
Dobre testy nie zaczynają się od narzędzia, tylko od decyzji, co naprawdę trzeba ochronić przed błędem. W praktyce testowanie i jakość oprogramowania to zestaw metod, które pomagają wykrywać defekty wcześnie, utrzymać tempo zmian i nie zamienić wdrożeń w loterię. W tym artykule pokazuję, jakie metody testowania działają najlepiej w różnych sytuacjach, kiedy automatyzacja ma sens, a kiedy lepiej postawić na ręczną analizę i eksplorację.
Najkrócej, skuteczne testy łączą kilka poziomów i kilka technik
- Testy statyczne łapią część problemów zanim kod w ogóle ruszy w środowisku.
- Automatyzacja najlepiej sprawdza się tam, gdzie scenariusz jest powtarzalny i biznesowo ważny.
- Eksploracja ręczna wykrywa defekty, których nie widać w sztywnych skryptach.
- Piramida testów pomaga ograniczyć koszt utrzymania i liczbę fałszywych alarmów.
- Testy niefunkcjonalne są konieczne, gdy wydajność, bezpieczeństwo albo dostępność wpływają na sukces produktu.
Czym różni się testowanie od zapewniania jakości
Ja zwykle zaczynam od rozróżnienia dwóch pojęć, które bywają wrzucane do jednego worka. Testowanie odpowiada na pytanie, czy system działa zgodnie z oczekiwaniem, a zapewnianie jakości obejmuje szerszy zestaw działań: od doprecyzowania wymagań, przez przeglądy kodu, po monitoring po wdrożeniu. To ważne, bo sama liczba testów nie naprawi źle opisanego wymagania ani chaotycznego procesu pracy.
W praktyce dobre QA obejmuje między innymi:
- przegląd wymagań i kryteriów akceptacji,
- code review i analizę statyczną,
- spójne środowiska testowe i dane testowe,
- automatyzację powtarzalnych sprawdzeń,
- monitoring błędów i metryk po wdrożeniu.
Jeśli ten podział jest jasny, dużo łatwiej dobrać właściwą metodę do problemu, a nie tylko do etapu sprintu.
Jakie metody testowania warto znać w praktyce
W projektach, które prowadzę, rzadko wygrywa jedna „najlepsza” metoda. Zwykle działa miks kilku podejść, bo każde z nich odpowiada na inne pytanie i ma inne ograniczenia.
| Metoda | Co sprawdza | Kiedy ma sens | Typowe ograniczenie |
|---|---|---|---|
| Testy statyczne | Wymagania, kod, konfigurację i dokumentację bez uruchamiania programu | Przed merge’em, w analizie PR, przy przeglądzie wymagań | Nie pokażą błędu integracji ani zachowania w runtime |
| Testy manualne funkcjonalne | Czy aplikacja działa z perspektywy użytkownika | Nowe funkcje, złożone ścieżki, obszary z dużym ryzykiem UX | Są wolniejsze i trudniejsze do skalowania niż automatyzacja |
| Testy automatyczne regresji | Czy istniejące zachowania nie psują się po zmianach | Powtarzalne scenariusze, CI/CD, częste releasy | Wymagają stałego utrzymania i stabilnych środowisk |
| Testy eksploracyjne | Nieoczywiste defekty, luki UX i błędy wynikające z kombinacji zachowań | Wczesne wersje, nowe moduły, obszary o wysokim ryzyku | Trudniej je odtworzyć bez notatek i dobrego zapisu obserwacji |
| Testy kontraktowe | Czy usługi lub API nadal „rozumieją się” tak samo | Microservices, integracje między zespołami, systemy API | Nie zastąpią pełnego testu end-to-end |
W systemach z wieloma integracjami testy kontraktowe często dają lepszy zwrot niż dokładanie kolejnych testów interfejsu użytkownika. To jeden z tych obszarów, gdzie mniej efektowna metoda bywa po prostu bardziej rozsądna.
Gdy mam już taki zestaw, przechodzę do pytania, jak projektować konkretne przypadki testowe, żeby nie testować wszystkiego po równo.
Jak dobieram technikę projektowania testów do ryzyka
Metoda testowania to jedno, a technika projektowania przypadków testowych to drugie. Tu najczęściej pracuję trzema podejściami: czarnoskrzynkowym, białoskrzynkowym i szaroskrzynkowym. Każde z nich widzi system z innej strony, więc użyte razem dają pełniejszy obraz.
- Black-box skupia się na wejściach, wyjściach i regułach biznesowych. Dobrze sprawdza się przy formularzach, koszykach zakupowych, autoryzacji i walidacjach.
- White-box korzysta ze znajomości kodu, gałęzi warunków i logiki wewnętrznej. Jest szczególnie przydatny tam, gdzie błąd w obliczeniach lub ścieżce warunkowej jest kosztowny.
- Grey-box łączy perspektywę użytkownika z wiedzą o architekturze. To dobry kompromis w systemach API i usługach, które trzeba zrozumieć od środka, ale testować z zewnątrz.
Do tego dokładam techniki, które porządkują przypadki testowe:
- Podział na klasy równoważności pozwala grupować dane, które powinny zachowywać się podobnie, zamiast sprawdzać każdy możliwy wariant.
- Analiza wartości brzegowych koncentruje się na granicach zakresu, bo właśnie tam najczęściej pojawiają się błędy.
- Tabele decyzyjne pomagają ogarnąć kombinacje reguł, na przykład rabaty, role użytkowników albo statusy zamówień.
- Testy przejść stanów sprawdzają, czy system poprawnie reaguje na zmianę statusu, na przykład z „draft” do „published”.
Jeśli dobrze dobieram te techniki, potrafię ograniczyć liczbę testów bez utraty pokrycia ryzyka. A to prowadzi prosto do pytania, jak ułożyć z tego sensowną piramidę.
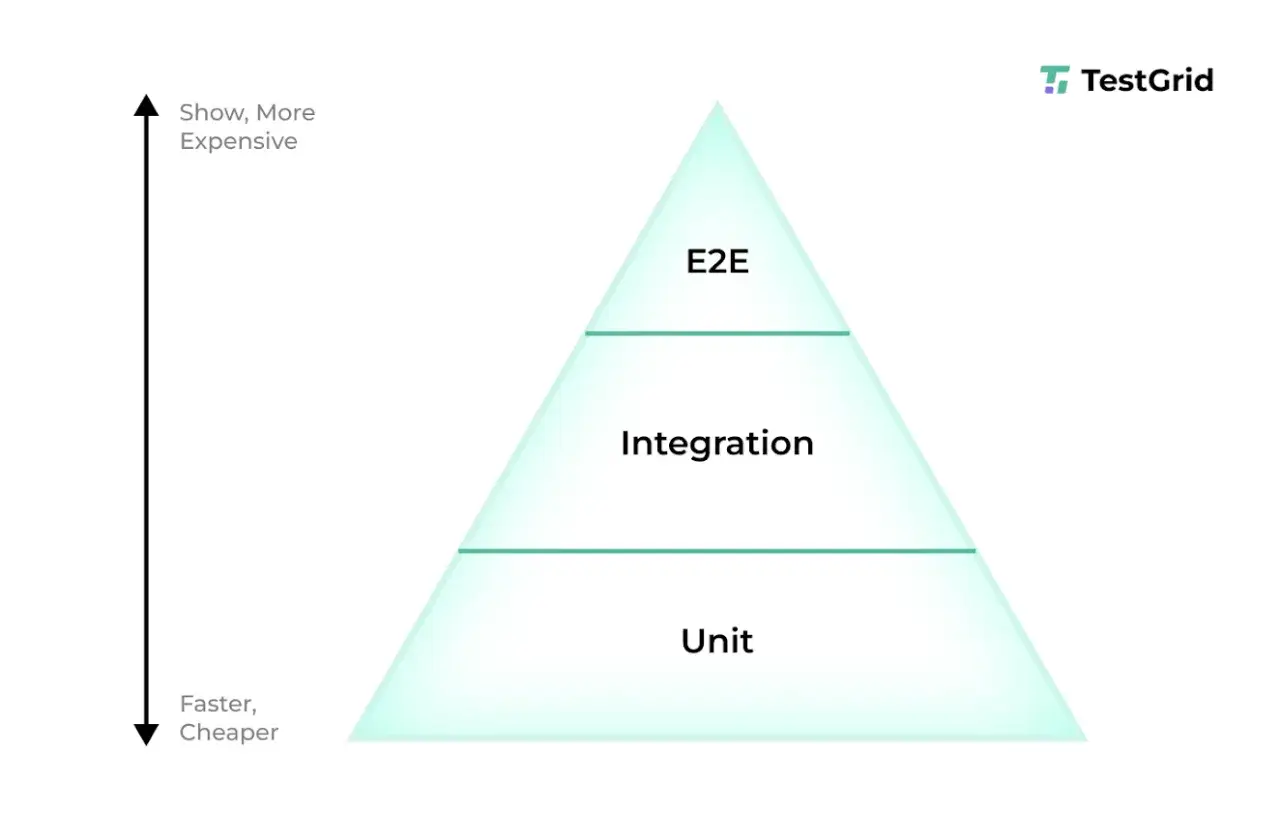
Jak układa się sensowna piramida testów
Piramida testów jest użyteczna wtedy, gdy traktuję ją jako narzędzie planowania, a nie ozdobną metaforę. Najwięcej powinno być testów szybkich i tanich w utrzymaniu, a najmniej tych najdroższych i najbardziej wrażliwych na zmiany UI.
| Poziom | Co weryfikuje | Dlaczego go potrzebuję | Czego nie oczekiwać |
|---|---|---|---|
| Unit tests | Pojedyncze funkcje, klasy i reguły logiki | Uruchamiają się szybko i najlepiej wskazują źródło problemu | Nie potwierdzą, że wszystkie moduły współpracują poprawnie |
| Integration tests | Współpracę kilku komponentów, baz danych, kolejek lub zewnętrznych usług | Łapią błędy na styku modułów, zanim trafią do użytkownika | Nie są tak tanie i proste jak testy jednostkowe |
| Contract tests | Uzgodniony format i zachowanie komunikacji między usługami | Chronią przed rozjechaniem się API w środowisku z wieloma zespołami | Nie zastępują pełnego scenariusza biznesowego |
| End-to-end | Najważniejsze ścieżki użytkownika od początku do końca | Dają wysoki poziom pewności, że produkt działa jako całość | Są wolne, kosztowne i wrażliwe na niestabilne elementy UI |
| Acceptance tests | Czy system spełnia kryteria akceptacji biznesowej | Pomagają domknąć temat z perspektywy klienta lub product ownera | Nie powinny być jedyną warstwą zabezpieczającą jakość |
W praktyce lubię trzymać zestaw smoke testów tak, by po wdrożeniu dało się szybko sprawdzić, czy aplikacja w ogóle wstała i obsługuje krytyczne ścieżki. Smoke test to krótki zestaw sprawdzeń „czy podstawy żyją”, a sanity test weryfikuje konkretną zmianę lub poprawkę w najbliższym otoczeniu problemu.
Gdy piramida jest zdrowa, testy są szybsze, stabilniejsze i łatwiejsze do utrzymania. Następny krok to sprawdzenie, czy nie brakuje warstwy, która często przesądza o sukcesie albo porażce produktu, czyli testów niefunkcjonalnych.Kiedy testy niefunkcjonalne decydują o sukcesie
W wielu projektach właśnie testy niefunkcjonalne decydują, czy produkt jest „działający”, czy naprawdę używalny. Wydajność, bezpieczeństwo, dostępność i kompatybilność nie są dodatkiem do funkcji. One bardzo często decydują o tym, czy użytkownik zostanie z produktem na dłużej.
| Obszar | Co sprawdzam | Gdzie ma największe znaczenie | Częsty błąd |
|---|---|---|---|
| Wydajność | Czas odpowiedzi, stabilność pod obciążeniem, percentyle zamiast samej średniej | Sklepy, systemy transakcyjne, panele operacyjne | Testowanie tylko „na pustym” środowisku |
| Bezpieczeństwo | Luki w autoryzacji, walidacji, zależnościach i konfiguracji | Finanse, e-commerce, systemy z danymi wrażliwymi | Ograniczanie się do skanera bez ręcznej weryfikacji krytycznych ścieżek |
| Użyteczność | Czy użytkownik rozumie interfejs, komunikaty i kolejność kroków | Aplikacje B2C, onboarding, produkty samoobsługowe | Testowanie tylko „czy da się kliknąć”, bez oceny kontekstu |
| Dostępność | Obsługa klawiatury, kontrast, czytniki ekranu, logiczną kolejność fokusu | Każdy produkt publiczny i każdy, który podlega wymaganiom dostępności | Sprawdzanie dostępności dopiero na końcu projektu |
| Kompatybilność | Różne przeglądarki, urządzenia, wersje API i konfiguracje środowiskowe | Produkty webowe, mobile i platformy integracyjne | Zakładanie, że „u mnie działa”, więc zadziała wszędzie |
Wydajności nie oceniam po jednym pomiarze. Patrzę na trend, obciążenie i scenariusze graniczne, bo dopiero one pokazują prawdziwy koszt wzrostu ruchu. Z kolei bezpieczeństwa nie zamykam w jednym skanie, bo najwięcej ryzyka zwykle siedzi w połączeniu kodu, konfiguracji i uprawnień.
Gdy te obszary są pod kontrolą, mogę dobrać metody testowe do typu projektu bez przepalania budżetu na niewłaściwe rzeczy.
Jak dobrać zestaw testów do typu projektu
W 2026 roku trudno sensownie mówić o testowaniu bez uwzględnienia tempa zmian, automatyzacji i coraz większego udziału kodu generowanego wspomaganiem AI. To nie zmienia podstawowej zasady: najpierw patrzę na ryzyko, dopiero potem na narzędzie. Inaczej testuję szybki MVP, inaczej system finansowy, a jeszcze inaczej rozproszoną platformę API.
| Typ projektu | Co daję pierwszeństwo | Czego nie rozdmuchuję | Dlaczego |
|---|---|---|---|
| MVP lub nowy produkt | Testy jednostkowe, kilka smoke testów, eksplorację i szybkie sprawdzenia krytycznych flow | Rozbudowanego zestawu end-to-end | Na starcie ważniejsze jest szybkie uczenie się niż ciężka infrastruktura testowa |
| SaaS z częstymi releasami | Automatyzację regresji, testy kontraktowe i stabilne środowisko CI | Nadmiaru ręcznych powtórzeń tych samych scenariuszy | Tu liczy się powtarzalność i szybka informacja zwrotna |
| System regulowany | Acceptance tests, ślad wymagań, testy bezpieczeństwa i audytowalność | Luźnych scenariuszy bez dowodu wykonania | Ważna jest nie tylko jakość, ale też możliwość jej wykazania |
| Legacy monolith | Charakterization tests, regresję wokół najbardziej ryzykownych obszarów i testy integracyjne | Pełnej przebudowy całego pakietu testów naraz | Najpierw trzeba zabezpieczyć to, co już działa, zanim zacznie się refaktor |
| Microservices lub platforma API | Testy kontraktowe, integracyjne i obserwowalność po wdrożeniu | Zbyt dużej liczby ciężkich E2E | Przy wielu usługach to właśnie granice między komponentami psują się najczęściej |
Jeśli w zespole rośnie udział kodu generowanego przez narzędzia AI, dokładam więcej kontroli na styku modułów. Taki kod często wygląda poprawnie, ale rozjeżdża się w detalach integracyjnych albo w edge case’ach, które wyłapuje dopiero dobrze dobrana warstwa testów.
Na tym etapie najczęstszy błąd nie dotyczy już techniki, tylko organizacji pracy. I właśnie to pokazuję w ostatniej części.
Najczęstsze błędy, które obniżają jakość mimo testów
W praktyce nie przegrywa się zwykle z brakiem testów, tylko z ich złym rozłożeniem albo zbyt optymistycznym założeniem, że „to się samo obroni”. Poniżej są błędy, które widzę najczęściej:
- Automatyzowanie niestabilnego UI za wcześnie - jeśli interfejs często się zmienia, utrzymanie testów zjada więcej czasu niż daje korzyści.
- Budowanie wyłącznie ciężkich E2E - daje poczucie bezpieczeństwa, ale spowalnia pipeline i utrudnia diagnozę błędów.
- Brak danych testowych i resetowalnego środowiska - bez tego nawet dobry test zaczyna losowo failować.
- Ignorowanie flaky tests - niestabilny test przestaje być sygnałem jakości i staje się szumem, którego nikt nie ufa.
- Ocenianie jakości po samym coverage - pokrycie kodu nie mówi jeszcze, czy testy sprawdzają najważniejsze ryzyka biznesowe.
- Oddzielenie QA od zespołu produktowego - jakość rośnie szybciej, gdy każdy członek zespołu czuje się za nią współodpowiedzialny.
- Brak monitoringu po wdrożeniu - część błędów ujawnia się dopiero w realnym ruchu, więc bez obserwacji produkcji nie widać pełnego obrazu.
Jeśli miałbym wskazać jedną zasadę, która porządkuje cały proces, powiedziałbym tak: testuj tam, gdzie ryzyko jest największe, automatyzuj to, co powtarzalne, i nie traktuj wdrożenia jako końca pracy nad jakością.
Co naprawdę podnosi jakość produktu w długim terminie
Gdy patrzę na zespoły, które naprawdę poprawiają jakość z kwartału na kwartał, widzę zwykle trzy rzeczy: mocne review wymagań i kodu, zdrową piramidę testów oraz obserwowalność po wdrożeniu. To właśnie ten zestaw daje większą pewność niż sama rozbudowa liczby przypadków testowych.
W praktyce zaczynam od obszarów, które są biznesowo najdroższe: płatności, logowania, rejestracji, importu danych albo modułów, które zmieniają się najczęściej. Tam inwestycja w testy zwraca się najszybciej, bo ogranicza regresje i przyspiesza kolejne releasy.
Jeśli czas jest ograniczony, lepiej mieć mniej testów, ale dobrze utrzymanych i rzeczywiście używanych, niż rozbudowany zestaw, którego nikt nie ufa. To właśnie taka dyscyplina buduje trwałą jakość, a nie samo mnożenie sprawdzeń dla spokoju sumienia.