Dobry proces wytwórczy oprogramowania decyduje nie tylko o tym, czy produkt działa, ale też jak szybko zespół wyłapuje błędy, jak przewidywalne są wydania i ile kosztuje poprawianie problemów po wdrożeniu. W praktyce to połączenie metod pracy, etapów SDLC i dobrze ustawionego QA, a nie sama kolejność pisania kodu. W tym tekście pokazuję, jak ten model działa w realnych zespołach, gdzie QA powinno wchodzić do gry i które błędy najczęściej psują cały łańcuch.
Najważniejsze elementy dobrze ustawionego procesu
- Proces jest ciągiem decyzji, a nie tylko listą faz od pomysłu do wdrożenia.
- Największą różnicę robi wczesne doprecyzowanie wymagań i kryteriów akceptacji.
- QA powinno działać od początku, a nie dopiero po zakończeniu kodowania.
- Wybór modelu pracy wpływa na to, gdzie i kiedy testy mają sens.
- Najlepsze efekty daje połączenie automatyzacji, testów eksploracyjnych i stabilnych środowisk.
Jak rozumieć ten proces bez korporacyjnej mgły
W najprostszej wersji chodzi o to, aby zespół potrafił przejść od potrzeby biznesowej do działającego produktu bez chaosu, opóźnień i nadmiarowych poprawek. Proces wytwarzania oprogramowania obejmuje więc planowanie, projektowanie, implementację, testowanie, wdrożenie i utrzymanie, ale w dobrych zespołach te etapy nie są zamkniętymi pudełkami. Przecinają się ze sobą, a QA działa jak filtr i system wczesnego ostrzegania.
To ważne, bo wiele osób nadal traktuje jakość jak ostatnią bramkę przed produkcją. Ja patrzę na to odwrotnie: im wcześniej pojawiają się pytania o ryzyka, dane testowe, kryteria akceptacji i scenariusze brzegowe, tym mniej kosztowne są późniejsze poprawki. Właśnie dlatego dobrze ustawiony proces jest bardziej opłacalny niż szybkie „klepanie” funkcji i gaszenie pożarów na końcu.
Ten sposób myślenia prowadzi wprost do etapów, które rzeczywiście składają się na cały cykl pracy nad produktem.
Etapy, które muszą się spinać od wymagań do utrzymania
W praktyce każda faza wnosi coś innego, ale też generuje inne ryzyko. Poniżej porządkuję to tak, jak zwykle widzę to w zespołach produktowych i projektowych.
| Etap | Co się dzieje | Co powinno robić QA | Typowe ryzyko |
|---|---|---|---|
| Wymagania | Ustalenie celu, zakresu, ograniczeń i kryteriów sukcesu | Doprecyzowanie niejasności, zapisanie kryteriów akceptacji, identyfikacja braków | Niepełne wymagania i sporne interpretacje |
| Projekt | Dobór architektury, przepływów, integracji i zależności | Wskazanie punktów krytycznych, zależności i scenariuszy ryzyka | Zła struktura systemu, która utrudni testowanie i rozwój |
| Implementacja | Powstaje kod, integracje i konfiguracje | Testy jednostkowe, code review, testy statyczne, weryfikacja zmian | Błędy logiki, regresje, brak spójności między modułami |
| Testowanie | Sprawdzanie funkcji, integracji, wydajności i zgodności z wymaganiami | Testy funkcjonalne, regresja, UAT, testy eksploracyjne | Odkrycie problemów zbyt późno lub zbyt pobieżne pokrycie |
| Wdrożenie | Publikacja wersji na środowisko produkcyjne | Smoke testy, checklista release, obserwacja logów i metryk | Awaria przy przełączeniu, brak gotowości infrastruktury |
| Utrzymanie | Poprawki, rozwój, monitoring, reakcja na incydenty | Analiza defektów, testy regresyjne, weryfikacja poprawek | Nawracające błędy i dług techniczny |
Najważniejszy wniosek jest prosty: jakość nie pojawia się w dniu testów, tylko wcześniej, w sposobie opisu pracy i projektowania zmian. Według Atlassian właśnie połączenie planowania, implementacji, testowania i utrzymania tworzy sensowny model SDLC, ale w praktyce to QA decyduje, czy ten model działa płynnie, czy zamienia się w serię ręcznych przepychanek. To prowadzi do pytania, gdzie dokładnie QA powinno się pojawiać.
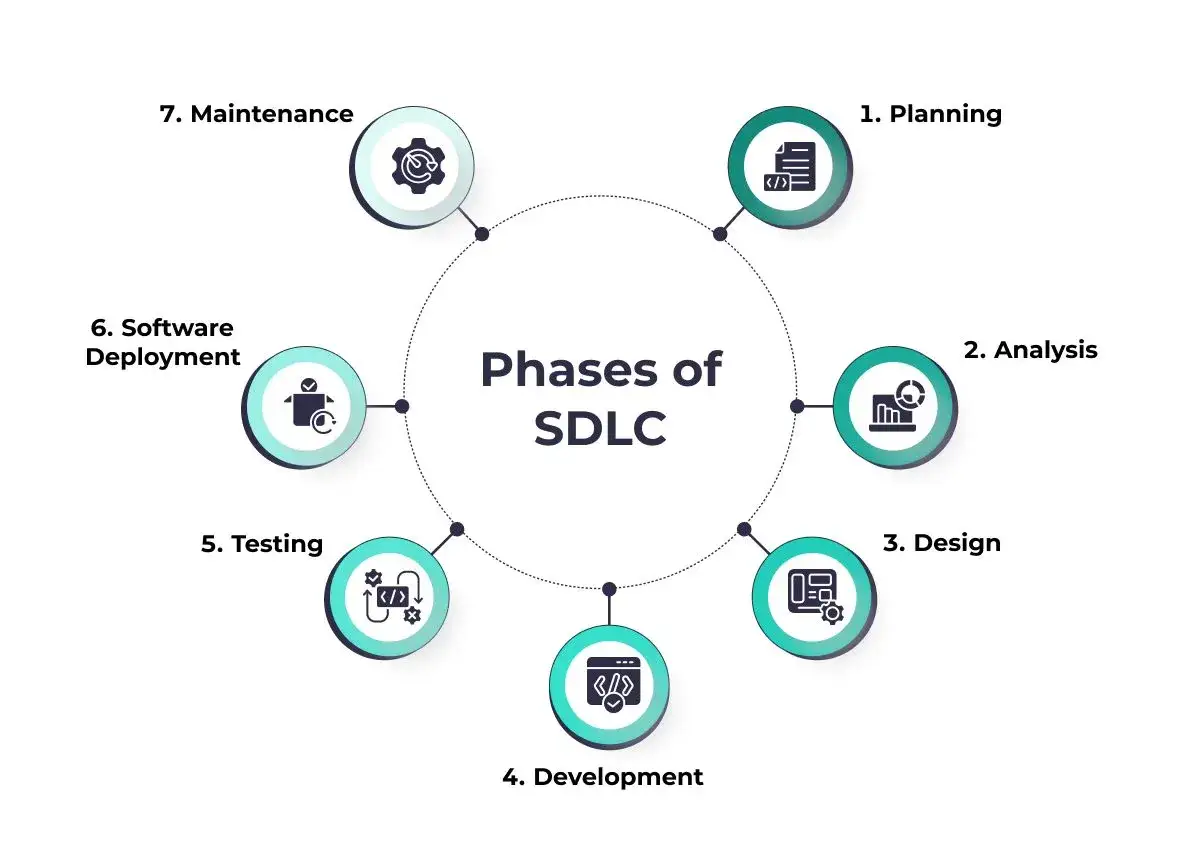
Gdzie QA naprawdę zmienia wynik całego procesu
Największy błąd, jaki widzę, to utożsamianie QA wyłącznie z testowaniem końcowym. Tymczasem zapewnienie jakości obejmuje dużo więcej: przegląd wymagań, ocenę ryzyk, przygotowanie scenariuszy, automatyzację, kontrolę środowisk i analizę defektów. Sama identyfikacja bugów jest tylko końcówką tego łańcucha.Jeśli mam wskazać trzy miejsca, w których QA daje największy zwrot, to są to: doprecyzowanie wymagań przed startem prac, szybka weryfikacja zmian podczas implementacji oraz testy regresyjne przed wydaniem. To jest klasyczne podejście „testuj wcześniej i częściej”, ale bez marketingowego nadęcia. Chodzi po prostu o to, by błędy wykrywać wtedy, gdy ich naprawa jest najtańsza.
W nowoczesnych zespołach dobrze działa też rozdzielenie ról: testy statyczne i code review pilnują jakości kodu, testy jednostkowe łapią błędy w logice, integracyjne sprawdzają przepływy między modułami, a eksploracyjne testy QA znajdują problemy, których nie da się sensownie opisać z góry. AWS zwraca uwagę, że testowanie nie musi czekać na koniec implementacji, bo w praktyce warto uruchamiać je na każdym etapie zmian. I to jest zdrowe podejście, szczególnie wtedy, gdy zespół pracuje w CI/CD.Warto też rozróżnić QA i testowanie. Testowanie odpowiada na pytanie „czy to działa”, a QA na pytanie „czy cały sposób pracy daje szansę, że to będzie działało po wydaniu”. To różnica subtelna, ale w projekcie bardzo kosztowna, jeśli ktoś jej nie widzi. Następny krok to wybór modelu pracy, bo od niego zależy, jak ten zestaw praktyk w ogóle da się wdrożyć.
Który model pracy wybrać do swojego zespołu
Nie ma jednego modelu, który pasuje do wszystkiego. Z mojego doświadczenia wybór metodologii powinien wynikać z tego, jak często zmieniają się wymagania, jak duże są ryzyka i jak mocno zespół potrzebuje kontroli nad wersjami.
| Model | Najlepiej sprawdza się gdy | Jak wygląda QA | Mocna strona | Ograniczenie |
|---|---|---|---|---|
| Waterfall | Wymagania są stabilne, a zakres dobrze znany | Testy pojawiają się później, zwykle po zakończeniu dużej części implementacji | Łatwo go opisać i kontrolować | Słabo znosi zmiany i późne odkrywanie błędów |
| Agile | Produkt rozwija się iteracyjnie i często dostaje feedback | QA pracuje równolegle z developmentem, a testy są częścią sprintu | Szybka reakcja na zmianę i lepsze dopasowanie do rynku | Wymaga dyscypliny i jasnych kryteriów gotowości |
| V-model | Ważna jest ścisła relacja między etapem budowy i weryfikacji | Każdej fazie prac odpowiada plan testów | Wysoka przewidywalność i dobra kontrola jakości | Mniej wygodny przy częstych zmianach zakresu |
| DevOps | Zespół chce częstych, bezpiecznych wdrożeń | Testy, integracja i deployment są zautomatyzowane możliwie szeroko | Szybsze wydania i krótszy czas reakcji | Wymaga dojrzałej automatyzacji i dobrego ownershipu |
Jak zbudować QA, który wyłapuje błędy przed wydaniem
Najlepsze procesy QA nie są rozbudowane na pokaz. Są przewidywalne, lekkie tam, gdzie się da, i twarde tam, gdzie musi być kontrola. Ja zwykle zaczynam od sześciu elementów, bo one robią największą różnicę.
- Ustalona definicja gotowości i definicja ukończenia, czyli jasne warunki startu i zamknięcia pracy.
- Kryteria akceptacji zapisane językiem biznesowym, ale możliwe do przetestowania.
- Warstwa testów jednostkowych i integracyjnych wpięta w pipeline CI.
- Stałe środowisko testowe z danymi, które nie zmieniają się chaotycznie między sprintami.
- Testy regresyjne uruchamiane przed wydaniem, a nie „jak starczy czasu”.
- Monitoring po wdrożeniu, żeby błędy produkcyjne nie ginęły w ciszy.
W praktyce największy zwrot daje automatyzacja tych testów, które są powtarzalne, stabilne i krytyczne dla biznesu. Nie automatyzowałbym wszystkiego bez selekcji, bo to szybko prowadzi do kruchego zestawu testów i fałszywego poczucia bezpieczeństwa. Lepiej mieć mniej testów, ale takich, które rzeczywiście dają sygnał, niż rozbudowaną kolekcję skryptów, których nikt nie ufa.
Ważny jest też podział odpowiedzialności. QA nie powinno być samotną wyspą, która „odbiera” gotowy kod. Dobry układ to współodpowiedzialność: developer pisze testy i myśli o błędach, QA projektuje scenariusze i szuka luk, a produkt pilnuje sensu biznesowego wymagań. Dzięki temu testowanie nie jest końcówką procesu, tylko jego normalną częścią. Kiedy to działa, błędy przestają zaskakiwać, a gdy nie działa, zwykle wracają te same, przewidywalne problemy.
To dobry moment, by nazwać rzeczy, które najczęściej psują nawet poprawnie zaprojektowany proces.
Najczęstsze błędy, które rozwalają nawet dobry plan
Najwięcej strat widzę tam, gdzie zespół formalnie ma proces, ale praktycznie omija kilka kluczowych zasad. Oto problemy, które pojawiają się najczęściej:
- Testowanie dopiero na końcu, gdy poprawki są już drogie i wpływają na całą wersję.
- Niejasne wymagania, przez które każdy rozumie „gotowe” inaczej.
- Zbyt duża wiara w automatyzację bez sensownej strategii testów.
- Brak stabilnych środowisk i danych testowych, co psuje powtarzalność wyników.
- Ignorowanie regresji, czyli sprawdzanie nowej funkcji bez oceny wpływu na stare obszary.
- Brak monitoringu po wdrożeniu, przez co zespół dowiaduje się o problemach od użytkowników.
Najgorszy z tych błędów to zwykle pierwszy, bo uruchamia lawinę kolejnych. Jeśli testowanie startuje zbyt późno, QA nie ma już wpływu na projekt, a może tylko opisać szkody. Gdy natomiast jakość jest wbudowana od początku, zespół szybciej wykrywa luki i dużo spokojniej dowozi kolejne wydania.
Drugie miejsce na mojej liście zajmuje brak wspólnego języka wokół kryteriów akceptacji. To brzmi jak drobiazg, ale właśnie na tym etapie powstaje większość nieporozumień między biznesem, developmentem i QA. I tutaj dochodzimy do praktycznej części: co wdrożyłbym najpierw, gdybym miał uporządkować taki proces od zera.
Co wdrożyłbym najpierw, gdybym porządkował ten proces od zera
Jeśli zespół startuje z chaosem albo chce po prostu poprawić jakość bez rewolucji, nie zaczynam od wielkiego narzędzia. Zaczynam od kilku zasad, które dają efekt już po pierwszych iteracjach.- Spisz jasne kryteria akceptacji dla każdej ważniejszej funkcji.
- Wprowadź krótką checklistę przed mergem i przed release’em.
- Uruchom smoke test po wdrożeniu, nawet jeśli jest bardzo prosty.
- Oddziel testy szybkie od ciężkich, żeby pipeline nie stał się zbyt wolny.
- Zbieraj defekty według przyczyny, a nie tylko objawu, bo to pokazuje, gdzie proces się łamie.
Jeżeli mam wskazać jeden priorytet, to jest nim wcześniejsze łapanie niejasności. To daje największą oszczędność czasu, bo każdy kolejny etap pracuje wtedy na lepszym materiale wejściowym. Drugi priorytet to regresja wbudowana w codzienny rytm pracy, a nie odpalana „na wszelki wypadek” przed dużym wydaniem.
Dobrze ustawiony proces wytwarzania oprogramowania nie jest spektakularny. Jest przewidywalny, powtarzalny i odporny na drobne zmiany, które w innych zespołach zamieniają się w kryzys. I właśnie dlatego to podejście działa: nie obiecuje cudów, tylko systematycznie zmniejsza liczbę błędów, koszt poprawek i stres przy wdrożeniach.