to, czy spada liczba regresji i skraca się czas od zmiany do wiarygodnej informacji zwrotnej.