
Łączenie systemów rzadko psuje się w miejscu, które widać na pierwszy rzut oka. Najczęściej problemy wychodzą dopiero na styku API, bazy danych, kolejek, płatności albo usług zewnętrznych, czyli dokładnie tam, gdzie QA musi sprawdzić nie tylko kod, ale też przepływ danych i odpowiedzialności między komponentami. W tym artykule pokazuję, jak wygląda integracja oprogramowania w praktyce testowej, jakie techniki dają najlepszy efekt i jak zbudować proces, który wyłapuje błędy zanim trafią do użytkownika.
Najważniejsze rzeczy, które warto wiedzieć od razu
- Najwięcej błędów integracyjnych wynika z rozjazdu kontraktów, danych, wersji i konfiguracji środowisk.
- Testy jednostkowe nie wystarczą, bo nie sprawdzają współpracy między usługami, bazą, kolejką czy zewnętrznym API.
- Najlepszy efekt daje miks testów kontraktowych, integracyjnych i kilku krytycznych testów end-to-end.
- Stabilne środowisko i dane testowe są równie ważne jak sam kod testów.
- CI/CD powinno dawać szybki sygnał, a nie zamieniać się w długi, losowy koszmar z fałszywymi alarmami.
- Najlepszy QA przy integracjach zaczyna się od ryzyka, a nie od liczby uruchomionych testów.
Czym w QA jest integracja i gdzie kończy się test jednostkowy
Dla mnie integracja w QA to nie tylko „spięcie” kodu, ale potwierdzenie, że dwa lub więcej elementów systemu rozumieją się tak samo: używają tych samych pól, tych samych typów danych, tych samych kodów błędów i tych samych zasad autoryzacji. Test jednostkowy sprawdza logikę wewnętrzną w izolacji, natomiast test integracyjny odpowiada na prostsze, ale ważniejsze pytanie: czy komponenty faktycznie współpracują, gdy wyjdą poza bezpieczne granice mocków.
To rozróżnienie ma duże znaczenie w zespołach pracujących z mikrousługami, czyli małymi usługami wdrażanymi niezależnie. Lokalnie wszystko może wyglądać dobrze, ale jeśli kontrakt API się rozjedzie, kolejka wiadomości ma inny schemat niż zakłada konsument albo baza zwraca inny format daty, błąd pojawi się dopiero tam, gdzie system zaczyna działać razem. W praktyce właśnie tu QA znajduje najdroższe regresje.
Ja patrzę na integrację jako na warstwę ochronną między „kod działa” a „cały produkt działa”. To właśnie ten dystans najczęściej zdradza brak synchronizacji między zespołami, wersjami i środowiskami, więc w kolejnym kroku warto zobaczyć, gdzie takie rozjazdy pojawiają się najczęściej.Gdzie najczęściej psuje się przepływ danych
W praktyce większość awarii nie wynika z jednego wielkiego błędu, tylko z drobnych różnic, które na papierze wyglądają niewinnie. Najczęstsze miejsca zapalne są dość powtarzalne i warto je sprawdzać osobno, zamiast liczyć na to, że test „wszystkiego naraz” sam je odkryje.
| Miejsce problemu | Jak to wygląda w praktyce | Na co patrzę w QA |
|---|---|---|
| Kontrakt API | Jedna usługa wysyła pole w innym formacie albo zmienia nazwę bez ostrzeżenia. | Zgodność schematu, typów, wymaganych pól i kodów odpowiedzi. |
| Autoryzacja i sesje | Token wygasa za szybko, ma złe scope albo nie działa w środowisku testowym. | Odświeżanie tokenów, uprawnienia, scenariusze błędów i przekierowania. |
| Asynchroniczne przetwarzanie | Wiadomość trafia do kolejki, ale druga strona przetwarza ją z opóźnieniem albo w złej kolejności. | Retry, idempotencja, kolejność zdarzeń i obsługa duplikatów. |
| Dane testowe | Test przechodzi raz, a potem nie, bo stan środowiska się zmienił. | Izolacja danych, czyszczenie po testach i przewidywalny setup. |
| Konfiguracja środowiska | Inna wersja biblioteki, inny endpoint albo inny timeout niż w produkcji. | Parzystość konfiguracji, wersjonowanie i kontrola zależności. |
| Integracje zewnętrzne | Sandbox dostawcy działa inaczej niż środowisko produkcyjne, ma limity albo symuluje tylko część zachowań. | Różnice między sandboxem a produkcją, limity, błędy graniczne i fallback. |
W polskich projektach bardzo często dochodzi jeszcze temat zgodności z RODO i maskowania danych. Jeśli system przetwarza dane osobowe, testowanie na żywych rekordach albo bez kontroli anonimizacji zwykle kończy się albo ryzykiem prawnym, albo chaosem w danych testowych. Kiedy wiem już, gdzie przepływ najczęściej pęka, mogę zbudować proces, który wyłapuje te miejsca wcześniej, a nie dopiero po wdrożeniu.
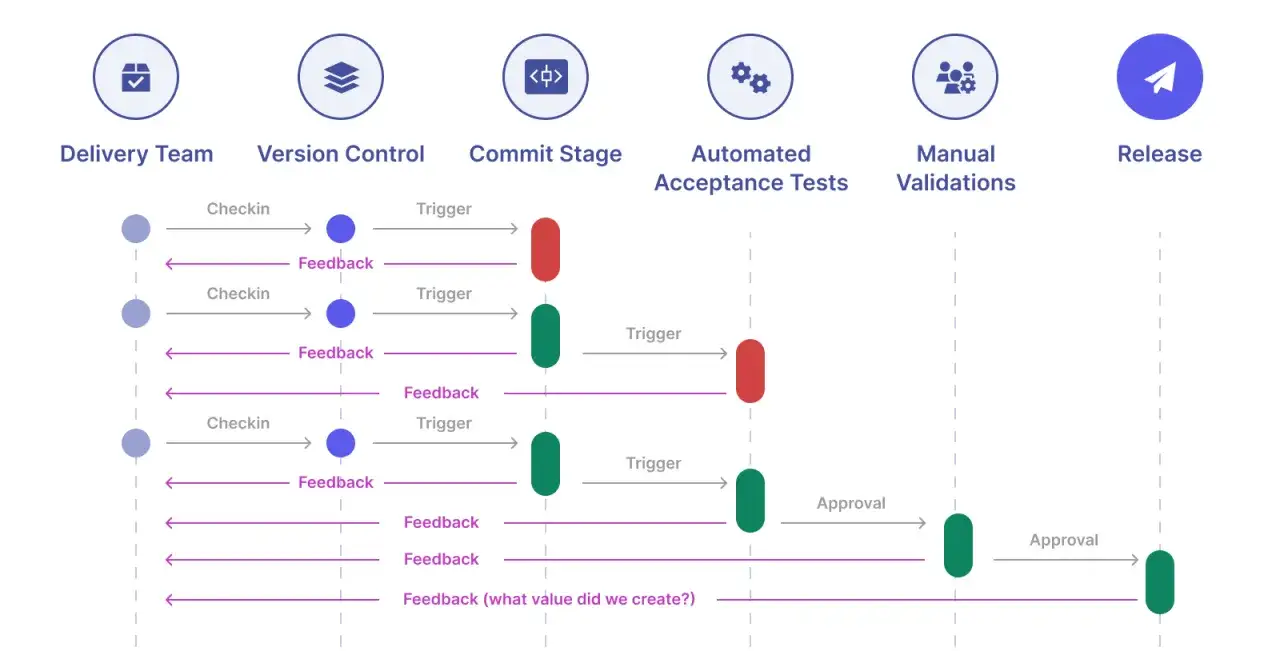
Jak zbudować proces testów integracyjnych krok po kroku
Dobry proces zaczyna się od ryzyka, nie od liczby testów. Ja zwykle układam go w kilku prostych krokach, bo wtedy łatwiej utrzymać porządek, łatwiej też zdecydować, co ma działać przy każdym pull requeście, a co może poczekać do nocnej regresji.
- Zidentyfikuj krytyczne punkty styku - API, kolejki, bazy, pliki, płatności, logowanie, wysyłkę maili i wszystko to, co może zatrzymać przepływ biznesowy.
- Opisz oczekiwany kontrakt - czyli formalnie ustal, jakie dane są wymagane, co jest opcjonalne, jakie błędy są dopuszczalne i jak wygląda odpowiedź w scenariuszu negatywnym.
- Przygotuj środowisko, które da się kontrolować - nie musi być identyczne z produkcją w każdym detalu, ale musi odtwarzać najważniejsze zachowania i zależności.
- Zapewnij powtarzalne dane - testy powinny wiedzieć, od jakiego stanu startują i jakie są reguły czyszczenia po wykonaniu.
- Automatyzuj tylko to, co ma sens - szybkie, krytyczne integracje powinny iść do CI, a cięższe scenariusze można zostawić do cyklicznego uruchamiania.
- Dodaj czytelną diagnostykę - logi, identyfikatory żądań, ślad zdarzeń i jasne komunikaty błędów skracają czas analizy o wiele bardziej niż kolejny retry.
Jeśli mam wskazać jedną zasadę praktyczną, to brzmi ona tak: nie testuję wszystkiego na każdym poziomie. Lepiej utrzymać krótki zestaw sprawdzający najważniejsze zależności niż rozdmuchać pipeline do rozmiaru, którego nikt nie ufa. I właśnie tu pojawia się pytanie, które techniki naprawdę pomagają, a które tylko wyglądają dobrze na diagramie.
Które techniki QA najlepiej wspierają integrację
W realnym projekcie nie wybieram jednego rodzaju testów, tylko zestaw, który pasuje do ryzyka. Najlepsze efekty daje połączenie kilku technik, bo każda z nich łapie inny typ błędów i ma inne koszty utrzymania.
| Technika | Co sprawdza | Kiedy używam | Ograniczenia |
|---|---|---|---|
| Testy jednostkowe | Logikę pojedynczej funkcji, klasy lub modułu. | Na etapie szybkiej regresji logiki biznesowej. | Nie widzą realnej współpracy z innymi systemami. |
| Testy integracyjne | Połączenie dwóch lub więcej komponentów, na przykład API i bazy danych. | Gdy chcę sprawdzić prawdziwą współpracę usług i warstw infrastruktury. | Są wolniejsze i bardziej wrażliwe na środowisko oraz dane. |
| Testy kontraktowe | Zgodność komunikacji między producentem i konsumentem danych. | W systemach, gdzie zespoły rozwijają usługi niezależnie i często się versionują. | Nie zastępują pełnego przepływu biznesowego end-to-end. |
| Testy end-to-end | Całą ścieżkę użytkownika od wejścia do efektu końcowego. | Do kilku najważniejszych scenariuszy, na przykład rejestracji, płatności lub złożenia zamówienia. | Są najcięższe, najbardziej kruche i najdroższe w utrzymaniu. |
| Wirtualizacja usług | Zachowanie zależności, których nie chcę uruchamiać w pełni w teście. | Gdy zewnętrzny system jest niedostępny, drogi albo niestabilny. | Może ukryć błąd, jeśli model zachowania jest nieaktualny. |
Największą różnicę robią u mnie testy kontraktowe, bo pozwalają wykryć rozjazd specyfikacji zanim wejdzie on w kosztowne testy pełnej ścieżki. To nie znaczy, że zastępują integrację end-to-end, ale dobrze ustawiają priorytety i oszczędzają wiele fałszywych alarmów. Taki zestaw ma jednak sens tylko wtedy, gdy pipeline i środowiska są ułożone rozsądnie, więc do tego przechodzę teraz.
Jak ustawić CI/CD, żeby testy naprawdę pomagały
CI/CD, czyli ciągła integracja i ciągłe dostarczanie, ma sens tylko wtedy, gdy daje szybki i wiarygodny sygnał. Jeśli pipeline trwa za długo, ma losowe błędy albo zależy od jednego współdzielonego środowiska, zespół przestaje mu ufać i zaczyna omijać proces. Wtedy jakość spada, nawet jeśli na papierze „wszystko jest zautomatyzowane”.
Szybka bramka na pull requestach
Na każdym pull requeście trzymam krótki zestaw testów, które sprawdzają rzeczy najdroższe z punktu widzenia biznesu: kontrakty, najważniejsze integracje i kilka krytycznych ścieżek. Resztę przenoszę do kolejnej warstwy, bo nie każdy test musi blokować pracę całego zespołu. Jeśli pipeline zaczyna zachowywać się jak sieć z losowymi awariami, problem zwykle nie leży w samych testach, tylko w ich złym rozmieszczeniu.
Stabilne środowiska i dane
Najczęściej psuje się nie logika, tylko stan. Współdzielone środowiska, dane używane przez wiele testów naraz i brak czyszczenia po uruchomieniu robią z QA loterię. Ja wolę krótszy test, który zawsze daje ten sam wynik, niż rozbudowany scenariusz wymagający trzech ręcznych poprawek, żeby w ogóle ruszył. Jeśli test potrzebuje dwóch albo trzech powtórzeń, zwykle najpierw sprawdzam jego stabilność, a dopiero potem obwiniam aplikację.
Przeczytaj również: Testowanie SPA - Jak zapewnić przewidywalność aplikacji?
Obserwowalność zamiast zgadywania
W dobrze ustawionym procesie nie wystarczy wiedzieć, że coś padło. Trzeba jeszcze wiedzieć, gdzie i dlaczego. Dlatego przy integracjach przydają się identyfikatory żądań, sensowne logi, metryki czasu odpowiedzi i ślad przepływu przez kilka usług. To skraca analizę bardziej niż dokładanie kolejnych retry, które często tylko maskują problem.
Ja zwykle układam to w trzech warstwach: szybka bramka na pull requestach, szersza weryfikacja po scaleniu i pełniejsza regresja uruchamiana cyklicznie. Taki model jest dużo bardziej odporny na chaos niż próba przepchnięcia wszystkiego jednym zestawem testów. Zostaje jeszcze ostatni filtr, czyli lista rzeczy, które sprawdzam przed wdrożeniem, żeby nie przenosić ryzyka na produkcję.
Co sprawdzam przed wdrożeniem, żeby nie przenosić ryzyka na produkcję
Przed wydaniem patrzę nie tylko na wynik testów, ale też na to, czy zespół naprawdę ma kontrolę nad punktami styku. To krótka lista, ale w praktyce właśnie ona decyduje o tym, czy integracja jest stabilna, czy tylko „na szczęście jeszcze działa”.
- Czy kontrakty są aktualne i czy obie strony komunikacji pracują na tej samej wersji schematu.
- Czy dane testowe są bezpieczne i nie mieszają informacji produkcyjnych z testowymi.
- Czy krytyczne ścieżki mają monitoring, żeby awaria była widoczna od razu, a nie po skardze użytkownika.
- Czy rollback jest realny, a nie tylko opisany w dokumencie, którego nikt nie ćwiczył.
- Czy wiadomo, kto odpowiada za każdy punkt styku, bo bez ownera błędy integracyjne zbyt łatwo krążą między zespołami.
Jeśli miałbym zostawić jedną praktyczną zasadę, brzmiałaby tak: najpierw zabezpiecz kontrakty i krytyczne przepływy danych, dopiero potem rozbudowuj kolejne warstwy testów. W dobrym QA nie chodzi o to, żeby sprawdzić wszystko wszędzie, tylko o to, żeby jak najszybciej wykryć miejsca, w których dwa poprawne moduły przestają działać razem.