
Mechanizm fixture’ów w pytest porządkuje testy tam, gdzie ręczne przygotowywanie danych, połączeń i zależności zaczyna spowalniać pracę. W praktyce pytest fixtures pozwalają oddzielić przygotowanie środowiska od samego asercyjnego rdzenia testu, dzięki czemu suite jest krótszy, czytelniejszy i łatwiejszy do utrzymania. Poniżej pokazuję, jak to działa, kiedy używać poszczególnych zakresów, jak ograć sprzątanie po teście i gdzie najczęściej pojawiają się błędy.
Najważniejsze zasady pracy z fixture’ami w pytest
- Fixture dostarcza testowi gotowy kontekst: dane, obiekt, połączenie lub stan potrzebny do wykonania scenariusza.
- Test nie importuje fixture’a bezpośrednio, tylko pobiera go przez parametr funkcji testowej.
- Zakresy `function`, `class`, `module`, `package` i `session` decydują o tym, jak długo żyje przygotowany zasób.
- `yield` służy do sprzątania po teście, a kod po nim wykona się nawet wtedy, gdy test się wywróci.
- `conftest.py`, `autouse` i parametryzacja są bardzo mocne, ale łatwo nimi ukryć zależności, jeśli używa się ich bez dyscypliny.
- Najlepszy efekt daje zestaw małych, nazwanych fixture’ów zamiast jednego dużego bloku „setupu do wszystkiego”.
Czym są fixture’y i dlaczego porządkują testy
Fixture to po prostu z góry przygotowany fragment środowiska testowego. Może tworzyć obiekt, otwierać połączenie z bazą, ustawiać dane wejściowe, podmieniać konfigurację albo przygotowywać katalog tymczasowy. Najważniejsze jest jednak to, że fixture nie jest „magicznie” uruchamiany wszędzie. W pytest działa jawnie: test deklaruje, czego potrzebuje, a framework sam rozwiązuje zależności.
To znacząco różni się od klasycznego podejścia xUnit, gdzie setup bywa rozlany po metodach życia klasy testowej. W pytest łatwiej utrzymać przejrzystość, bo każdy test pokazuje swój kontekst wprost w sygnaturze. Ja zwykle traktuję to jako najcenniejszą cechę tego mechanizmu: czytelność rośnie razem z liczbą testów, zamiast spadać.
W automatyzacji testów liczy się też powtarzalność. Jeśli fixture przygotowuje ten sam stan wejściowy za każdym razem, testy stają się stabilniejsze i mniej zależą od przypadków. To właśnie dlatego fixture’y są tak przydatne zarówno w unit testach, jak i w testach integracyjnych. Następny krok to zrozumienie, jak pytest te zależności faktycznie układa w kolejności wykonania.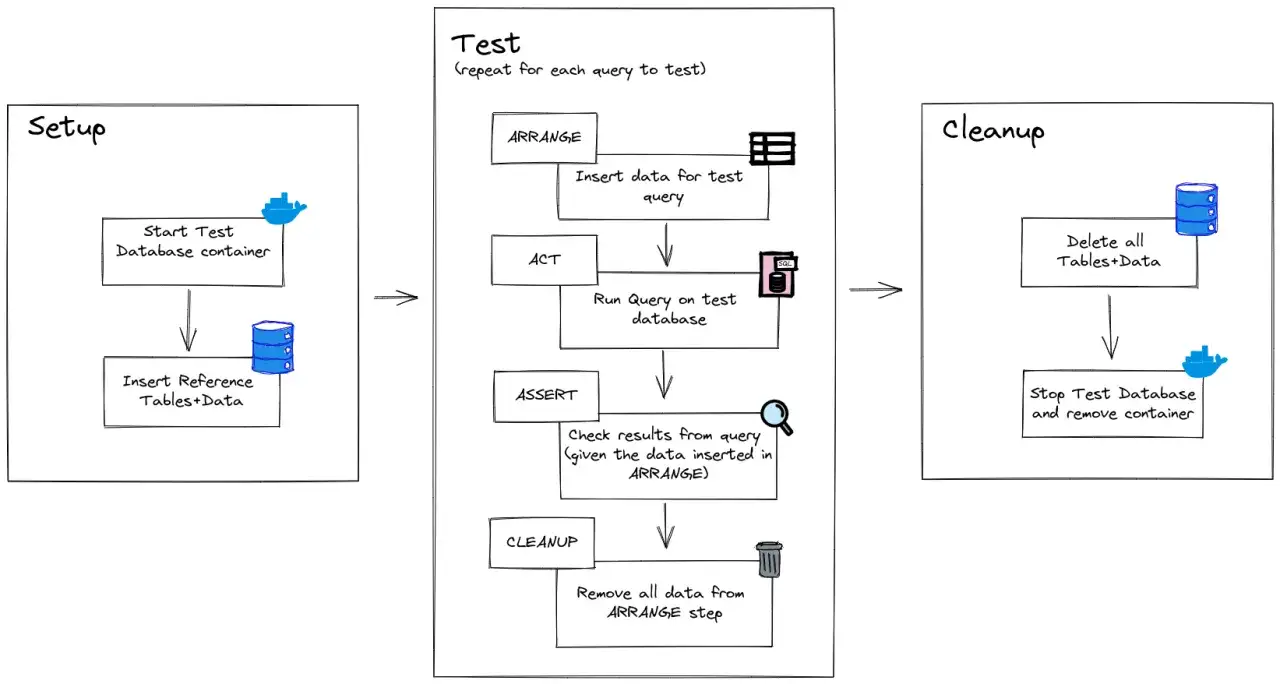
Jak działa mechanizm krok po kroku
W praktyce pytest analizuje sygnaturę testu, sprawdza, jakie fixture’y są potrzebne, a potem buduje ich kolejność. Jeśli fixture A potrzebuje fixture B, to B zostanie uruchomiony wcześniej. Tę zależność można zbudować również wielowarstwowo, co daje modularność bez kopiowania kodu.
import pytest
@pytest.fixture
def db_connection():
conn = create_connection()
yield conn
conn.close()
@pytest.fixture
def prepared_user(db_connection):
user = db_connection.create_user(name="Ala")
return user
def test_user_is_created(prepared_user):
assert prepared_user.name == "Ala"W tym przykładzie test nie interesuje się tym, jak powstaje połączenie ani użytkownik. Dostaje gotowy obiekt i sprawdza tylko efekt biznesowy. To dobry wzorzec, bo test zostaje krótki, a logika przygotowania środowiska może się zmieniać bez przepisywania wielu scenariuszy.
Warto też pamiętać o teardownie. Jeśli fixture używa `yield`, kod zapisany po nim działa jako sprzątanie po teście. Co ważne, wykona się ono niezależnie od wyniku testu, więc nie zostawiasz otwartych zasobów, plików ani połączeń. To właśnie ten mechanizm sprawia, że fixture’y dobrze nadają się do automatyzacji testów, gdzie stabilność środowiska ma realne znaczenie.
Zakres decyduje, jak długo żyje przygotowany stan
Jedna z najważniejszych decyzji przy projektowaniu fixture’a to jego zakres. Pytest oferuje pięć standardowych poziomów współdzielenia: `function`, `class`, `module`, `package` i `session`. Im szerszy zakres, tym rzadziej fixture jest budowany od nowa, ale tym większe ryzyko, że stan „przecieknie” między testami.
| Zakres | Jak długo działa | Kiedy ma sens | Na co uważać |
|---|---|---|---|
function |
Na jeden test | Najbezpieczniejszy wybór dla większości przypadków | Największy koszt przygotowania, jeśli zasób jest ciężki |
class |
Na klasę testową | Gdy kilka metod testuje ten sam kontekst | Łatwo ukryć zależność od stanu współdzielonego |
module |
Na plik z testami | Gdy zestaw scenariuszy korzysta z jednego przygotowania | Testy w module mogą zacząć wpływać na siebie pośrednio |
package |
Na pakiet testów | Przy większych, logicznie spójnych grupach testów | Wymaga większej dyscypliny organizacyjnej |
session |
Na całą sesję testową | Tylko gdy przygotowanie jest kosztowne i bezpieczne do współdzielenia | Największe ryzyko ukrytego stanu i trudniejszych awarii |
Jeśli mam wskazać praktyczną zasadę, to jest ona prosta: zaczynaj od `function` i podnoś zakres tylko wtedy, gdy naprawdę widzisz korzyść. Wiele problemów z testami bierze się właśnie z nadmiernie szerokiego współdzielenia danych. Gdy ta część jest opanowana, warto zobaczyć, jak pytest udostępnia fixture’y całemu drzewu testów i jak sprzątać po nich bez nieczytelnego kodu.
`conftest.py`, `autouse` i sprzątanie po teście
`conftest.py` to naturalne miejsce na fixture’y, które mają być widoczne dla wielu testów w danym katalogu i jego podkatalogach. Dzięki temu nie trzeba ich importować w każdym pliku testowym. W większych projektach to duża oszczędność, ale też punkt, w którym łatwo przesadzić z ukrywaniem logiki.
# conftest.py
import pytest
@pytest.fixture
def api_client():
return ApiClient(base_url="https://example.test")
@pytest.fixture
def transactional_db(db):
db.begin()
yield db
db.rollback()W tym układzie `transactional_db` pokazuje klasyczny wzorzec: przygotuj stan, uruchom test, potem wycofaj zmiany. To jest szczególnie użyteczne przy testach integracyjnych, bo minimalizuje ryzyko pozostawiania śmieci w bazie albo w plikach tymczasowych.
Na osobną uwagę zasługuje `autouse=True`. Taki fixture uruchamia się automatycznie w swoim zakresie, bez wpisywania go w sygnaturze testu. Brzmi wygodnie, ale używam go ostrożnie. Jeśli coś dzieje się „samo”, czytelność suite’u spada, a nowa osoba w zespole ma trudniej z odczytaniem, skąd w ogóle bierze się dany stan. Do zadań pobocznych, które nie zwracają wartości testowi, czasem lepsze jest jawne `usefixtures`, bo przynajmniej widać intencję.
Najlepsza praktyka jest więc dość konserwatywna: fixture’y współdzielone trzymaj w `conftest.py`, `autouse` stosuj rzadko, a teardown zawsze zapisuj wprost. Dzięki temu automatyzacja testów pozostaje przewidywalna. Gdy to działa, możesz bezpiecznie przejść do parametryzacji i zwiększania pokrycia bez kopiowania przypadków.Parametryzacja fixture’ów daje więcej testów bez duplikacji
Jedną z mocniejszych stron pytest jest to, że fixture może być parametryzowany. W praktyce oznacza to, że ten sam test uruchomi się kilka razy dla różnych danych albo środowisk. To bardzo dobry sposób na sprawdzenie wariantów bez przepisywania identycznego kodu.
import pytest
@pytest.fixture(params=["chrome", "firefox"])
def browser_name(request):
return request.param
def test_login_page_renders(browser_name):
assert browser_name in {"chrome", "firefox"}To oczywiście prosty przykład, ale dobrze pokazuje ideę. Jeden test, dwa warianty. W prawdziwym projekcie zamiast nazw przeglądarek możesz podmienić endpoint, rolę użytkownika, format danych albo sposób autoryzacji. Ważne jest jednak to, że liczba uruchomień rośnie szybko, zwłaszcza gdy łączysz parametryzację fixture’a z `@pytest.mark.parametrize` na samym teście. Zysk z pokrycia jest realny, ale koszt wykonania też rośnie.
W bardziej złożonych przypadkach przydaje się też obiekt `request`, zwłaszcza przez `request.param`. To techniczny szczegół, który pozwala dynamicznie dostosować fixture do aktualnego wariantu. Ja traktuję to jako sygnał, że fixture zaczyna pełnić rolę małej fabryki środowisk testowych, a nie tylko prostego helpera. Wtedy szczególnie ważne staje się unikanie najczęstszych błędów, bo właśnie na tym etapie projekty testowe najłatwiej się rozjeżdżają.
Najczęstsze błędy, które psują czytelność i stabilność testów
- Zbyt dużo logiki w jednym fixture’ze - jeśli przygotowujesz bazę, autoryzację, dane i pliki w jednym miejscu, potem trudno ustalić, co dokładnie się zepsuło.
- Nadmierne używanie `autouse` - wygodne na krótką metę, ale szybko ukrywa zależności i utrudnia debugowanie.
- Za szeroki zakres - `session` i `module` są kuszące, ale współdzielony stan potrafi produkować trudne, losowe błędy.
- Mieszanie danych i asercji - fixture powinien przygotować kontekst, a nie wykonywać część logiki, którą potem testujesz.
- Brak jawnych nazw - `data`, `obj` czy `setup` nic nie mówią; lepsza nazwa często oszczędza godzinę analiz w przyszłości.
- Brak teardownu - jeśli fixture tworzy zasób, ale go nie zamyka, suite może działać dobrze tylko „na szczęście”.
To nie są błędy teoretyczne. W projektach, które rosną przez kilka miesięcy, właśnie one najczęściej robią różnicę między zestawem testów, który wspiera development, a takim, który trzeba ciągle naprawiać. Dlatego na koniec zbieram kilka zasad, które sam uznałbym za rozsądny punkt startowy w nowym repozytorium.
Co wdrożyć od razu w swoim projekcie
Jeśli budujesz albo porządkujesz testy, zacznij od małych, jednozadaniowych fixture’ów. Jeden odpowiada za bazę, drugi za klienta API, trzeci za dane przykładowe. Taka modularność ułatwia debugowanie i pozwala przenosić fragmenty między plikami bez kopiowania całych bloków setupu.
Potem przenieś współdzielone elementy do `conftest.py`, ale tylko te, które rzeczywiście są wspólne. Nie wszystko powinno być globalne. W praktyce najlepszy efekt daje prosty zestaw zasad: jawna nazwa, najmniejszy możliwy zakres, teardown po `yield`, brak ukrytych efektów ubocznych.
Jeśli projekt testowy zacznie się rozrastać, wróć do dwóch pytań: czy fixture nadal ma jedną odpowiedzialność i czy jego zakres jest naprawdę uzasadniony. To właśnie te dwa filtry najczęściej utrzymują suite w dobrej kondycji. W dobrze zorganizowanym projekcie fixture’y nie są ozdobą frameworka, tylko jednym z głównych narzędzi do budowania stabilnej automatyzacji.