Dobrze zaprojektowany komunikat błędu nie tylko informuje, że coś poszło nie tak, ale też skraca czas diagnozy, zmniejsza liczbę zgłoszeń do supportu i pomaga zespołowi szybciej zamknąć defekt. W tym tekście pokazuję, jak oceniam treść takich komunikatów, co sprawdzam w testach i jak włączam je do sensownego procesu zarządzania testami, żeby nie były przypadkowym dodatkiem do interfejsu.
Najważniejsze zasady, które od razu porządkują temat
- Dobry tekst błędu mówi, co się stało, jaki jest skutek i co użytkownik może zrobić dalej.
- W testach warto sprawdzać nie tylko treść, ale też stan interfejsu, dostępność i logowanie problemu.
- Jeden ogólny, pusty komunikat zwykle wydłuża triage i utrudnia odróżnienie awarii od błędu danych wejściowych.
- W praktyce najlepiej działa osobne podejście do walidacji, awarii sieci, braku uprawnień i błędów serwera.
- W zgłoszeniu testowym trzeba zapisać scenariusz, dane, oczekiwany rezultat i kontekst techniczny.
- Nie każdy błąd powinien być opisany bardzo szczegółowo, bo w obszarach bezpieczeństwa i autoryzacji prostszy komunikat bywa lepszy.
Co taki komunikat ma naprawdę robić
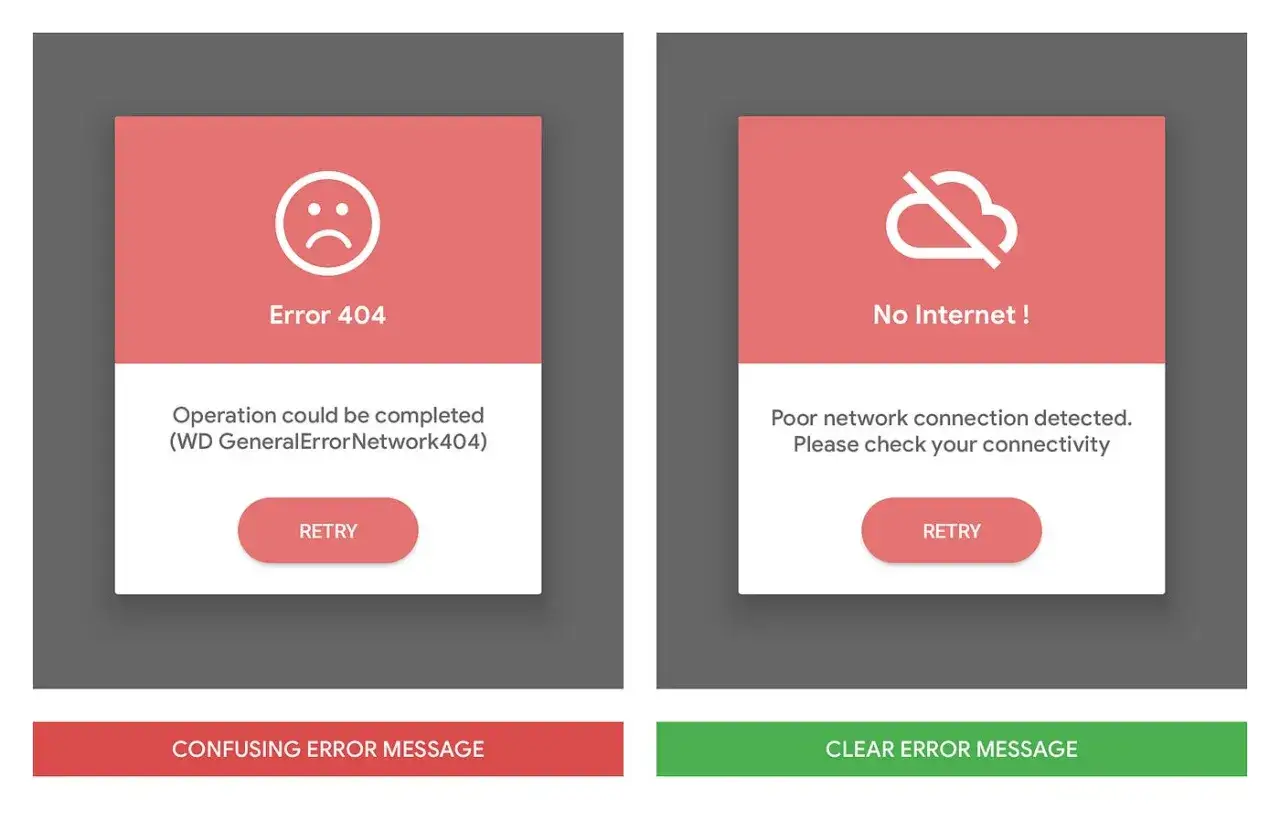
W praktyce nie traktuję go jako ozdobnego napisu na czerwonym tle. To mała, ale bardzo ważna część systemu, która powinna odpowiedzieć na trzy pytania: co się stało, co to oznacza dla użytkownika i co można zrobić dalej. Jeśli tekst odpowiada tylko na pierwsze pytanie, zwykle jest zbyt słaby, żeby realnie pomagać.
Wytyczne Microsoft są tu wyjątkowo użyteczne: dobry tekst ma opisywać problem jasno, bez żargonu, i podawać rozwiązanie albo następny krok. W testach zwracam uwagę, czy komunikat nie przerzuca odpowiedzialności na użytkownika, nie używa technicznych skrótów i nie zostawia go w martwym punkcie. To samo dotyczy tytułu, przycisków i kolejności elementów w oknie albo na stronie.
Warto też odróżnić trzy poziomy informacji. Pierwszy to treść widoczna dla użytkownika. Drugi to szczegóły diagnostyczne dla zespołu, na przykład kod zdarzenia lub identyfikator błędu. Trzeci to dane w logach i monitoringu. Jeśli te warstwy są pomieszane, tekst staje się albo zbyt ogólny, albo zbyt techniczny. Od tego właśnie zaczyna się sensowna kontrola jakości takich elementów.
Jeśli ten podział jest jasny, łatwiej przejść do pytania, dlaczego w ogóle trzeba temu poświęcać osobny obszar testów.
Dlaczego w testach to osobny obszar jakości
W zarządzaniu testami najbardziej kosztowne są nie same błędy, ale błędna interpretacja błędów. Gdy użytkownik widzi ogólny alert typu „Coś poszło nie tak”, tester też ma mniej informacji. W efekcie trudniej ustalić, czy problem wynika z walidacji, API, sesji, uprawnień czy awarii po stronie serwera. To wydłuża triage i zwiększa liczbę ping-pongów między QA, developmentem i supportem.
Ja patrzę na taki tekst jak na element, który wpływa na cały przepływ testowy. Jeżeli komunikat jest nieprecyzyjny, to:
- zgłoszenie defektu bywa niejednoznaczne,
- regresja nie ma stabilnego punktu odniesienia,
- support dostaje więcej zgłoszeń od użytkowników,
- zespół trudniej odróżnia błąd danych od błędu logiki.
W publicznych design systemach, między innymi w CMS i Canva, powraca ten sam kierunek: krótko, konkretnie, bez obwiniania użytkownika i bez zbędnej technicznej dekoracji. To dobry sygnał, bo pokazuje, że nie chodzi o „ładny tekst”, tylko o użyteczność, dostępność i spójność całego produktu. Mając to na uwadze, można już przejść do tego, jak taki tekst powinien wyglądać w różnych scenariuszach.
Jak powinna wyglądać treść w różnych typach błędów
Nie ma jednego szablonu, który sprawdzi się zawsze. Inaczej opisuję walidację formularza, inaczej przerwany transfer danych, a jeszcze inaczej brak uprawnień albo pusty stan po stronie backendu. W testach lubię rozbijać to na kilka typowych scenariuszy, bo wtedy szybciej widać, czy produkt reaguje adekwatnie do sytuacji.
| Sytuacja | Co powinno być jasne dla użytkownika | Typowy błąd w treści |
|---|---|---|
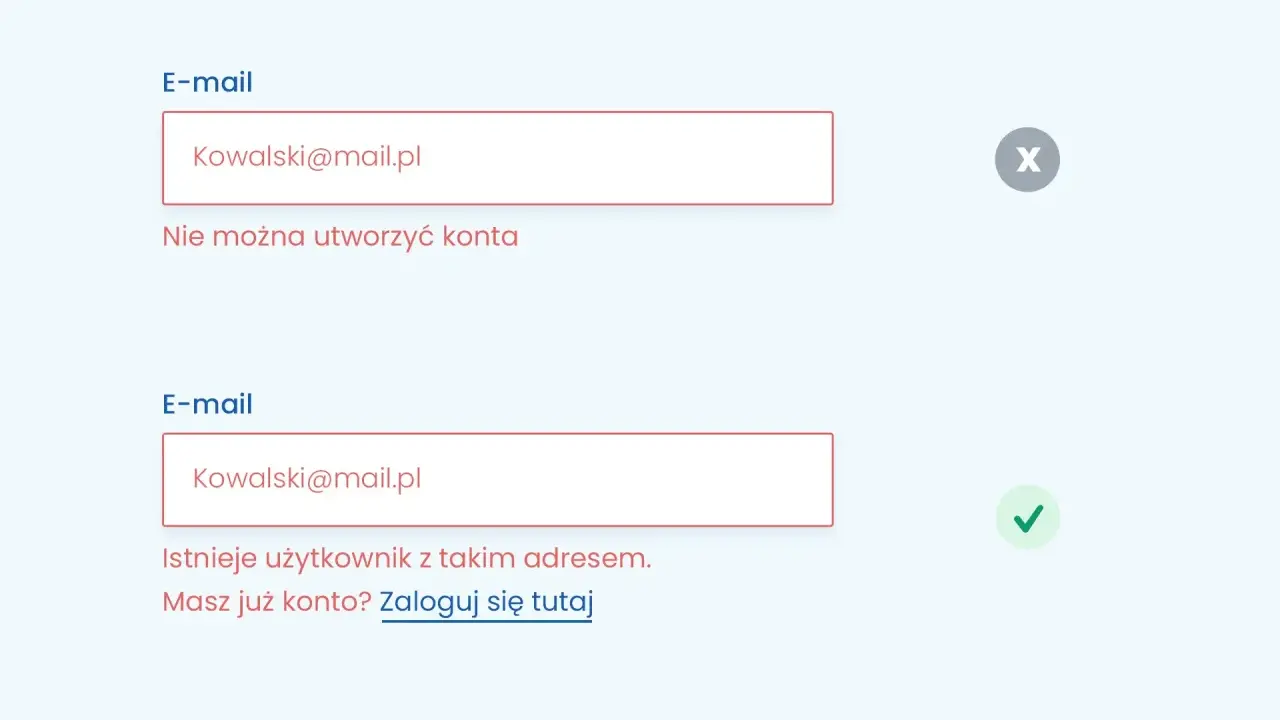
| Walidacja formularza | Które pole jest problemem i jaki format jest poprawny | Ogólne „niepoprawne dane” bez wskazania pola |
| Brak połączenia | Że operacja nie została zakończona i można spróbować ponownie | „Coś poszło nie tak” bez kontekstu |
| Brak uprawnień | Że dostęp jest ograniczony i co można zrobić zgodnie z procesem | Zbyt szczegółowy opis bezpieczeństwa lub wewnętrznych reguł |
| Błąd serwera | Że problem nie wynika z błędnego działania użytkownika | Przerzucanie winy na osobę korzystającą z systemu |
| Pusty stan po awarii danych | Co dokładnie się nie wczytało i czy odświeżenie ma sens | Brak wyjaśnienia, przez co ekran wygląda jakby działał poprawnie |
| Lokalizacja językowa | Tekst mieści się w układzie i brzmi naturalnie po polsku | Dosłowne tłumaczenie, które brzmi sztucznie albo się ucina |
Ten podział pomaga mi też w planowaniu testów regresyjnych. Jeśli wiem, że aplikacja ma kilka rodzin błędów, mogę łatwiej zbudować zestaw testów, który naprawdę pilnuje jakości, zamiast sprawdzać tylko jeden ogólny przypadek. To prowadzi do praktycznej części: jak taki przypadek testować krok po kroku.
Jak testować treść i zachowanie błędu krok po kroku
Najlepiej zaczynam od wymuszenia błędu w kontrolowanym środowisku. Nie testuję tylko tego, czy pojawia się czerwony baner. Sprawdzam cały efekt: tekst, miejsce wyświetlenia, zachowanie pól, możliwość ponowienia akcji, a także to, czy system nie traci danych po drodze.
- Wywołaj konkretny scenariusz negatywny, na przykład pusty formularz, przerwany request albo brak autoryzacji.
- Oceń treść: czy mówi, co się stało, bez żargonu i bez zbędnego dramatyzmu.
- Sprawdź, czy komunikat wskazuje następny krok, na przykład poprawę pola, odświeżenie widoku albo ponowną próbę.
- Zweryfikuj stan interfejsu: fokus, podświetlenie pola, blokadę przycisku, reset formularza lub zachowanie wpisanych danych.
- Przetestuj dostępność: czy czytnik ekranu odczytuje alert, czy kolejność tabulatora jest logiczna i czy kontrast jest czytelny.
- Sprawdź warianty: język interfejsu, urządzenie, przeglądarkę, tryb mobilny i tryb offline, jeśli ma to znaczenie dla produktu.
- Upewnij się, że zdarzenie trafia do logów lub monitoringu z sensownym identyfikatorem, ale bez wycieku danych wrażliwych.
W praktyce ważne jest też rozróżnienie między błędem, który użytkownik może naprawić sam, a takim, który wymaga wsparcia systemu. Jeśli obie sytuacje mają identyczny tekst, test z definicji jest niepełny. Po tej kontroli zostaje jeszcze jeden temat: jak to wszystko opisać w planie testów i zgłoszeniach, żeby zespół mógł z tego korzystać bez domysłów.
Jak włączyć takie przypadki do zarządzania testami
Tu pojawia się prawdziwa wartość dla QA. Sam test jednego alertu niczego nie domyka, jeśli nie da się go powtórzyć, porównać i śledzić w kolejnych wersjach. Dlatego w zarządzaniu testami zapisuję takie przypadki jak zwykłe, pełnoprawne scenariusze z jasnym powiązaniem do wymagania, defektu albo kryterium akceptacji.
| Element testu | Co zapisuję | Po co to robię |
|---|---|---|
| Scenariusz | Dokładny warunek wejścia i krok, który ma wywołać błąd | Żeby wynik dało się odtworzyć bez zgadywania |
| Dane testowe | Wartości poprawne, błędne i brzegowe | Żeby odróżnić problem danych od problemu logiki |
| Oczekiwany rezultat | Sens komunikatu, stan UI i akcja po błędzie | Żeby porównanie nie było uznaniowe |
| Kontekst techniczny | Przeglądarka, urządzenie, język, środowisko, kod zdarzenia | Żeby szybciej zrobić triage |
| Wpływ na proces | Czy błąd blokuje pracę, czy tylko ją utrudnia | Żeby ustawić właściwy priorytet |
| Powiązane testy regresyjne | Lista obszarów, które mogą się zepsuć przy poprawce | Żeby problem nie wrócił po kolejnej zmianie |
Warto też pilnować śledzenia zależności, czyli traceability. To po prostu powiązanie wymagania, testu i defektu w jeden czytelny łańcuch. Gdy go brakuje, zespół szybciej traci kontrolę nad tym, które komunikaty zostały zatwierdzone, które poprawione, a które wciąż czekają na dopracowanie. Z tego miejsca naturalnie przechodzę do pytania, kiedy krótszy i mniej szczegółowy tekst jest po prostu lepszy.
Kiedy prosty tekst działa lepiej niż rozwinięty opis
Nie każdy problem wymaga rozbudowanego wyjaśnienia. W wielu produktach lepiej sprawdza się krótki, spokojny komunikat niż długi akapit pełen technicznych tropów. To szczególnie ważne tam, gdzie użytkownik ma po prostu wykonać jedną akcję: poprawić pole, spróbować ponownie albo odświeżyć stronę.
Praktycznie rozdzielam tu kilka form prezentacji:
- inline przy konkretnym polu, gdy błąd dotyczy jednego fragmentu formularza,
- alert lub baner, gdy problem obejmuje szerszy obszar widoku,
- osobna strona błędu, gdy cały proces jest zablokowany,
- modal tylko wtedy, gdy użytkownik rzeczywiście musi podjąć decyzję, a nie gdy wystarczy informacja.
W tym miejscu przydaje się prosty filtr, który dobrze widać w publicznych design systemach: tekst ma być krótki, użyteczny i nieobwiniający użytkownika. Jeśli problem dotyczy bezpieczeństwa albo autoryzacji, z kolei lepiej ograniczyć szczegóły. Nie wszystko, co można napisać, trzeba pokazywać wprost. Dla testów oznacza to jedno: trzeba sprawdzić nie tylko to, co system mówi, ale też to, czego celowo nie mówi.
Co domykam przed wdrożeniem, żeby te błędy nie wracały w regresji
Przed wdrożeniem zwykle sprawdzam trzy rzeczy. Po pierwsze, czy każdy kluczowy stan awarii ma własny test i nie jest przykryty jednym ogólnym przypadkiem. Po drugie, czy treść jest spójna z innymi elementami interfejsu, szczególnie z etykietami pól, przyciskami i mikrocopy. Po trzecie, czy zespół ma jasne kryteria, kiedy błąd jest blokujący, a kiedy tylko obniża jakość doświadczenia.
Jeśli miałbym zostawić jedną praktyczną zasadę, byłaby prosta: testuj nie tylko obecność komunikatu, ale jego użyteczność. To właśnie tam najczęściej wychodzą rzeczy, które w repozytorium wyglądają dobrze, a w produkcie okazują się zbyt ogólne, zbyt techniczne albo po prostu mylące. Dobrze przeprowadzony test takiego elementu daje mniej chaosu w zespole i mniej frustracji po stronie użytkownika.
Własnie dlatego traktuję ten obszar jako stały fragment planu testów, a nie jednorazowy check na końcu sprintu. Jeśli komunikaty są sensowne, zespół szybciej rozumie awarie, a produkt wygląda na dojrzały nawet wtedy, gdy coś pójdzie nie tak.